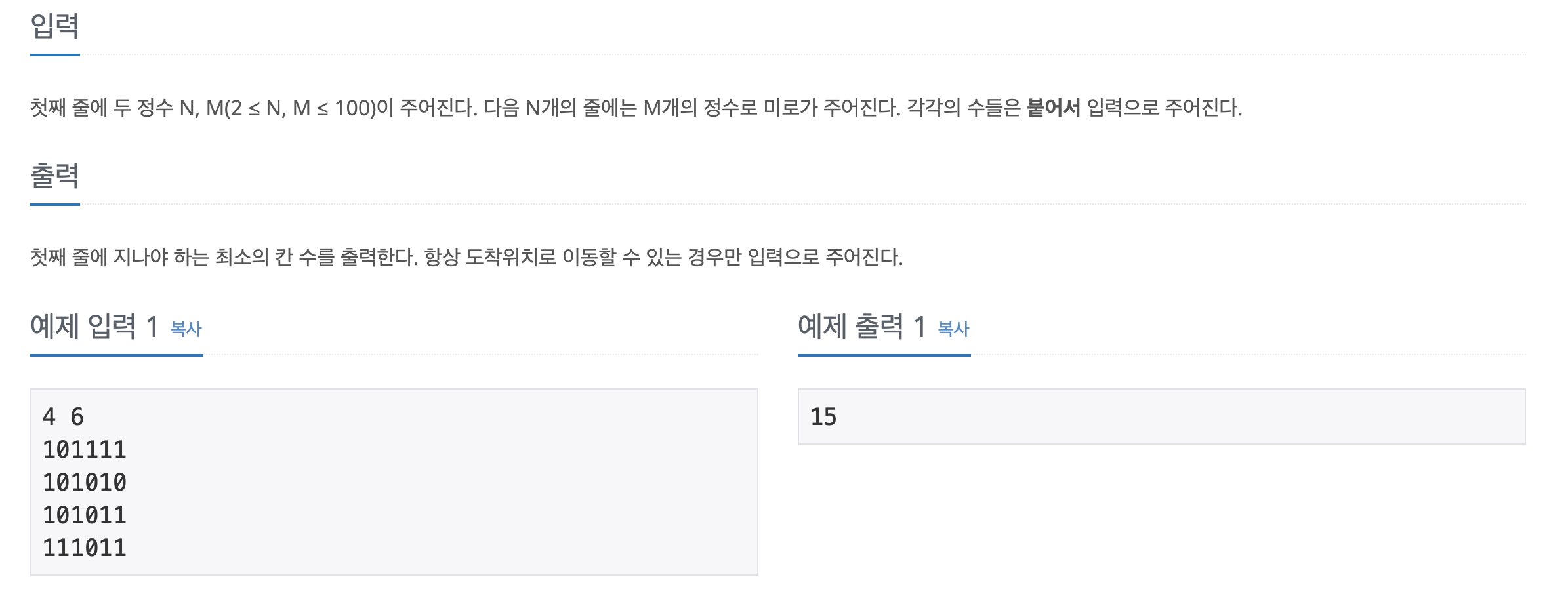
문제 및 입출력

풀이
그래프의 탐색을 사용하는 문제이다.
DFS를 사용하면 최단거리를 구할 수 없다는 느낌적인 느낌으로 바로 BFS로 구현하였다.
근데 당연히 다양한 길 중에서 최단거리를 구해야하므로 BFS 느낌이 오는게 맞다
돌아가는 엉뚱한 길로 빠졌는데 DFS를 계속 진행하고 있으면 안되니까...
static int map[][];
static int[] dx = {0, 1, 0, -1};
static int[] dy = {1, 0, -1, 0};
static boolean[][] visited;
static int N, M; 주변 상하좌우를 살피는 문제를 늘 풀던대로 방향벡터와 방문여부를 체크하는 배열을 선언해준다.
for (int i = 0; i < N; i++) {
String str = br.readLine();
for (int j = 0; j < M; j++) {
map[i][j] = str.charAt(j) - '0';
}
}
bfs(0, 0);
System.out.println(map[N - 1][M - 1]);늘 먹던대로... 한 줄을 입력받아 0과 1의 string을 interger 형식으로 변경하여 지도에 저장한다.
그리고 bfs를 초기 시작점인 (0,0)부터 진행해주면 끝 ! 인줄 알았는데
private static void bfs(int x, int y) {
Queue<int[]> queue = new LinkedList<>();
queue.add(new int[]{x, y});
while (!queue.isEmpty()) {
int[] current = queue.poll();
for (int i = 0; i < 4; i++) {
int nx = current[0] + dx[i];
int ny = current[1] + dy[i];
if(nx>=0 && ny >=0 && nx < N && ny < M
&& visited[nx][ny] == false && map[nx][ny] == 1) {
queue.add(new int[]{nx, ny});
visited[nx][ny] = true;
map[nx][ny] = map[current[0]][current[1]] + 1;
}
}
}
}생각보다 아이디어를 생각하는것이 어려웠다
현재 노드 기준으로 상하좌우를 탐색하여 값이 1인 노드를 큐에 저장해주고 큐가 비어있지 않으면 방문여부를 체크하며 계속 탐색을 진행한다... 이것은 늘 풀던 전형적인 bfs 패턴이라 이제 익숙하다.
코드를 하나씩 풀어보자
Queue<int[]> queue = new LinkedList<>();
queue.add(new int[]{x, y});- 값이 1인 원소의 인덱스를 큐에 저장해주기 위해 자료형이 정수형 배열인 큐를 선언해준다
queue.add(new int[]{nx, ny});
visited[nx][ny] = true;- 아직 방문하지 않았고, 값이 1인 원소의 인덱스를 큐에 저장한다
- 이 과정에서 방문여부를 true로 체크해준다.
(여기서 체크하지 않고, poll 할 때 여부를 true로 하면, 같은 인덱스가 큐에 중복저장 될 수 있기 때문이다 (아래 추가 설명))
(ex)
1(a) 1(b)
1(c) 1(d)
1. c를 poll 하고 방문여부를 true, 주변을 탐색해 a,d를 큐에 담는다
2. a를 poll 하고 방문여부를 true, 주변을 탐색해 b를 큐에 담는다
3. d를 poll 하고 방문여부를 true, 주변을 탐색해 b를 큐에 담는다
이 과정에서 b를 큐에 두 번 담게 되므로, 주변을 탐색한 후 방문여부를 true로 하는것이 과정상 편할 것 같다
map[nx][ny] = map[current[0]][current[1]] + 1;
이 코드가 문제의 핵심코드이다.
탐색을 할 때 현재 가중치를 어떻게 저장하고, 비교해야 하는지 고민이 많아서 문제를 풀 지 못했다.
상하좌우를 탐색하여 방문하지 않았고, 원소값이 1인 노드의 인덱스를 큐에 저장할 때, 해당 인덱스의 map[][] 값을 이전 인덱스 원소의 값보다 +1 해주면 된다..
최종 코드
public class Main {
static int map[][];
static int[] dx = {0, 1, 0, -1};
static int[] dy = {1, 0, -1, 0};
static boolean[][] visited;
static int N, M;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
N = Integer.parseInt(st.nextToken()); // 가로 길이
M = Integer.parseInt(st.nextToken()); // 세로 길이
map = new int[N][M];
visited = new boolean[N][M];
for (int i = 0; i < N; i++) {
String str = br.readLine();
for (int j = 0; j < M; j++) {
map[i][j] = str.charAt(j) - '0';
}
}
bfs(0, 0);
System.out.println(map[N - 1][M - 1]);
}
private static void bfs(int x, int y) {
Queue<int[]> queue = new LinkedList<>();
queue.add(new int[]{x, y});
while (!queue.isEmpty()) {
int[] current = queue.poll();
for (int i = 0; i < 4; i++) {
int nx = current[0] + dx[i];
int ny = current[1] + dy[i];
if(nx>=0 && ny >=0 && nx < N && ny < M
&& visited[nx][ny] == false && map[nx][ny] == 1) {
queue.add(new int[]{nx, ny});
visited[nx][ny] = true;
map[nx][ny] = map[current[0]][current[1]] + 1;
}
}
}
}
}풀이 후기
핵심은 가중치를 기억하며 누적시켜 탐색을 하는것인데,
기억하며 라는 키워드는 이전에 dp유형을 찍먹했을때 들었던 키워드이다.
이후에 dp를 다시 제대로 공부할 때, 이 문제를 dp로 바꿔서 풀어봐야겠다
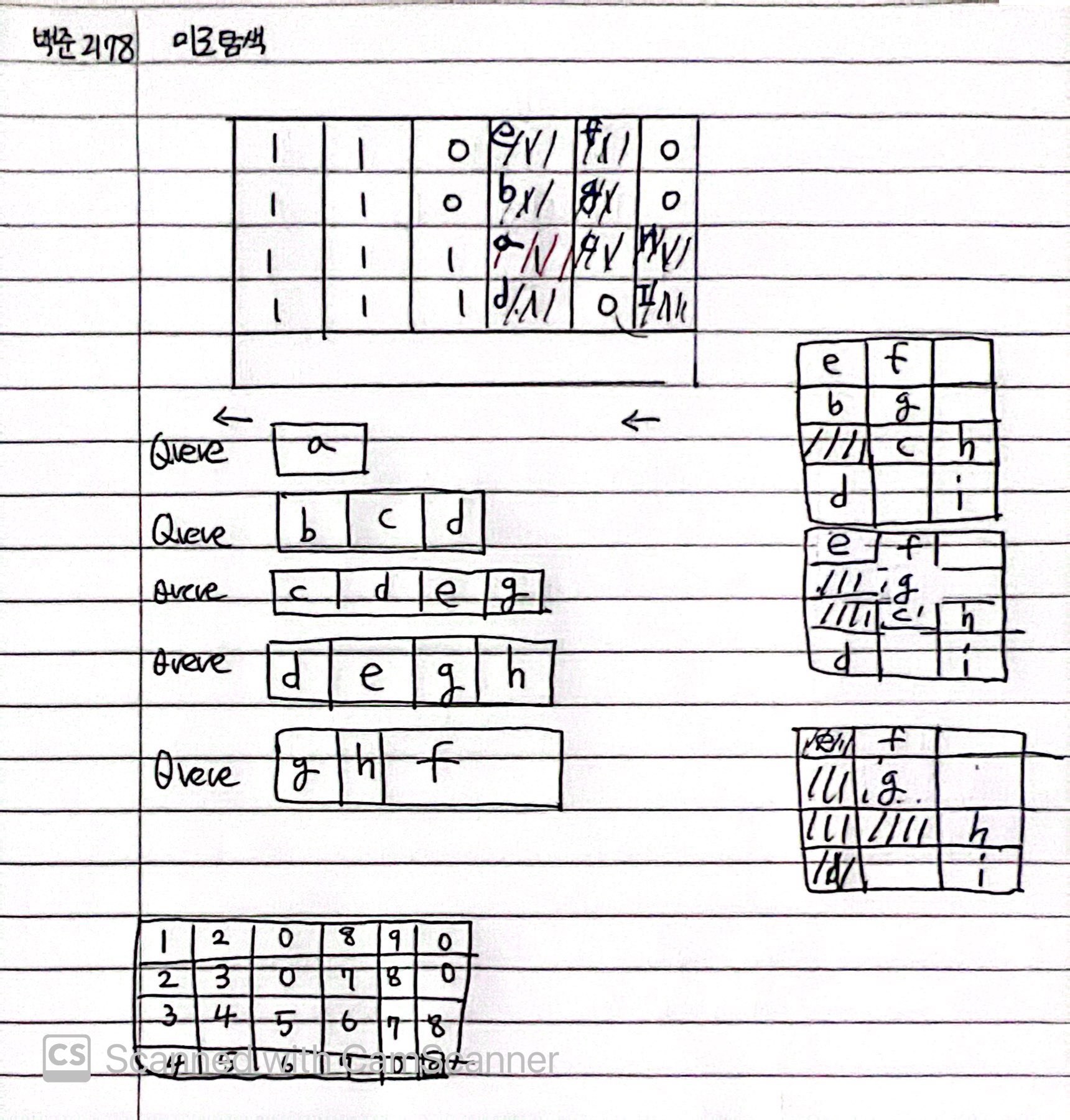
감각으로 파악했던 왜 dfs 가 아닌 bfs를 써야하는지 이유를 알아보기 위해 끄적인 것
