하지만 여전히 아래와 같은 성능 저하가 발생한다
Using temporary; Using filesort- 정렬 사용
DEPENDENT SUBQUERY- 서브 쿼리는 독립적으로 실행될 수 없고, 외부(메인 쿼리)에서 id 값을 받아야만 실행
이전 포스팅에 이어서
우선, Using filesort는 랜덤 추천(ORDER BY RAND())이라는 비즈니스 로직을 유지하는 한 당장 인덱스만으로 제거하기 까다롭다고 생각한다. 따라서 정렬 최적화는 뒤로 미루고, 시스템을 마비시킬 수 있는 구조적 결함인 상관 서브쿼리 문제를 먼저 개선하고자 한다.
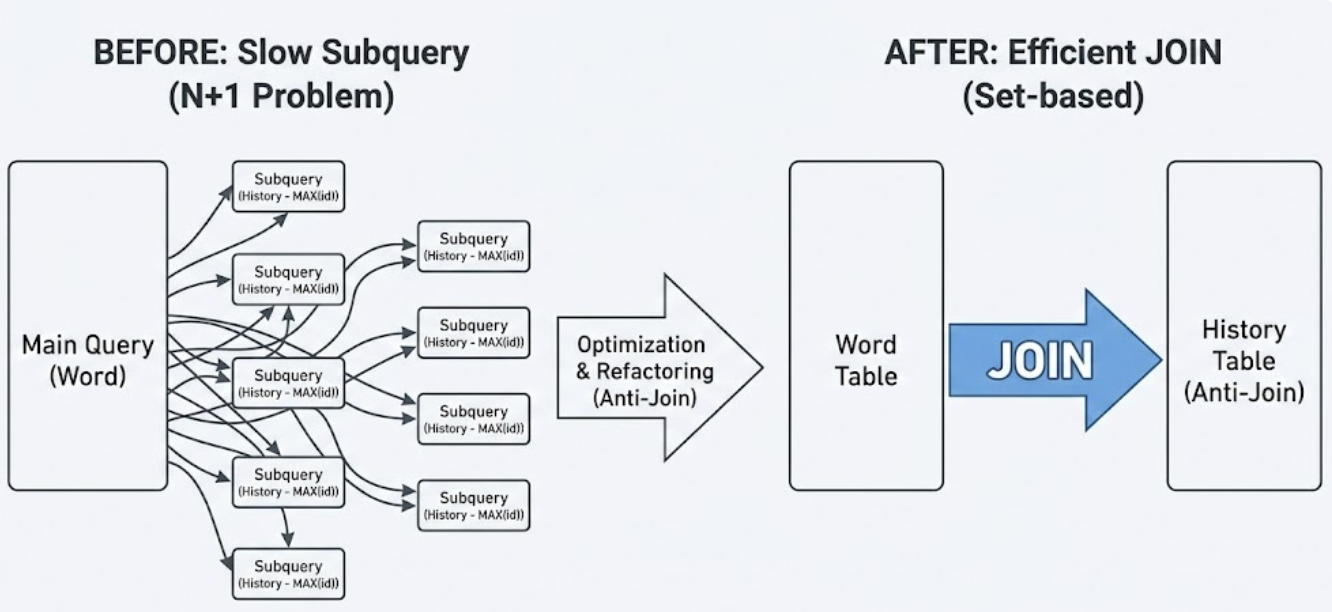
현재 상관 서브쿼리의 작동 방식은 다음과 같다.
- 메인 쿼리(id=1)가 Word 테이블에서 단어 1개를 가져온다
- 이 단어를 가지고 해당 단어의 기록을 찾기 위한 서브쿼리를 실행한다
- 메인 쿼리가 다음 단어 1개를 가져온다.
- 해당 단어의 기록을 찾기 위한 서브쿼리를 실행한다.
- 이 단계를 단어의 개수만큼 반복한다. (10,000 번)
EXPLAIN ANALYZE 를 통해 쿼리 실행 시간을 정밀하게 분석해 보았다.
EXPLAIN ANALYZE
SELECT w1_0.id
FROM word w1_0
LEFT JOIN word_learning_history wlh1_0
ON wlh1_0.word_id = w1_0.id AND wlh1_0.user_id = 1
WHERE
wlh1_0.id IS NULL
OR (
wlh1_0.id = (
SELECT MAX(wlh2_0.id)
FROM word_learning_history wlh2_0
WHERE wlh2_0.word_id = w1_0.id AND wlh2_0.user_id = 1
)
AND wlh1_0.result = 'WRONG'
)
LIMIT 10;
결과를 보면 loops 수가 52회에 불과하고, 전체 실행 속도 또한 1.34ms로 매우 빠르다. 서브쿼리로 인한 N+1 문제가 발생했음에도 왜 이렇게 빠를까?
실행 계획을 분석해 보면 이는 Early Termination (탐색 조기 종료) 덕분임을 알 수 있다.
Covering index scan on w1_0 항목을 보면 DB는 총 9,545개(rows=9545)의 단어를 읽을 준비를 했지만 실제로 스캔한 단어는 단 26개(actual ... rows=26)뿐이었다. 현재 테스트 데이터에는 아직 학습하지 않거나(NULL) 틀린(WRONG) 단어가 앞부분에 많아서, DB가 단어를 고작 26개만 스캔하고도 빠르게 LIMIT 10 조건을 채운 뒤 탐색을 멈춰버린 최선의 경우였던 것이다.
그렇다면 최악의 경우는 어떨까?
사용자가 아주 공부를 열심히 해서 10,000개의 단어 중 9,990개를 다 맞춘 상황을 가정해 보자.
DB는 조건에 맞는(틀린 단어) 10개의 단어를 찾기 위해, 1만 개의 단어를 하나씩 꺼낼 때마다 "이 단어 최근에 틀렸어?"라고 묻는 서브쿼리를 1만 번 실행하게 될 것이다.
이 잠재적인 폭탄을 눈으로 확인하기 위해, 쿼리에 의도적으로 OFFSET 5000 조건을 부여하여 실행 계획을 다시 확인해 보았다. OFFSET 5000을 주면 DB는 유효한 데이터 5,000개를 건너뛰어야 하므로, 조기 종료를 하지 못하고 무수한 단어들에 대해 강제로 서브쿼리를 실행하게 된다.

예상대로였다. 조기 종료가 불가능해진 DB는 9,930개(actual ... rows=9930)의 단어를 스캔하며 테이블의 끝까지 뒤져야 했고, 그 결과 총 실행 시간이 1.34ms에서 116ms로 대폭 상승했다. 무엇보다 서브 쿼리 실행 횟수(loops)가 52회에서 24,828회로 약 400배 폭증하며, 서브쿼리로 인한 구조적 결함이 데이터 규모에 따라 얼마나 치명적으로 변할 수 있는지 확인했다.
조기 종료는 어떻게 알 수 있을까?
EXPLAIN ANALYZE 결과의 실제 스캔 행(actual rows)과 루프(loops) 횟수를 보면 명확하다.
LIMIT 10 쿼리에서는 전체 1만 개의 단어 중 고작 26개(rows=26)만 스캔했고, 서브쿼리 역시 52번(loops=52)만 실행되었다. 조건에 맞는 10개를 찾자마자 탐색을 멈췄기 때문이다.
반면 OFFSET 5000을 부여하여 유효 데이터 5천 개를 건너뛰게 만들자, DB는 조기 종료를 하지 못했다. 그 결과 1만 개의 단어 테이블을 거의 끝까지 스캔(rows=9930)해야 했고, 서브쿼리 루프는 24,828번이나 돌며 서버 리소스를 낭비하는 끔찍한 결과를 보여주었다.
문제점을 확인했으니 이제 개선해보자
목표는 사용자별 각 단어의 최신 기록을 가져올때, DEPENDENT SUBQUERY를 사용하지 않게 쿼리 튜닝을 진행해야한다.
그렇다면 서브쿼리 없이 '가장 최신 기록'을 어떻게 찾을 수 있을까?
서브쿼리를 안티조인(셀프조인)으로 변경하였다.
SELECT w1_0.id
FROM word w1_0
LEFT JOIN word_learning_history wlh1_0
ON wlh1_0.word_id = w1_0.id AND wlh1_0.user_id = 1
-- 나보다 ID가 큰(최신인) 기록이 존재하는지 자기 자신과 한번 더 조인 (wlh2_0)
LEFT JOIN word_learning_history wlh2_0
ON wlh2_0.word_id = w1_0.id
AND wlh2_0.user_id = 1
AND wlh1_0.id < wlh2_0.id
WHERE
-- 나보다 더 최신 기록이 '없는(NULL)' 데이터만 남긴다 = wlh1_0이 최신 기록
wlh2_0.id IS NULL
AND (wlh1_0.id IS NULL OR wlh1_0.result = 'WRONG')
LIMIT 10 OFFSET 5000;이 쿼리의 실행 계획을 통해 변화를 확인해보았다.
- 서브쿼리 사용

- 조인 사용

DEPENDENT SUBQUERY가 완전히 사라지고 모든 조회가SIMPLE로 변경되었다.- MySQL 옵티마이저가
LEFT JOIN ... IS NULL패턴을 인식하여 Not exists 최적화(조건을 만족하면 조기 종료)를 적용하였다.filtered값이 100 -> 10 으로 변경되었다.
세 가지 변경 사항에 대한 이유를 파악해보자.
-
DEPENDENT SUBQUERY->SIMPLE
절차적 쿼리에서 집합적 처리로의 전환 -
Not exists최적화
전체 탐색에서 조기 종료로 전환 -
filtered값 100 -> 10
데이터 필터링 효율 극대화
이전에 확인했던 최악의 상황에서 EXPLAIN ANALYZE 를 통해 결과를 확인해보자.
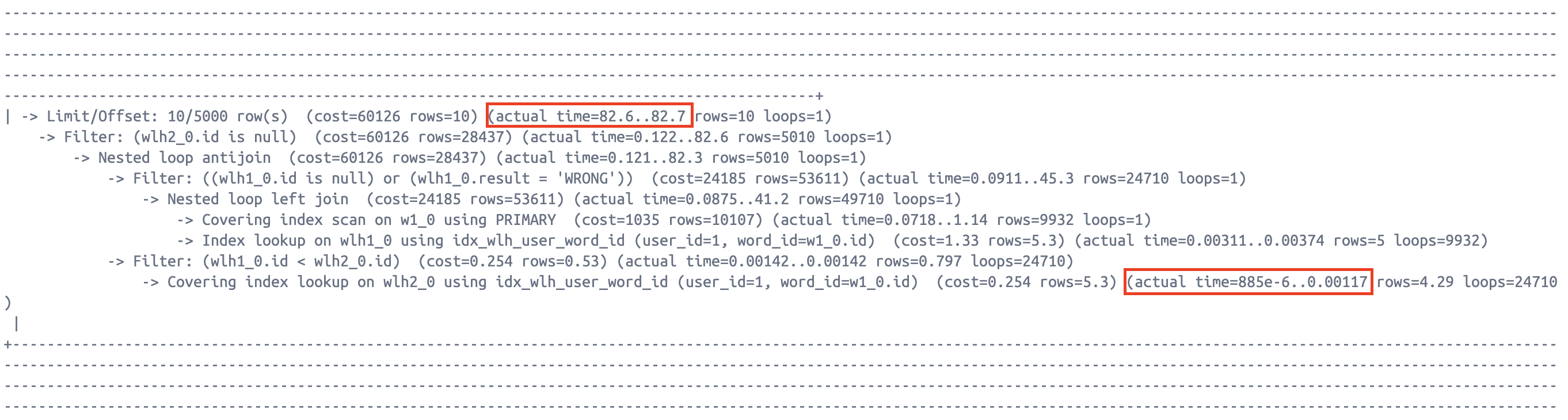
EXPLAIN ANALYZE 결과를 자세히 보면 wlh2_0 인덱스 룩업 과정에서 loops=24710이 발생한 것을 볼 수 있다. 이전 서브쿼리 방식(loops=24828)과 횟수가 비슷한데, 과연 성능이 개선된 것일까?
아래와 같은 지표들을 근거로, 루프의 질이 경량화 되었다고 생각한다.
- 전체 실행 시간
- 서브쿼리 방식:
actual time=104..105(약 105ms) - 안티 조인 방식:
actual time=82.6..82.7(약 82.7ms) - 약 21% 더 빠른 속도를 기록
- 루프 내부 연산 방식의 차이
- 두 방식 모두 유효 데이터를 찾기 위한 루프 수는 약 2만 4천번으로 유사
- 하지만 루프마다 연산하는 시간이 다름
- 서브쿼리:
actual time = 0.0014 .. 0.00178 - 셀프조인:
actual time = 885e-6 .. 0.00117(0.000885ms ~ 0.00117ms)
이전의 DEPENDENT SUBQUERY 루프는 매번 새로운 서브쿼리를 실행하고 MAX() 집계 함수를 연산해야 하는 무거운 작업이었다. 반면 조인으로 바꾼 현재의 루프는 Nested Loop Join 파이프라인 안에서 이미 메모리에 올라온 데이터를 가지고 인덱스만 빠르게 조회할 수 있게 되었다.
결과적으로 메인 쿼리에 의해서 반복하는 루프수는 동일하지만, 각 루프의 실행 시간이 경량화되어 최종적으로 조회 성능을 21% 향상시킬 수 있었던 것이다.
블로그를 다 작성하고보니, 서브쿼리의 조기종료를 위해서라면 exists를 활용할 수도 있다는 생각이 들었다. .. .
상관 서브쿼리에 exists 사용 vs 셀프 조인 사용
다음 포스팅은 이 두 결과를 비교하여 더 최적화된것이 무엇인지 확인해 볼 예정이다.

filtered 값 100 -> 10 데이터 필터링 효율 극대화 : 이 부분에 궁금한 점이 있습니다!
제가 생각하기론 필터의 값이 높다 = rows 대비 매칭율이 높다는 것인데, filtered의 값이 100에서 10으로 줄었다는 것은 매칭율이 하락했다는 의미이지 않을까요?
서브쿼리를 통해 걸러진 값을 메인 쿼리에 넣는다고 했을 때 filtered의 값이 100이었던 까닭은 메인쿼리가 필요로하는 컬럼을 서브쿼리에서 필터링해준 덕이고, 조인을 진행함으로써 filtered의 값이 줄어든 이유는 조인 단계에서 인덱스를통해 불필요한 데이터를 배제하여 그만큼 filtered의 값도 줄어든게 아닐까 싶습니다.
그래서 데이터 필터링 효율 극대화라는 표현 보다는 정상화..?가 좀 더 적절하지 않나 라는 생각이 드는 것 같습니다!