
배경 및 문제 상황
현재 개발 중인 MailVoca 서비스에는 사용자별 학습 기록을 분석하여 단어를 추천해 주는 기능이 있다. 추천 로직의 우선순위는 다음과 같다.
- 틀린 단어: 사용자가 학습했으나 틀린 기록이 있는 단어
- 학습하지 않은 단어: 아직 학습 기록이 없는 단어
- 맞춘 단어: 추천 제외
초기 개발 단계에서는 빠른 구현을 위해 JPA의 findAll()을 사용하여 모든 단어와 기록을 애플리케이션 메모리로 로딩한 후, Java Stream을 이용해 필터링하는 방식을 사용하였다.
하지만 데이터가 적을 때는 문제가 없었으나, 더미 데이터(단어 1만 건, 학습 기록 5만 건)를 적재하고 부하 테스트를 진행하자 병목 현상이 발생하였다.
AS-IS 성능 측정 및 원인 분석
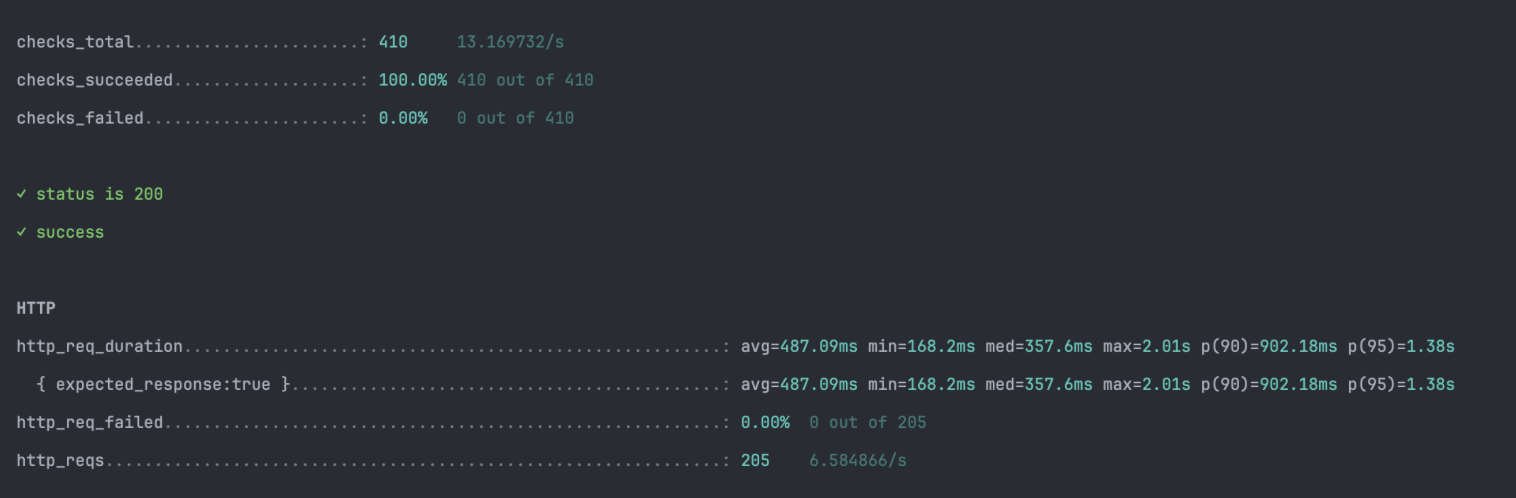
로컬 Docker 환경에서 실제 운영 환경(AWS t2.micro)과 유사한 스펙으로 제한을 두고, k6를 이용해 부하 테스트를 진행한 결과이다.
- 테스트 데이터: 단어(Word) 10,000건 / 학습 기록(History) 50,000건
- 테스트 조건: VUser 10명 / 30초 지속
▼ 개선 전 테스트 결과
- P95: 1.38s (1,380ms)
- 사용자가 단어 추천을 받기 위해 1.3초 이상 대기.
- Avg: 487.09ms
- Throughput: 6.5 req/s
원인 분석
- 메모리 부하: 매 요청마다 DB에서 6만 건의의 데이터를 모두 조회하여 Heap 메모리에 올리고, 동시 접속자가 늘어날 경우 OOM 발생 위험이 크다고 판단
- 비효율적인 연산: 모든 데이터를 애플리케이션으로 가져온 뒤 반복문을 돌며 필터링과 정렬을 수행하여 CPU 사용량이 급증 ?
데이터 처리 위치 이관 (App -> DB)
병목을 해결하기 위해 애플리케이션 메모리에서 처리하던 로직을 DB 레벨로 이관하기로 결정하였고, 복잡한 동적 쿼리와 조인을 타입 세이프하게 작성하기 위해 QueryDSL을 도입
쿼리 최적화
기존의 findAll() 로직을 제거하고, Left Join과 Where 조건을 사용하여 필요한 데이터만 DB에서 가져오도록 변경
@Override
public List<Word> findRecommendedWords(Long userId, int limit) {
return queryFactory
.selectFrom(word1)
.leftJoin(wordLearningHistory)
.on(wordLearningHistory.wordId.eq(word1.id)
.and(wordLearningHistory.userId.eq(userId)))
.where(
wordLearningHistory.isNull()
.or(wordLearningHistory.result.eq(LearningResult.WRONG))
)
.orderBy(Expressions.numberTemplate(Double.class, "function('rand')").asc())
.limit(limit)
.fetch();
}-
Left Join을 통한 전체 모집단 유지
- 추천 대상에는 '한 번도 학습하지 않은 단어(기록 없음)'가 포함되어야 한다
Inner Join을 사용할 경우, 학습 기록이 있는 단어만 교집합으로 조회되므로 '안 배운 단어'가 누락되는 문제가 발생할 것이다.- 따라서 Word(전체 단어)를 기준으로 History(학습 기록)를 Left Join하여, 학습 이력이 없는 단어까지 조회 대상에 포함시켰다.
-
ON 절을 활용한 조인 범위 축소
leftJoin(...).on(...)절 내부에userId조건을 부여- 전체 학습 기록을 다 가져와서 필터링하는 것이 아니라, 해당 유저의 학습 기록만을 대상으로 단어와 매핑하도록 조인 대상을 한정지었다.
-
정교한 Where 절 필터링
- 애플리케이션의 조건문을 DB의 조건문으로 변환
history.isNull(): 조인 결과 학습 기록이 없는 경우 (안 배운 단어)OR history.result.eq(WRONG): 학습 기록은 있으나 결과가 틀린 경우 (오답 단어)- 이 두 조건에 해당하지 않는 경우(즉, 학습 기록이 있고 정답인 경우)는 자연스럽게 결과 집합에서 배제
TO-BE
쿼리 최적화 후, 동일한 데이터와 조건으로 k6 테스트를 다시 수행했다.
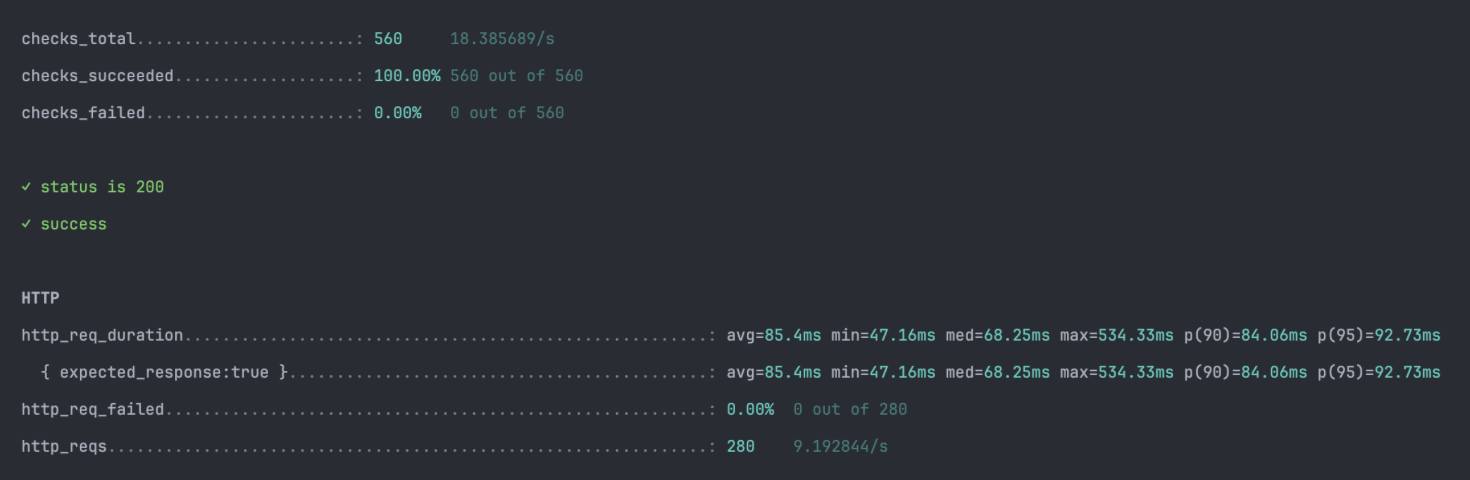
▼ 개선 후 테스트 결과
- P95: 1.38s → 92.73ms (약 15배 속도 향상)
- Avg: 487ms → 85.4ms
- Throughput: 6.5 req/s → 9.2 req/s
회고
실무에서는 빠른 응답을 반환하기 위해 다양한 방법으로 최적화하는것이 필수적이다. 이번 과정을 통해 "데이터가 어디서 처리되는 것이 가장 효율적인가?"를 고민하는 계기가 되었다. 모든 로직을 DB에 위임하는 것이 정답은 아니라고 생각한다. 복잡한 비즈니스 계산이나 DB 부하 분산이 필요한 경우에는 애플리케이션 처리가 유리할 수도 있을 것이다.
현재 정렬에 사용한 MySQL의 ORDER BY RAND()는 간단한 구현에는 유용하지만, 데이터가 수백만 건 이상으로 늘어날 경우 인덱스를 타지 못해 Full Table Scan과 File Sort를 유발하여 다시 성능 저하를 유발할 수 있을 것이라고 나만의 작은 비서에게 도움을 받았다. 이 내용은 Real MySQL 1.0을 읽으면서 학습했던 내용인데, 개념적인 내용을 실제 코드로 적용해본 경험은 없어서 다음 포스팅에서 시도해볼 예정이다. (랜덤값이 아니라 기본키의 인덱스인 클러스터링 인덱스를 잘 사용할 수 있지 않을까..?)
사실 Redis를 사용한다면 조회성능을 대폭 향상시킬 수 있을 것이지만, 외부 인프라 의존성을 늘리기 전에 RDBMS 자체가 가진 인덱싱 구조를 최대한 활용해 보는 것이 더 가치 있는 경험이라 생각했다.
