샤딩이란?
대규모 데이터베이스를 더 작은 단위로 나누어 관리하는 기술.
데이터를 여러 샤드(Shard)라고 부르는 작은 데이터베이스에 나누어 저장함으로써 확장성과 성능을 햑장시킨다.
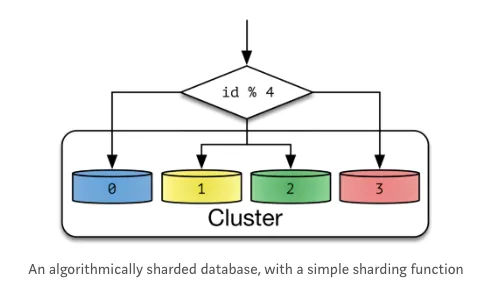
샤드(Shard)?
독립적인 데이터베이스를 부른다.
샤드는 데이터베이스의 특정 부분만 저장하고, 다른 샤드와 함께 전체 데이터베이스를 구성한다.
샤드들은 서로 다른 서버나 노드에 분산되어 저장될 수 있어 병렬 처리와 성능 향상이 가능하다.
샤딩의 장점
- 성능 향상
단일 데이터베이스의 부하를 분산시켜 읽기/쓰기 성능을 개선한다. - 확장성
데이터가 증가하면 새로운 샤드를 추가하여 쉽게 확장이 가능하다. - 가용성 증가 (장애 격리)
하나의 샤드에 문제가 생겨도 다른 샤드는 정상적으로 작동한다. - 비용 효율성
단일 고성능 서버 대신 여러 저렴한 서버를 활룡할 수 있다.
샤딩의 단점
- 복잡한 설계 및 관리
샤드 분할 기준 및 데이터 이동 관리가 어렵다. - 조인 및 집계 연산의 어려움
데이터가 분산되어 있어 샤드 간의 조인 또는 전체 데이터를 기준으로 집계 연산이 비효율적이다. - 데이터 재분배 필요성
샤드 기준이 변경되면 기존 데이터를 재분배해야 할 수 있다. - 운영 비용 증가
여러 샤드 및 서버를 관리해야 하므로 추가적인 비용이 발생한다.
샤딩은 양날의 검이다!
잘 쓰면 장점을 극대화하면서 성능을 크게 향상시킬 수 있지만 못 쓰면 단점이 부각되어 성능이 크게 하락한다.
설계와 유지보수가 어렵기 때문에 밑받침할 수 있는 구현 능력과 신중한 계획이 필요하다.
샤딩을 사용하는 경우
- 데이터베이스 크기가 매우 커서 단일 서버에서 감당하기 힘든 경우
- 데이터베이스의 읽기/쓰기 요청이 매우 많아 성능 저하가 발생하는 경우
- 고성능 또는 고가용성을 요구하는 대규모 분산 시스템.
- DCT 화재 대비.
샤딩 방식
- 수평 샤딩
데이터의 행(Row)를 기준으로 분할
사용자에 따라 정보를 나누어 저장.
(ID1000번대/2000번대/3000번대 또는 학생/교수/교직원) - 수직 샤딩
데이터의 열(Coloumn)을 기준으로 분할
정보의 속성에 따라 나누어 저장
(사용자의 개인정보/사용자의 회사정보) - 키 기반 샤딩
특정 키 값을 해싱하여 샤드를 결정 - 해시 링 기반 Consistent Hashing 기법
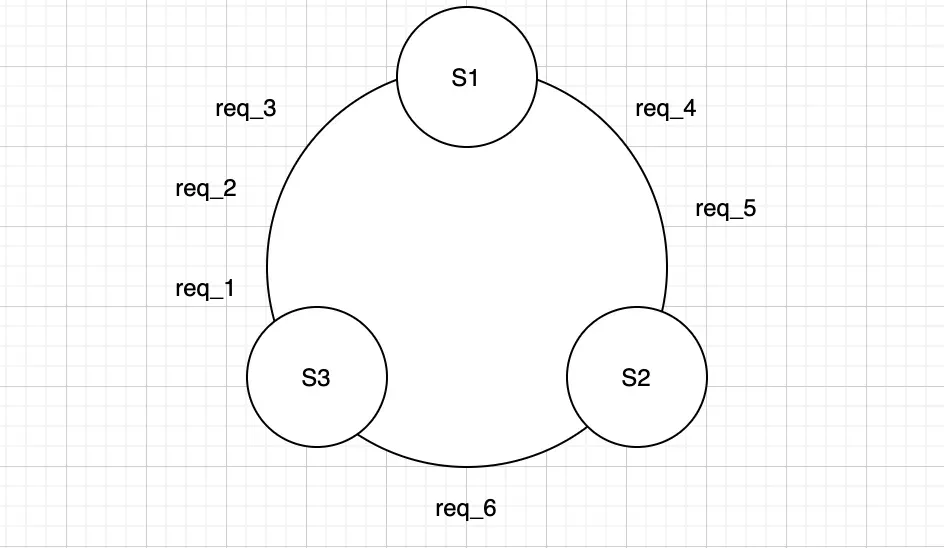
- req_1~3은 S1에, req_4~5는 S2에 req_6은 S3에 저장
- 샤드 하나를 제거해도 4,5를 제외하고는 재배치할 필요가 없다.
- 플레이어 ID를 각 샤드에 균등하게 분배할 수 있다. 가상 노드 개념을 도입하면 더욱 더 균등하게 분포시킬 수 있다.
샤딩 구현 예
- javascript
if (playerId >= 1 && playerId <= 1000) {
return 0; //샤드 0
} else if (playerId >= 1001 && playerId <= 2000) {
return 1; //샤드 1
}- MySQL
-- 범위 기반 샤딩 예:
-- 사용자 ID 1~1000은 user_db1, 1001~2000은 user_db2에 저장
INSERT INTO user_db1.users (id, name) VALUES (1, 'Alice');
INSERT INTO user_db2.users (id, name) VALUES (1500, 'Bob');referance
https://medium.com/@saransh98/node-js-implement-consistent-hashing-f024e43b4259

갓겜만들어야지