Redis 캐싱 적용 → 성능이 얼마나 달라졌을까? + 직렬화 삽질 기록
- 게시글이 10 건일 땐 “캐시 있든 없든 그게 그거”
- 10 만 건으로 늘리자 평균 응답 -63 %, RPS +12 % 개선!
- 적용 과정에서 터졌던
LocalDateTime,LinkedHashMap,WRAPPER_ARRAY오류 해결법까지 정리했습니다.
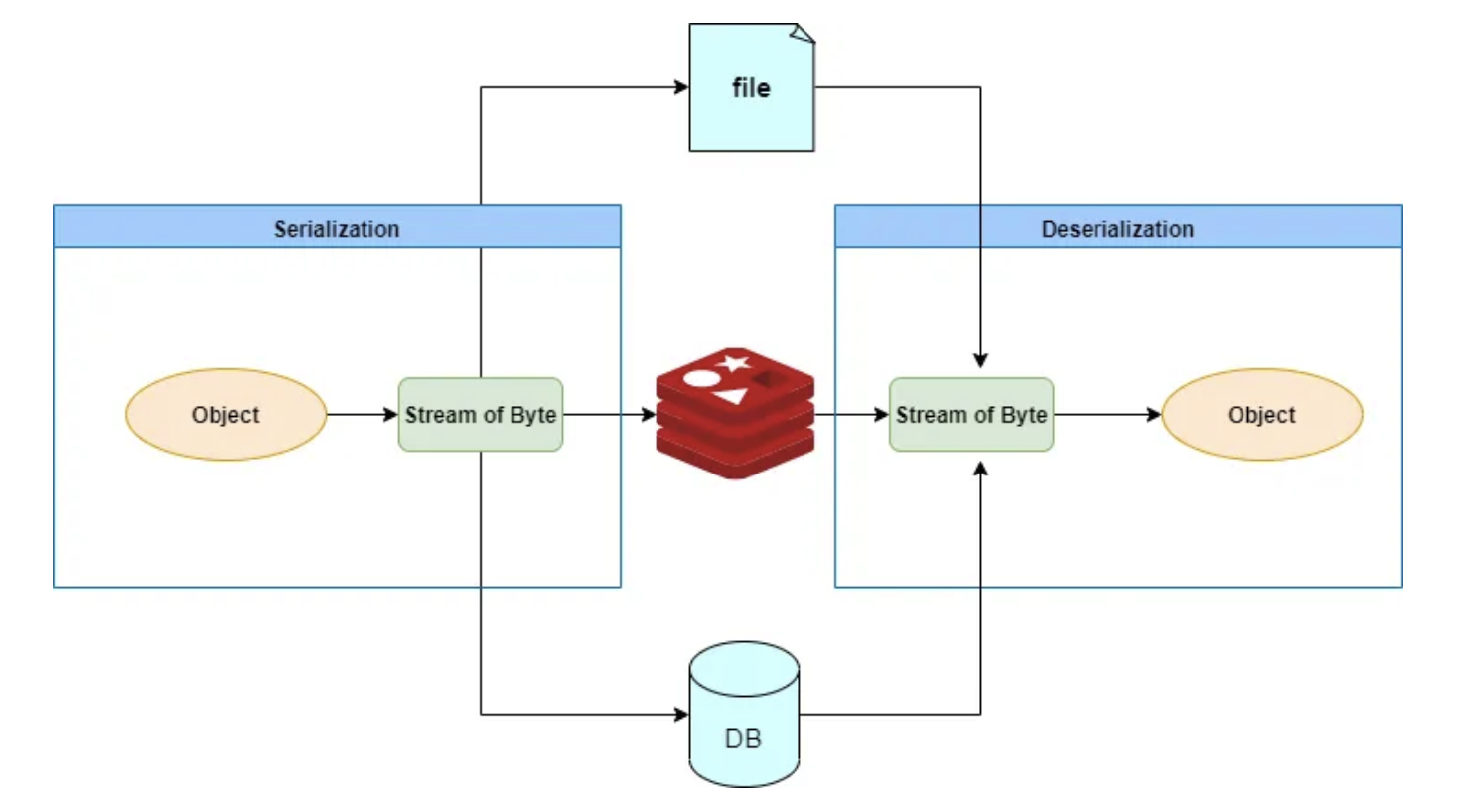
게시글은 특성상 생성 및 수정보다 조회가 더 빈번하다고 생각하여 캐싱을 통한 읽기 성능 최적화하기 적합한 도메인이라고 판단하였습니다.
이후 k6와 postman을 통한 테스트 결과와 캐싱 과정에서의 3가지 트러블 슈팅 과정을 이어서 작성하겠습니다.
캐싱 전/후 코드는 다음과 같습니다.
캐싱 전
public ArticleListResponse findAll(Pageable pageable) {
Page<Article> articles = articleQueryService.findAll(pageable);
List<ArticleResponse> response = articles.stream()
.map(ArticleResponse::from)
.toList();
return ArticleListResponse.from(response);
}캐싱 후
@Cacheable(value = "articles::all", key = "'p:' + #pageable.pageNumber + ':s:' + #pageable.pageSize")
public ArticleListResponse findAll(Pageable pageable) {
Page<Article> articles = articleQueryService.findAll(pageable);
List<ArticleResponse> response = articles.stream()
.map(ArticleResponse::from)
.toList();
return ArticleListResponse.from(response);
}Spring Cache Abstraction에서 제공하는 캐싱 저장 및 조회 어노테이션은 다음과 같습니다

이 중에서 캐시를 저장할 수 있는 기능을 제공하는 어노테이션은 @Cachable과 @Cacheput 입니다.
@Cacheable- '캐시가 존재하지 않을 경우' 캐시를 저장
- 캐시 존재시 메서드 호출 전 실행
- 캐시 미 존재시 메서드 호출 후 실행
@Cacheput- '캐시의 존재여부를 떠나서' 항상 새롭게 캐시를 저장
- 캐시 존재시 메서드 호출 후 실행
- 캐시 미 존재시 메서드 호출 후 실행
"메서드 호출 후" 실행의 의미는 db i/o 부하가 그만큼 더 많이 발생한다는 뜻입니다
따라서 캐시가 존재할 시 db read 작업을 줄일 수 있고, 간편하게 조회할 수 있는 @Cacheable을 사용하려고 합니다.
자세한 정보는 아래 공식 레퍼런스에서 확인할 수 있습니다.
Declarative Annotation-based Caching
데이터셋 설정
데이터셋 10개
게시글 초기 데이터셋을 insert 쿼리를 통해 10개정도만 넣었을때는 캐싱 전/후 근소한 차이만 존재하고,
눈에 띄는 차이는 확인할 수 없었습니다.
캐싱 전
캐싱 후
데이터셋 100,000개
표본이 부족하여 DB에서 읽어올때 비교적 빨리 찾을 수 있기 때문에 차이가 나지 않는것이라고 생각하였습니다.
따라서 데이터셋을 100,000개로 늘려서 테스트를 진행하였고, 아래에서 결과 지표를 분석해보겠습니다.
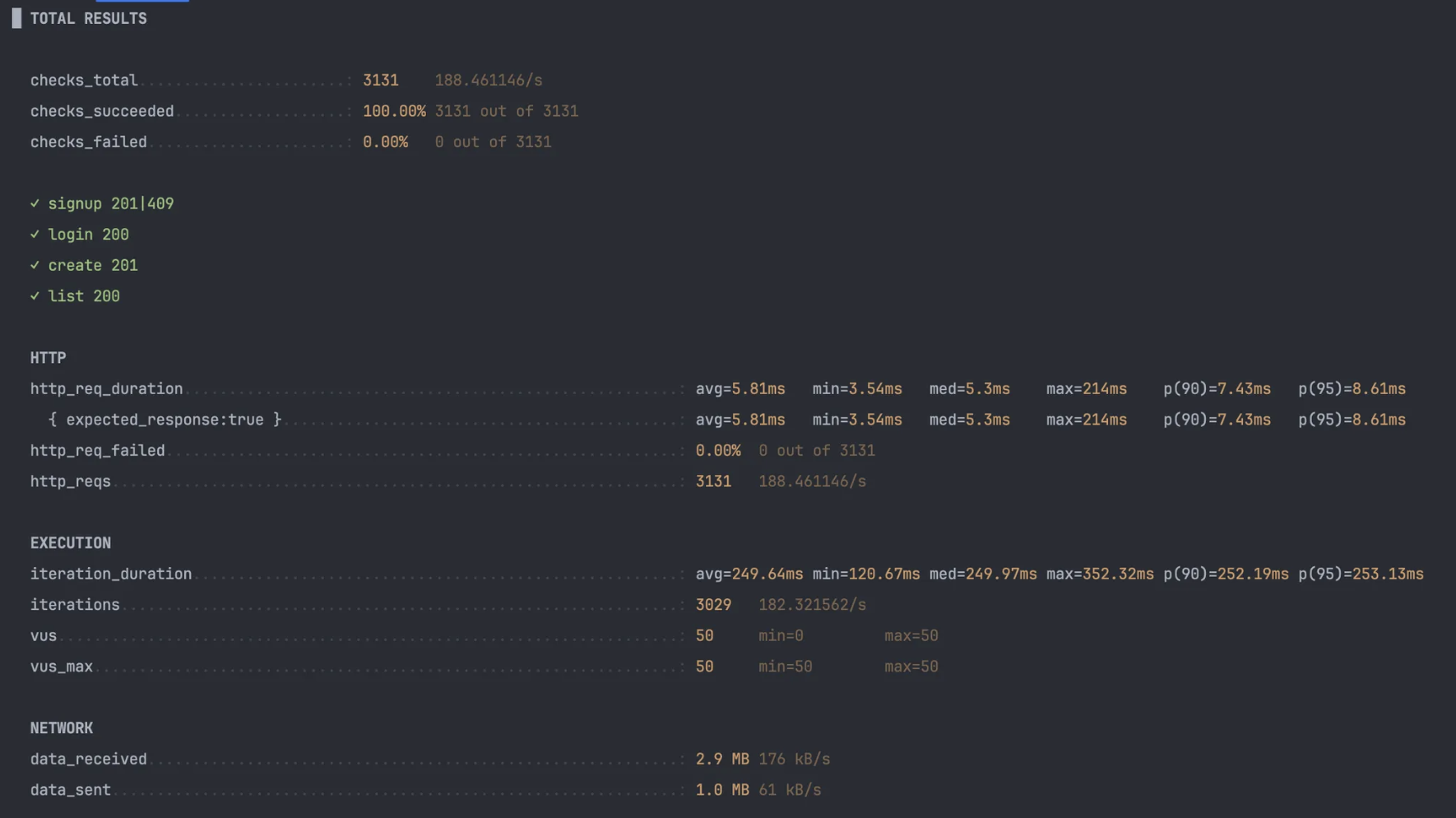
캐싱 전
초기 250ms
이후 반복 조회에도 평균 57ms 측정 확인
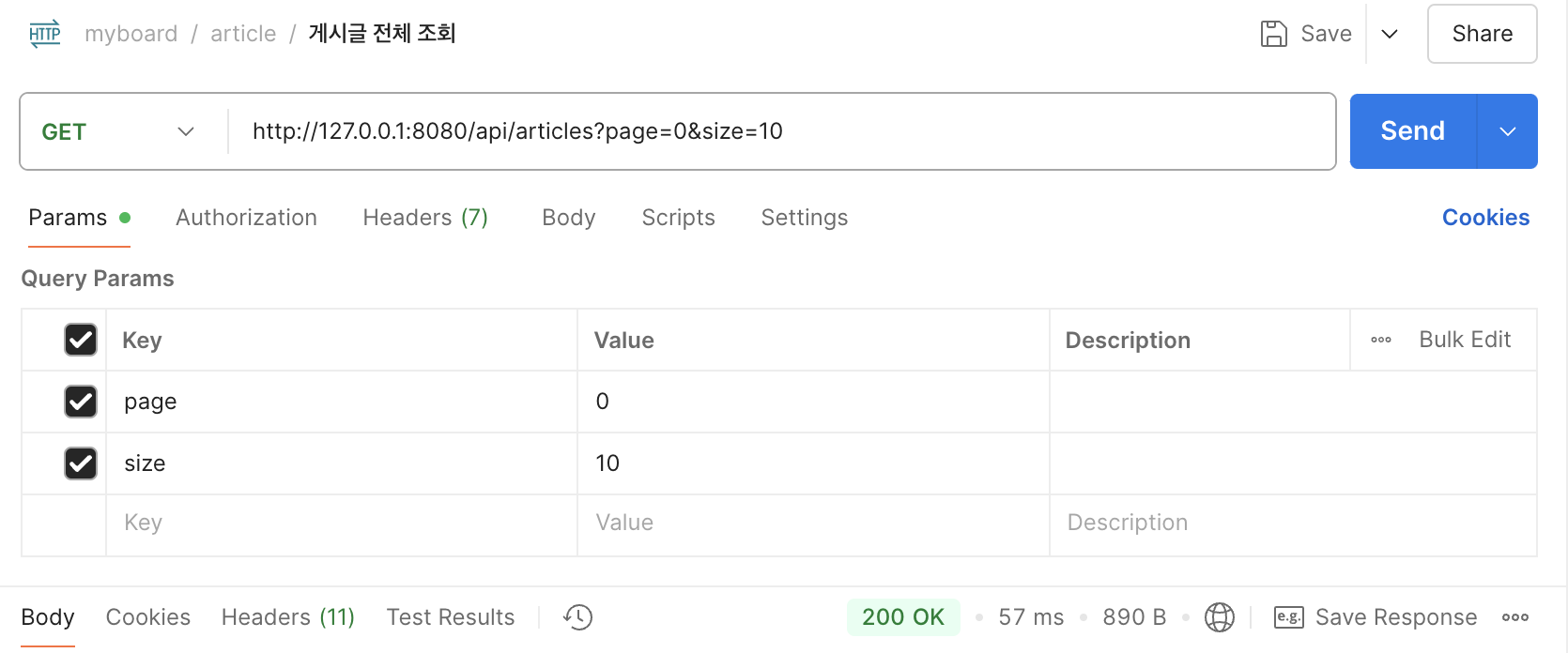
k6 테스트 결과
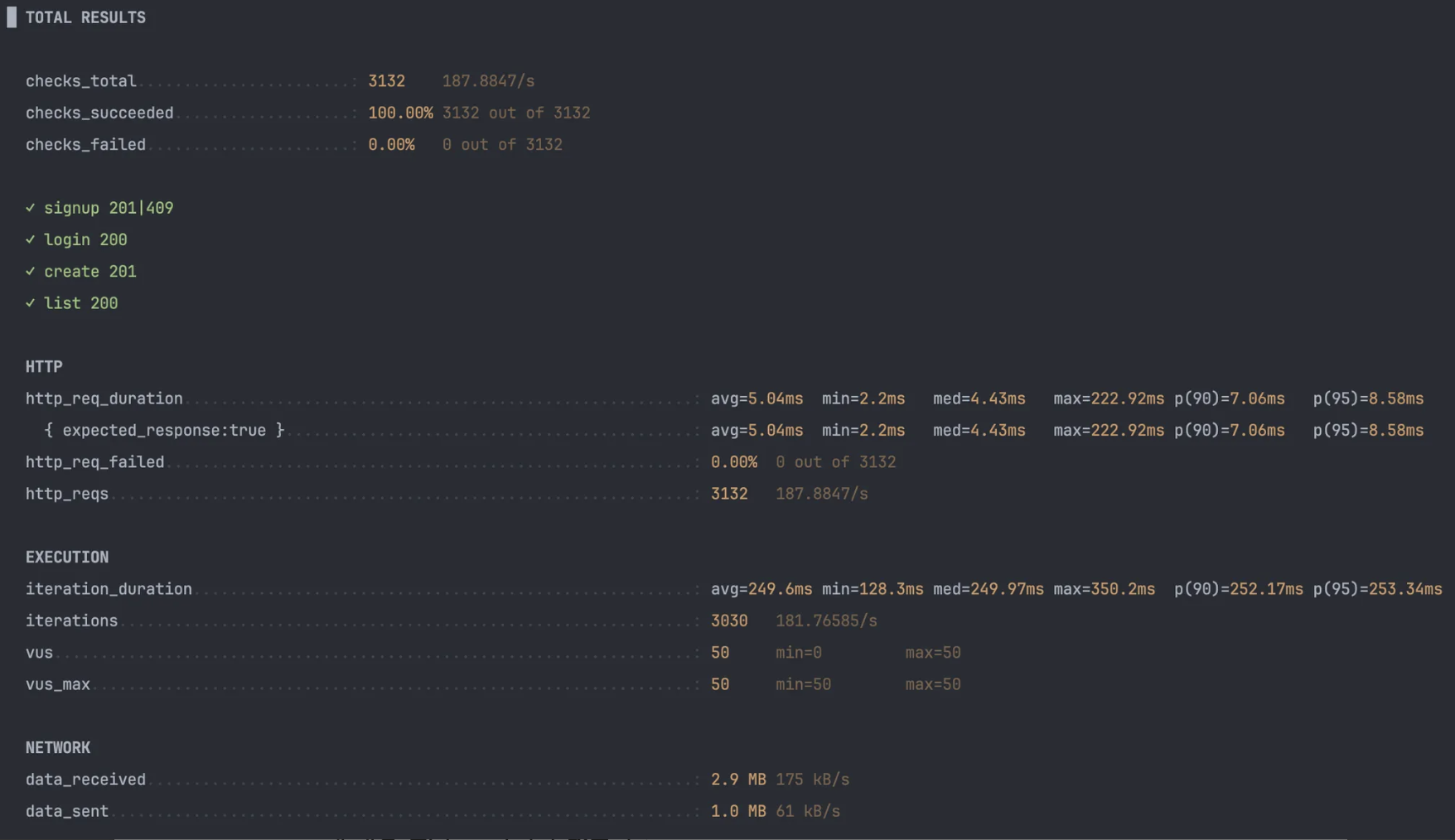
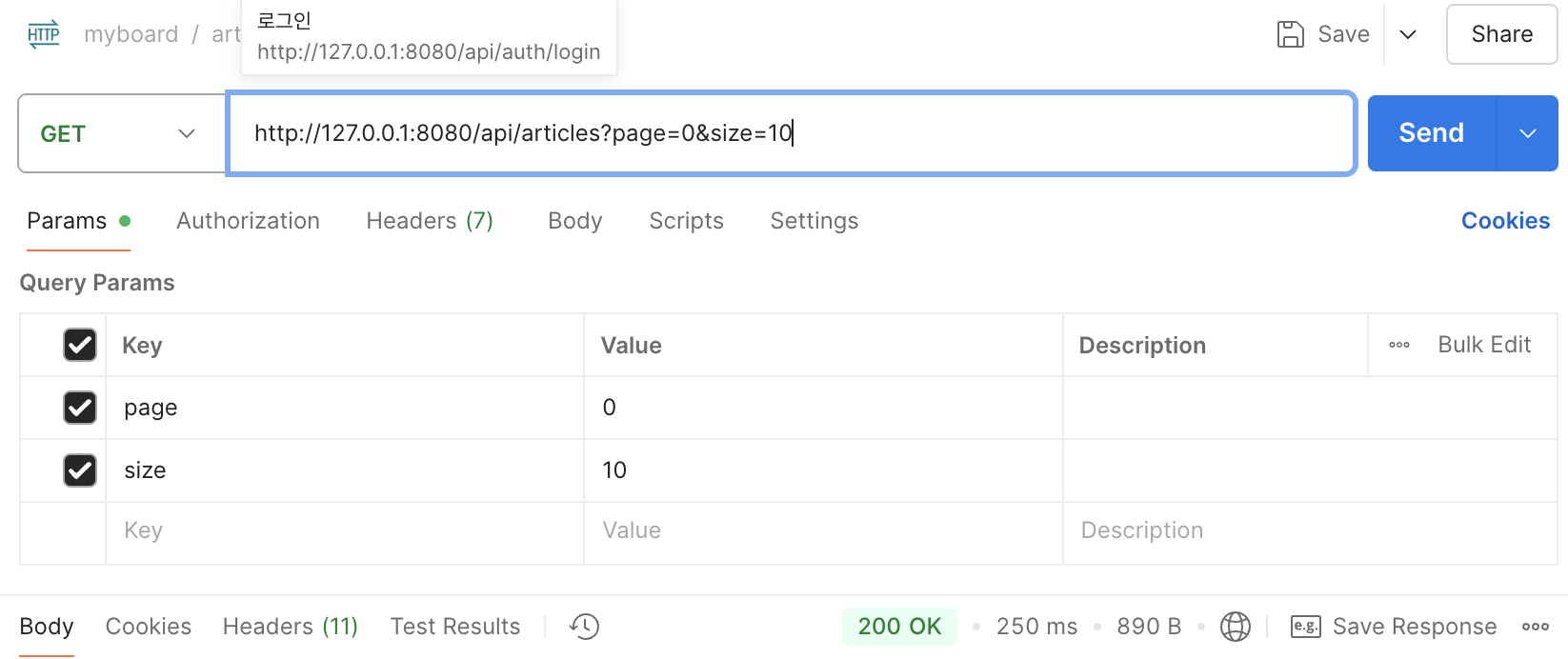
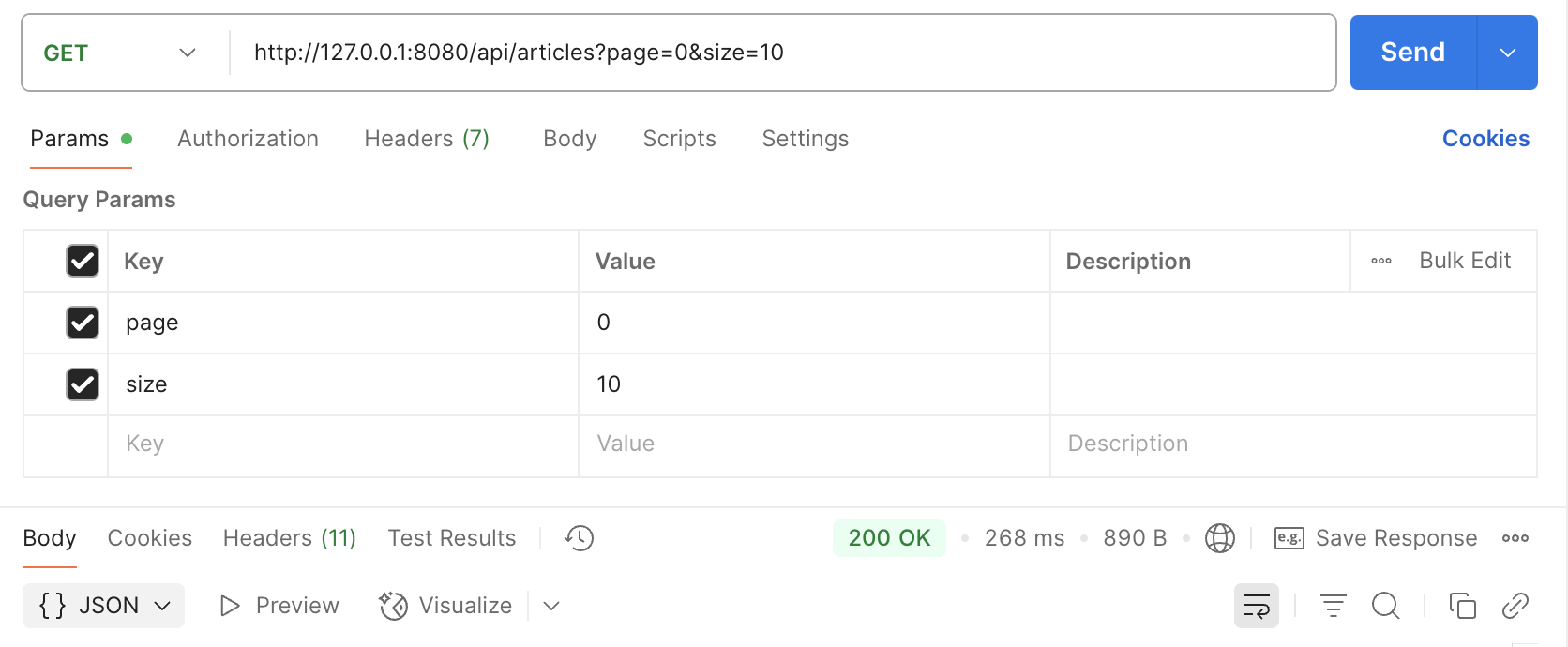
캐싱 후
초기에는 캐시미스로 인해 268ms 시간 발생 -> 캐싱 사용전(250ms)보다 많은 시간을 소요한 것을 확인할 수 있습니다.
cache miss로 인해 redis에 해당 데이터셋이 새롭게 적재되었고, 이후에는 cache hit를 기대할 수 있습니다.
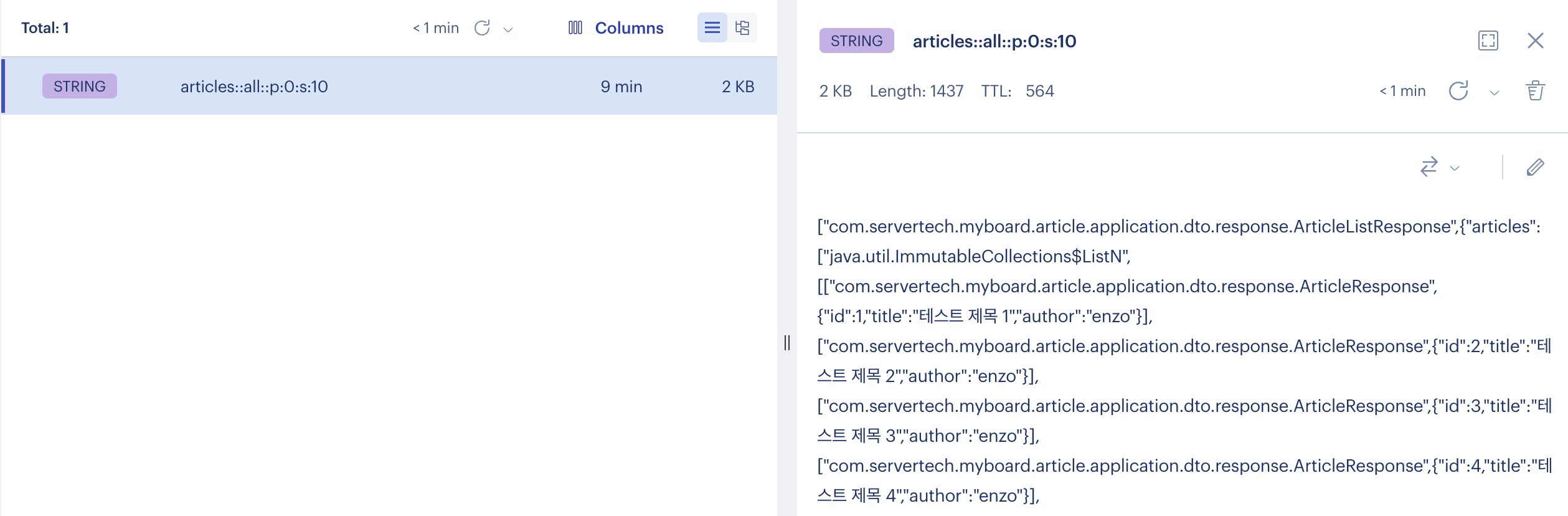
포스트맨으로 확인 -> 19ms로 캐싱 적용 전 (57ms) 보다 대폭 향상된 것을 확인하였습니다.
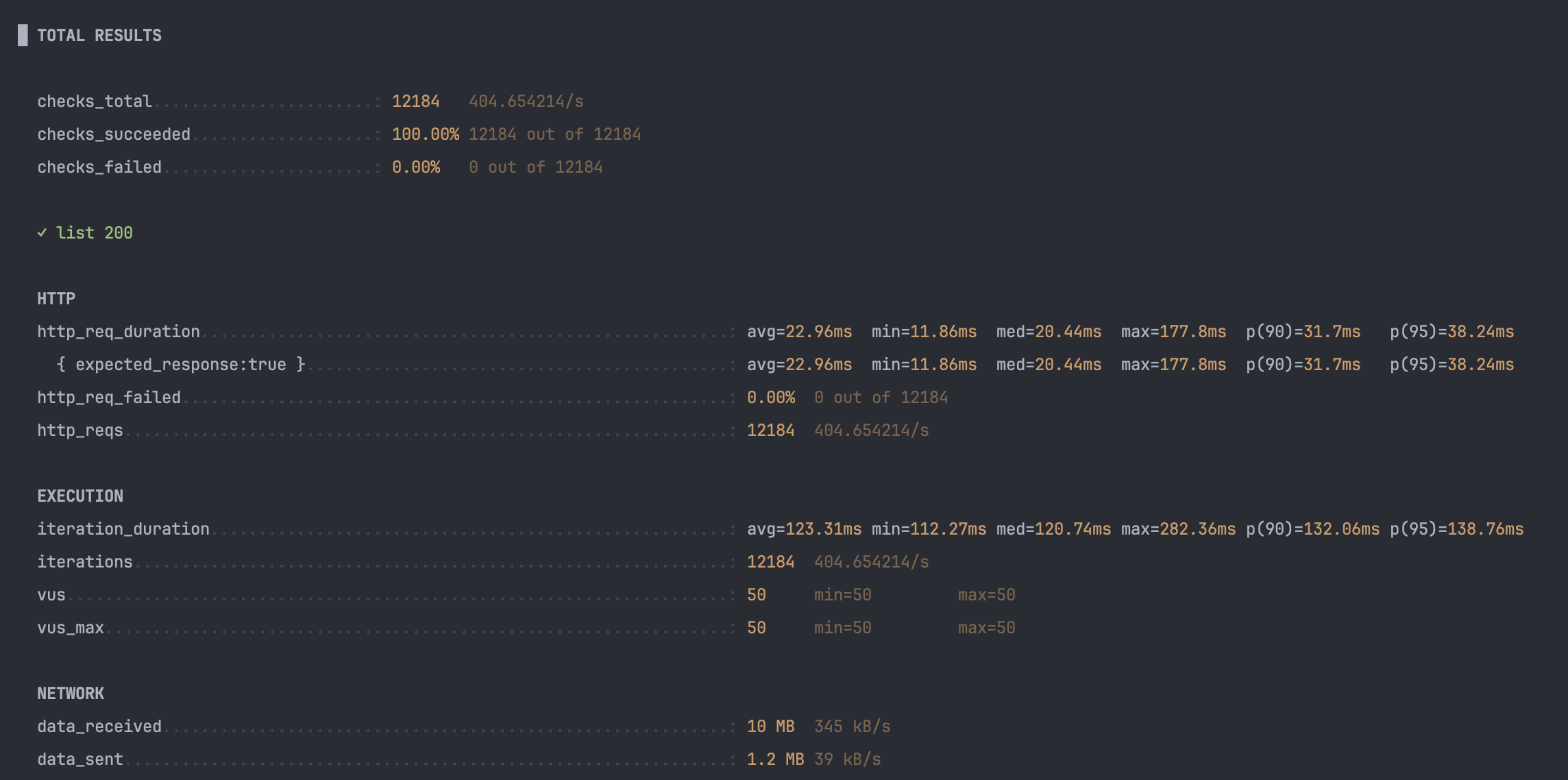
k6 테스트 결과
핵심 지표
-
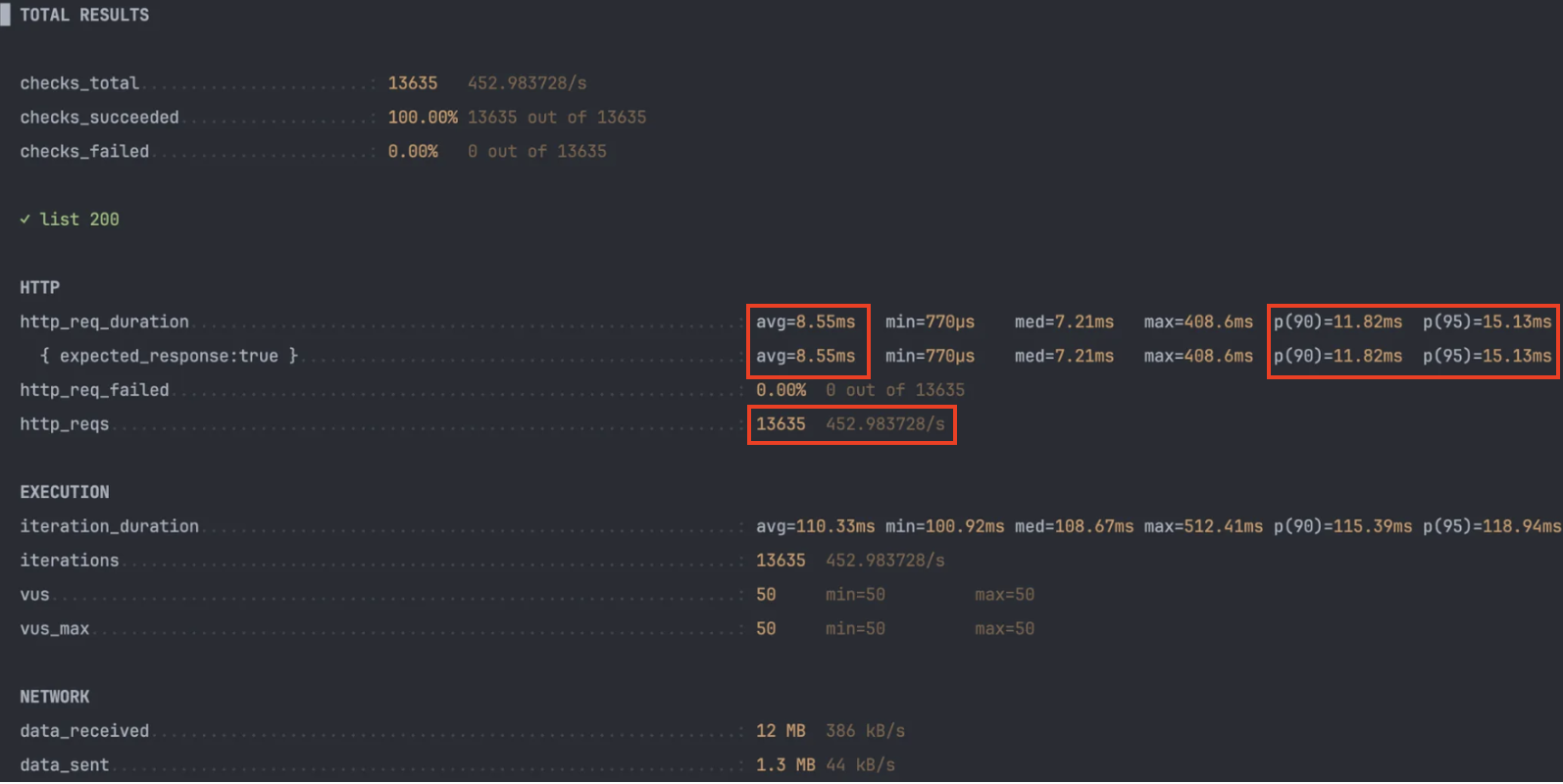
평균 지연 63 % 감소
- DB 조회 → Redis 메모리 히트로 전환되며 평균 22 ms → 8 ms.
- p90/p95도 30 ms대 → 10 ms대 초반으로 안정화 ⇒ 꼬리 지연 완화.
-
처리량(RPS) 12 % 증가
- 같은 50 VU에서도 Redis가 I/O 경합을 줄여 초당 50여 건 추가 처리.
-
iteration_duration감소폭이 작다- 스크립트에 think-time 0.1 s가 고정돼 있어, 응답이 빨라져도 루프 전체가 100 ms 이상을 소비.
- (실제 사용자 체감은
http_req_duration으로 판단한다고 합니다)
-
최대 지연치는 오히려 상승
- 캐싱 전 max ≈ 178 ms
- 캐싱 후 max ≈ 409 ms는 캐시 미스가 1 회 발생했음을 의미.
@Cacheable을 사용하여 캐시 조회/저장을 구현하였고, 해당 어노테이션의 특성은 다음과 같다- 캐시 존재시: 메서드 호출 전 실행
- 캐시 미존재시: 메서드 호출 후 실행
- 따라서 DB에서 데이터를 가져온 후, 캐시 서버에서 다시 조회하므로, 초기 조회시
@Caching사용 전 보다 후가 약간 더 지연되는것이라 추정됩니다.
- DB-hit→캐시 저장 구간이 존재하므로, 최악 지연을 줄이려면 cache-warming / TTL 전략 고려하여 추후 개선할 수 있을 것 같습니다.
이제.. @Cacheable을 적용하며 삽질했던 각종 에러들을 정리하려고합니다.
(사실 이제부터 포스팅의 핵심)
각종 트러블 슈팅 처리
LocalDateTime
🚨에러 로그
com.fasterxml.jackson.databind.exc.InvalidDefinitionException: Java 8 date/time type java.time.LocalDateTime is not supported by default. Add the module "com.fasterxml.jackson.datatype:jackson-datatype-jsr310" to enable handling.
문제 원인
스프링 데이터 Redis의 GenericJackson2JsonRedisSerializer는 내부적으로 Jackson의 기본 ObjectMapper를 사용합니다.
기본 ObjectMapper는 Java 8 날짜/시간 API(LocalDate, LocalDateTime 등)를 직렬화 및 역직렬화할 수 있는 모듈이 등록되어 있지 않아 오류가 발생합니다.
- 일반 Jackson: 스프링 부트 기본 설정에서
jackson-datatype-jsr310모듈이 자동 등록되어LocalDateTime을 바로 처리 - Generic Jackson: 별도의
ObjectMapper를 생성해야 하며, 커스텀 모듈 등록이 필요
해결 방법
ObjectMapper에 JavaTimeModule을 등록해주면 LocalDateTime 타입을 처리할 수 있습니다.
다음과 같이 RedisTemplate과 RedisCacheManager에 전달할 ObjectMapper를 직접 생성하였습니다.
- 일반 잭슨은 기본 오브젝트 매퍼를 통해 직렬화/역직렬화 자동
- 제너릭 잭슨시 오브젝터 매퍼 커스텀이 필요함
new GenericJackson2JsonRedisSerializer(objectMapper())
public ObjectMapper objectMapper() {
BasicPolymorphicTypeValidator ptv = BasicPolymorphicTypeValidator.builder()
.allowIfBaseType(Object.class)
.build();
return new ObjectMapper()
.registerModule(new JavaTimeModule())
.activateDefaultTyping(ptv, ObjectMapper.DefaultTyping.NON_FINAL);
}@Bean 을 사용하지 않은 이유는 Redis 직렬화와 스프링 캐시 부분만 따로 커스터마이징할 목적이라면, 굳이 글로벌 빈으로 등록할 필요 없이 위처럼 objectMapper()를 직접 호출해 사용하는 방법도 전혀 문제되지 않는다고 하여 Bean으로 등록하지 않았습니다.
LinkedHashMap
🚨에러 로그
java.lang.ClassCastException: class java.util.LinkedHashMap cannot be cast to class
문제 원인
Redis 캐시에서 꺼낸 JSON 데이터를 Jackson이 타입 정보를 알지 못한 채 역직렬화하면 기본적으로 LinkedHashMap 객체로 만들어집니다.
따라서 실제 DTO(ArticleResponse)로 바로 캐스팅하려 하면 ClassCastException이 발생합니다.
해결 방법
Jackson에 객체 타입 정보를 함께 저장 하도록 설정해야 합니다.
이를 위해 activateDefaultTyping(...)을 사용해 ObjectMapper에 폴리모픽 타입 정보를 포함시킵니다.
return new ObjectMapper()
.registerModule(new JavaTimeModule())
.activateDefaultTyping(ptv, ObjectMapper.DefaultTyping.NON_FINAL);이후 커스텀한 ObjectMapper를 직렬화에 사용하여, 다음과 같은 캐시 저장 정보를 받을 수 있었습니다.
["com.servertech.myboard.article.application.dto.response.ArticleListResponse",
{
"articles": [
"java.util.ImmutableCollections$ListN",
[
["com.servertech.myboard.article.application.dto.response.ArticleResponse",
{"id":1,"title":"게시글1","author":"tom"}
]
]
]
}
]-
첫 번째 요소(
com.servertech...ArticleListResponse)
→ 이 캐시 값이 원래 어떤 타입(클래스)인지 알려주는@class정보 역할을 합니다.
→ 직렬화 시점에activateDefaultTyping가 붙어 있으면, Jackson은JSON을 배열(WRAPPER_ARRAY)로 감싸고 첫번째 자리에 클래스 풀 경로를 넣어 줍니다. -
두 번째 요소(
{ "articles": [ … ] })
→ 실제ArticleListResponse객체의 필드들이 들어 있는 JSON 객체 부분입니다.
→ 키"articles"아래에는 또 내부 리스트가 포함되어 있습니다.
Redis에서 꺼낼 때 Jackson이 첫 번째 배열의 값을 보고 ArticleListResponse 타입으로 역직렬화할 수 있습니다.
아래는 실제 Redis에 저장된 key:value 값이고, @class정보가 앞에 붙어있는것을 알 수 있습니다.

게시글 추가 후 조회한 결과입니다.

articles 배열 안에 게시글 정보가 잘 추가된것을 확인할 수 있었고, Redis Insight를 통해 가시성 있게 JSON으로 인코딩하여 확인할 수 있었습니다.
AsWRAPPER_ARRAY
🚨에러 로그
expected START_ARRAY: need Array value to contain As.WRAPPER_ARRAY type information
문제 원인
record 형태의 DTO는 내부적으로 불변(immutable) 속성만 가지고 있고, Jackson의 기본 폴리모픽 타입 처리 방식(As.WRAPPER_ARRAY)과 충돌을 일으킵니다.
구체적으로, activateDefaultTyping(..., DefaultTyping.NON_FINAL)를 사용하면 Jackson이 객체 직렬화 시 다음과 같은 배열 래퍼(WRAPPER_ARRAY) 구조를 만들어냅니다
즉, 바로 위 에러 처리 상황에서 봤던것처럼,
- 첫째 요소에 클래스 이름
- 둘째 요소에 실제 필드
Java record는 Jackson이 이 배열 래퍼 구조를 예상대로 처리하지 못하여 START_ARRAY를 찾을 수 없다는 오류가 발생합니다.
해결 방법
문제를 해결하려면
- 배열 래퍼 방식 대신 객체형 포맷으로 폴리모픽 타입 정보를 직렬화
record대신 일반class를 쓰되 Jackson이 JSON -> 객체 매핑 시 필요한 생성자나 접근자를 확실히 제공
위 두 가지 방법이 있습니다.
우선 이번 해결 과정에서는 비교적 간단한 두 번째 방법으로 문제를 해결하였습니다.
기존 record로 생성한 ArticleResponse 입니다.
@Builder
public record ArticleResponse(
Long id,
String title,
String author
) implements Serializable {
public static ArticleResponse from(Article article) {
return ArticleResponse.builder()
.id(article.getId())
.title(article.getTitle())
.author(article.getAuthor())
.build();
}
}아래는 적절한 어노테이션을 사용한 ArticleResponse 입니다.
@Getter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class ArticleResponse implements Serializable {
private Long id;
private String title;
private String author;
public static ArticleResponse from(Article article) {
return ArticleResponse.builder()
.id(article.getId())
.title(article.getTitle())
.author(article.getAuthor())
.build();
}
}@NoArgsConstructor: Jackson이 리플렉션으로 객체를 생성할 때 반드시 필요한 기본 생성자를 만들어 줍니다.@Getter: 프로퍼티를 JSON으로 직렬화할 때 getter 메서드를 통해 접근할 수 있어야 합니다.@AllArgsConstructor+@Builder: 빌더 패턴을 그대로 유지하면서도 생성자 인젝션이 가능합니다.
이번 해결 과정에서는 단순히 record -> class 변환을 통해 해결하였지만,
다음에는 배열 래퍼 방식 대신 객체형 포맷으로 폴리모틱 타입 정보를 직렬화 하는 방법을 적용한 후 후기를 작성하겠습니다.
