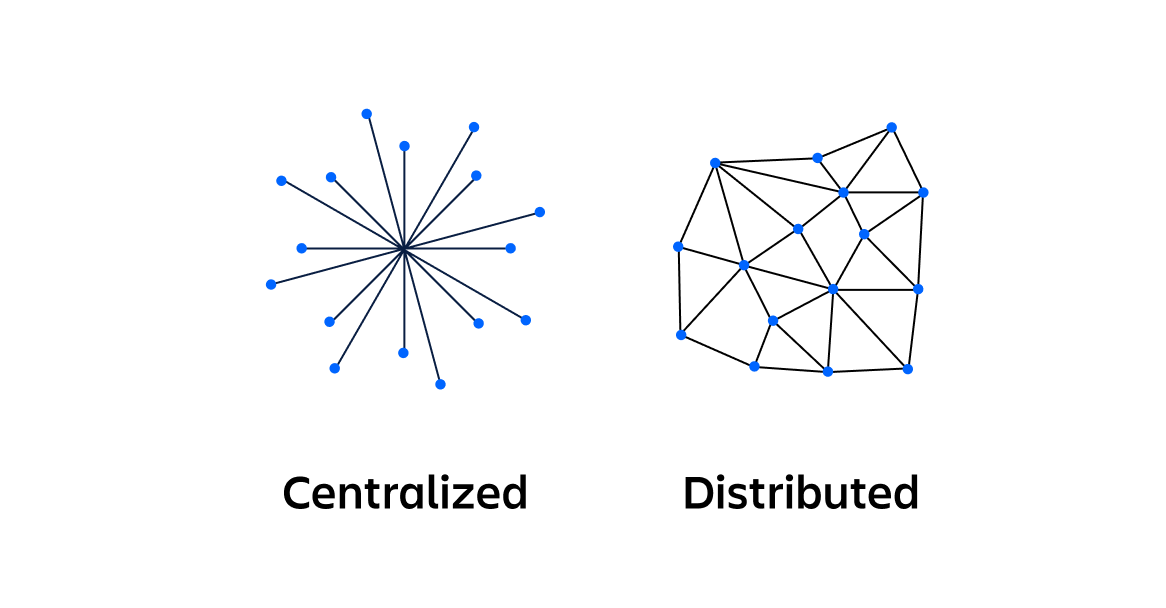
보통 내가 진행했던 프로젝트에서는 단일 데이터베이스를 사용하거나, 단일 시스템에서 동작했기에, auto_increment P.K 전략을 가져가도 중복된 값이 존재하는 경우가 거의 없기 때문에 문제가 되지 않았다. 하지만 대규모 분산 처리 시스템일 때는 이 자동 증가 전략이 문제가 될 수 있다. 여러 노드에서 정말 동시간에 row를 생성했을 대, 각 노드가 독립적으로 데이터를 생성하여 키를 생성하기 때문에, 중복된 키가 생성될 수 있다.
그렇다면, 분산환경일 때는 어떤 id 전략을 선택할 수 있는지 알아보고, 특정 id 전략을 선택했을 때의 성능 측정과 동시성 이슈에 대해서도 한번 살펴보자. 그 전에 우선 내가 주로 사용했던 auto_increment의 문제점에 대해서 먼저 알아보겠다.
단순, GenerationType.IDENTITY 의 문제점?
대부분의 프로젝트에서 나는 ERD를 설계하고, 이를 Entity로 변환하는 작업에서 P.K(기본키) 전략으로
GenerationType.IDENTITY **로 가져갔다. 이는 auto_increment로 id의 수를 1씩 증가시키는 전략이다.
하지만 이는 여러 문제가 존재한다.
- 외부에서 해당 데이터베이스의 P.K를 예측하기 쉬워 SQL injection 문제가 발생할 수 있다.
- auto_increment 혹은 sequence 전략은 중앙 집중식으로 값을 생성하는 방식이여서, 데이터베이스에 의존적이므로, 확장성이 제한된다.
- id 고갈 문제가 발생할 수 있다. BIGINT 최댓값은 4,294,967,295 이고, unsigned BIGINT라면 18,446,744,073,709,551,615 이다.
- 데이터베이스의 변경이 어려운 문제가 발생할 수 있다.
- 데이터베이스가 분산되어 있거나, 2개 이상일 때 중복되는 문제가 발생할 수 있다.
본격적인 설명에 앞서, jakarta 라이브러리에서 제공하는 GenerationType에는 어떤 값들이 있는지 먼저 알아보자.
아래는 GenerationType의 Enum 값 들이다.

| GenerationType | 설명 | 지원 DB | 특징 |
|---|---|---|---|
TABLE | 별도의 테이블을 사용해 키 값 관리 | 모든 DB | 성능이 낮지만 호환성이 높음 |
SEQUENCE | DB의 SEQUENCE 객체 사용 | Oracle, PostgreSQL 등 | 성능이 좋고 커스터마이징 가능 |
IDENTITY | AUTO_INCREMENT 사용 | MySQL, SQL Server 등 | DB가 키 값을 자동 생성 |
UUID | UUID(랜덤) 값 사용 | 모든 DB | 충돌이 거의 없지만 인덱스 부담이 있음 |
AUTO | JPA가 자동으로 전략 선택 | 모든 DB | DB에 따라 적절한 전략이 자동 선택됨 |
그렇다면 분산 환경에서 유일성이 보장되려면, 어떤 id 전략을 가져가야 할까?
Random 함수
- 흔히들 랜덤 값을 생성할 때, 주로 사용하는 랜덤 생성 함수이다.
- 하지만 깊게 생각해보지 않아도, 위 방식은 무작위 수를 생성하기 때문에, 이미 존재하는 id와 값이 같은, 중복 문제가 발생한다.
- 그리고 이후의 전략에서도 나올, MySQL과 같은 데이터베이스의 특징 때문이다.
- MySQL Index는 B+ tree 구조로 순차적인 성질이 있는데, 항상 정렬된 상태를 유지하고, 순차적인 Index에 최적화되어 있기 때문이다.
그래서 위의 전략은 다음과 같은 단점이 있다.
- P.K 중복 가능성에 대한 문제가 존재한다. 이건 굳이 분산 환경이 아닌 내가 주로 사용했던 단일 환경에서도 발생할 수 있다.
- 데이터를 INSERT 할 때, READ 할 때 성능 저하 문제가 발생한다.
- INSERT 성능 저하
- 원인: 랜덤한 값으로 인해 B+ Tree의 중간 노드나 특정 위치에 데이터를 삽입해야 한다.
- 새로 삽입할 값이, Tree의 중간에 위치하면 이미 존재하는 노드를 재조정하고 분할하는 Split이 발생한다.
- Split이 발생하면 추가적인 I/O 작업과 재정렬이 필요하다.
- 결과:
- Tree의 균형을 맞추기 위해 OverHead가 발생한다.
- 원인: 랜덤한 값으로 인해 B+ Tree의 중간 노드나 특정 위치에 데이터를 삽입해야 한다.
- READ 성능 저하
- 원인: B+ Tree가 랜덤한 값 때문에 비순차적으로 정렬되므로, 데이터를 조회할 때 비효율적인 경로 탐색이 발생한다.
- 데이터가 분산되어 있기 때문에, 한 번에 연속된 데이터를 읽기 어렵다.
- 이는 특히 범위 쿼리나 순차적 조회에서 비효율적으로 작동한다.
- 결과: 디스크 I/O 가 발생하며, 더 많은 데이터를 읽기 위해 더 많은 노드 탐색을 해야 한다.
- 원인: B+ Tree가 랜덤한 값 때문에 비순차적으로 정렬되므로, 데이터를 조회할 때 비효율적인 경로 탐색이 발생한다.
- INSERT 성능 저하
다중 마스터 복제(mutli-master-replication)
- 데이터베이스의 auto_increment를 사용하되, 기존 처럼 1씩 증가하는 것이 아닌, 서버의 수만큼 증가시키는 방법이다.
- 각 데이터베이스가 다음에 만들 id 값은 자신이 생성한 이전 id 값에 전체 서버의 수 n을 더한 값인 것이다.
- 즉, 서버가 3대이면 n=3 인 것이다.
하지만 위의 전략은 다음과 같은 문제 혹은 단점이 있다.
- 여러 data center에 걸쳐 확장이 어렵다.
- 시간의 흐름에 맞춰서 id 값을 커지게 하도록 보장하기가 어렵다.
- 서버의 추가 혹은 서버를 삭제할 때도 정상적으로 잘 동작하게 만들기가 어려운 문제가 있다.
UUID
ex) UUID value : cc3246d1-01ga-4a90-b237-02a2dc956dkl
- 시스템에 저장되는 정보를 유일하게 식별하기 위한 128 bit(16 byte)의 수이며, 32개의 16진수 문자열과 4개의 하이픈(-) 으로 구성되어 있다.
- UUID 값은 고유성을 보장하기 때문에, 서로 충돌될 가능성이 매우 매우 낮다.
- 서버 간의 조율이 없이도 독립적으로 생성이 가능하다.
- 알파벳은 소문자로 표현하고, 입력 시 대소문자를 구분하지 않는다.
- 규모의 확장이 쉽다.
하지만 위의 전략도 다음과 같은 단점이 있다.
- MySQL Index는 B+ tree 구조로 순차적인 성질이 있는데, 반대로 UUID는 랜덤 값이므로 성능저하가 크게 발생한다.
- 새로운 row를 INSERT 할 때, 데이터베이스는 전체 테이블을 스캔하여, 적절한 위치를 찾아야 하며, 이로 인해 성능 저하 문제가 발생할 수 있다.
- UUID 값은 숫자가 아닌 문자를 포함하고 있고, 문자의 단위로 비교되기에, 정수와 비교하면 성능이 느리다.(2.5배에서 ~ 28배의 성능 저하가 발생)
- 위의 UUID 값의 예시를 딱 봐도, 길다(16 byte). 그래서 용량도 크다.
- int → 4 byte
- long → 8 byte
- 즉, 대규모의 테이블에서 저장공간을 많이 차지한다.
- 시간순의 정렬이 아니다.
ִInnoDB는 기본키(PK)의 B+Tree에 테이블 행을 저장한다.이를 클러스터형 인덱스(clustered index)라고 부른다. 클러스터형 인덱스는 기본키를 기준으로 자동으로 행의 순서를 지정한다. 그런데 무작위 UUID를 가진 행을 삽입하면 여러 문제가 발생할 수 있어 성능 저하를 초래한다. 이와 관련된 내용은 아래 참고자료를 살펴보자.
MySQL UUIDs - Bad For Performance
The best UUID type for a database Primary Key - Vlad Mihalcea
ULID
-
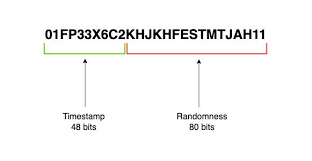
ULID는 위의 UUID와 많이 유사하다. ULID도 128 bit의 크기를 가진다.
-
ULID의 앞의 48 bit 를 차지하는 Timestamp는 시간순의 정렬이 가능하다.
- Epoch(밀리 sec)로 시간을 인코딩 한다.
-
뒤의 80 bit의 크기를 가지는 Randomness가 있다.
-
밀리 sec내에 동싱 생성되면 무작위의 성질에 따라서 순서가 달라진다.
-
UUID의 단점을 해결하기 위해 만들어졌으며, 36자인 UUID와 다르게, ULID는 26문자로 인코딩된다.
- UUID는 Base16, ULID는 Base32 문자의 집합을 사용하기 때문에, ULID가 더 짧은 문자열을 가진다.
-
특수 문자가 없으며, 대소문자를 구분하지 않는다.
-
시간순 정렬이 가능하다.
-
효율성과 가독성을 위해 Crockford의 Base32를 사용한다.
- "I", "L", "O", "U" 제외된다.
- 문자당 5 bit이다.
하지만 위의 전략도 다음과 같은 단점이 있다.
- UUID와 마찬가지로 128 bit이기 때문에, 용량이 크다.
- Base32는 Base16보다 더 많은 정보를 하나의 문자에 담을 수 있기 때문에, ULID가 문자열이 26자로 표현된다. Base16은 16진수로 표현된 데이터를 나타내며, 각 문자는 4비트를 나타낸다. 128 bit(16byte)의 데이터를 Base16으로 표현하면 32문자열이 필요한 셈이다. 하지만 Base32는 각 문자가 5 bit의 정보를 표현하며, 128 bit 데이터를 26문자의 문자열로만 표현할 수 있다.
- UUID는 Base16이기에 32문자로 표현할 수 있는데, 여기서 하이폰이 특수만자로 4객가 추가되기 때문에 36문자로 구성되고, ULID는 특수문자가 없기 때문에, 26문자로 표현이 가능하다. 이것이 UUID와 ULID의 큰 차이점이다.
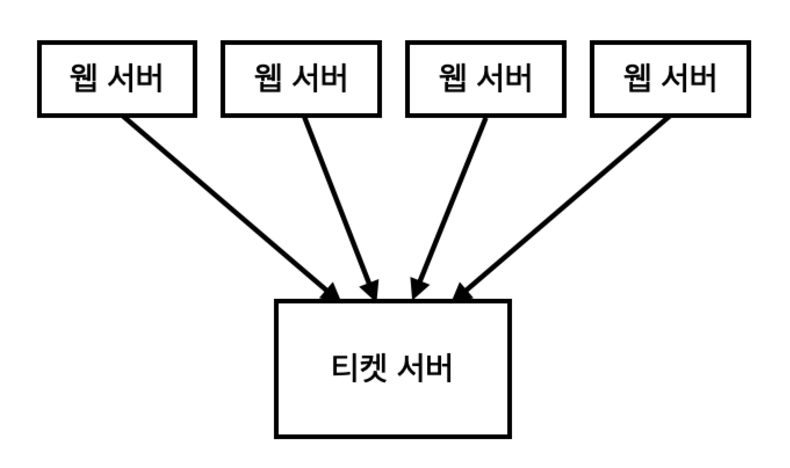
티켓 서버
-
auto_increment 전략을 갖춘 데이터베이스를 중앙 집중형으로 하나만 사용하는 것이다.
-
분산환경에서 고유한 식별자를 생성하고 관리하기 위하여 사용되는 서버를 의미하는 것이, 티켓 서버이다.
-
티켓 서버는 다양한 클라이언트나 서비스가 동시에 접근해, 고유한 티켓(식별자)를 얻을 수 있는 하나의 장소이다.
-
유일성이 보장되는 숫자로만 구성된 id를 쉽게 구성할 수 있다.
-
구현하기 쉬우며, 작은 애플리케이션에 적합하다.
하지만 위의 전략도 다음과 같은 단점이 있다.
- 티켓 서버가 SPOF(Single-Point-Of-Failuer), 단일장애지점이 될 수 있다.
- 티켓 서버 장애 발생 시, 해당 티켓 서버를 이용하는, 연결된 모든 시스템에 영향을 줄 수 있으며, 확장하기가 어렵다.
- 여러 서버에서 티켓 서버로 요청을 하기 때문에, 병목 현상이 발생할 수 있다.
트위터 스노플레이크,(snowflake)
-
트위터에서 고유 id를 생성하기 위해 발표한 전략으로, 대규모 분산 환경에서 고유성, 그리고 정렬 가능성을 보장한다.
-
트위터는 고가용성 방식으로 초당 수만 개의 id를 생성할 수 있는 것이 필요하였고, 이러한 id 전략은 대략적으로 정렬이 가능해야 하며, 64 bit의 용량을 가진다. MySQL 기반의 티켓 서버는 일종의 재 동기화 루틴을 구축해야 했으며, 다양한 UUID는 128 bit가 필요했다. 대략적으로 정렬된 64 bit 용량을 가진 id를 생성하기 위해서 Timestamp, 작업자 번호(worker number) 및 sequece number의 구성으로 결정하였고, sequence number는 thread 별로 지정이 되고, worker number는 시작 시 Zookeeper를 통해 선택이 된다.
-
트위터가 Open Source System으로 공개한 id generator 이다.
-
Time-based 기반이 id이다.
- 시간대 별로 정렬이 가능하며, 의미를 가지는 id이다.
-
확장이 가능하고, 병렬로 유일성을 가진 id를 생성이 가능하다.
-
생성해야 하는 id 구조를 여러 section으로 분할하여 사용한다.

- Sign bit
- 1 bit를 할당하며, 음수 값이 발생하지 않도록 설계된 양수 값만을 생성하기 위해 할당된 것이다.
- Timestamp
- 41 bit를 할당한다.
- 기원 시각(epoch) 이후로 몇 밀리 sec가 경과했는지를 나타내는 값이다.
- 41 bit로 표현할 수 있는 Timestamp의 최댓값은 2^41 - 1 = 2,199,023,255,551 밀리 sec이다.
- 41 bit Timestamp는 약 69년 동안 고유 id를 생성할 수 있다.
- 시간의 흐름에 따라서 큰 값을 가지게 되므로, id는 시간 순으로 정렬이 가능하다.
- id generator가 돌고 있는 중에 만들어진다.
- Data center
- 5 bit를 할당한다.
- 2의 5승인 32개의 Data center를 지원이 가능하다.
- 시스템 시작 시 결정이 되며, 일반적으로 시스템 운영 중에는 바뀌지 않는다.
- Server ID
- 5 bit를 할당한다.
- Data center당 32개의 서버를 사용이 가능하다는 것이다.
- 시스템 시작 시 결정이 되며, 일반적으로 시스템 운영 중에는 바뀌지 않는다.
동일한 시스템에서 동시에 생성이 되는 snowflake id의 중복을 막기 위해 사용되며, 최대 1024개를 구분할 수 있다. → Data Ceneter(32개) * Server ID(32개) = 1024개
- Sequence number(일련번호)
- 12 bit를 할당하며, 2의 12승인 4096개의 값을 가질 수 있다.
- 즉, 1 밀리 sec내에서 0부터 4095까지의 번호를 부여할 수 있다.
- id 생성 시 1씩 증가한다.
- TSID 생성 시 같은 밀리 sec내에 여러 개의 id가 생성될 수 있기 때문에, Sequence number가 1씩 증가한다.
- 이를 통해 중복을 방지하고, 각 id가 고유해지도록 한다.
- 1 밀리 sec가 경과하면 초기화된다.
- 1 밀리 sec가 지나면 Sequence number가 0으로 초기화된다.
- 이후 새로운 밀리 sec 단위에 도달하면, 다시 0부터 시작한다.
- 밀리 sec당 최댜 4096개의 id 생성이 가능하다.
- Sequence number의 값이 0 ~ 4095이기 때문에, 1밀리초당 최대 4096개의 ID를 생성할 수 있다.
- 같은 밀리 sec에 4096개의 ID를 초과하려고 하면 해당 밀리초가 지나갈 때까지 대기하는데, 이는 타임 블로킹(Time Blocking)이라고 부른다.
- ex)
밀리초 Sequence Number 생성된 Snowflake ID 예시 12:00:00.001 0 101010001...0000000001-0000 12:00:00.001 1 101010001...0000000001-0001 ... ... ... 12:00:00.001 4095 101010001...0000000001-4095 12:00:00.002 0 101010001...0000000002-0000
- 12 bit를 할당하며, 2의 12승인 4096개의 값을 가질 수 있다.
하지만 위의 전략도 다음과 같은 단점이 있다.
- 작은 규모에서 운영할 때, trade off를 생각해봐야 한다.
- auto_increment와 동일한 64비트 정수이지만, 분산 환경에서의 네트워크 비용이나 시스템 오버헤드가 추가될 수 있다
TSID(Time-Sorted Unique Identifier)
-
트위터의 스노플레이크와 UUID 의 특성을 결합한 라이브러리이다.
-
시간을 기반으로 고유한 id를 생성하는 방식이다.
-
64 bit 정수 생성이 가능하며, 상대적으로 적은 용량을 차지한다.
-
문자열 형식은 Crockford의 base32로 저장이 가능하다.
-
UUID, ULID 보다 짧다.
-
13자의 문자로 저장이 가능하다.
-
TSID는 Time component 42 bit와 Random component 22 bit로 이루어져 있다.
-
Time component는 부호 있는 64bit 정수 필드에 저장되면 약 69년 동안 사용 가능하고, 부호 없는 64bit 정수 필드에 저장되면 약 139년 동안 사용 가능하다.
-
데이터베이스에 BigInt로 저장되고, Java에서는 long으로 사용이 가능하다.
-
시계열 정렬이 가능하며, P.K를 Byte 배열 대신, 읽을 수 있는 정수(64 bit)로 가져온다.
-
JPA와 Hibernate에서 구현되어 있기 때문에, 쉽게 코드를 작성할 수 있다.
implementation 'io.hypersistence:hypersistence-utils-hibernate-60:3.5.1'
---
import io.hypersistence.utils.hibernate.id.Tsid;
import jakarta.persistence.Id;
public class ArticleEntity {
@Id @Tsid
private Long id;
private String title;
}결론
- 외부에서 봤을 때, 서버의 id를 추측하게 하거나 노출시키는 것은 좋지 않다.
- GET /article/100 보다는 GET /article/12471468926981725 혹은 GET /article/0192AD2B
- 외부 노출 용 id를 따로 생성하여, 내부 P.K Key-Value로 연결해 주고받거나, 내부 P.K를 암호화할 수 있다.
- 내부적으로 사용하거나, 단일 시스템이라면 굳이 UUID, ULID, TSID를 사용하기 보다는 기존에 사용하던 대로 auto_increment를 사용해도 괜찮다.
- 숫자는 문자열에 비해 작은 크기를 가지기에 쓰기, 읽기 속도가 문자열 보다 좋다.
- 분산 환경이라면, UUID의 단점을 개선한 TSID나 snowflake를 사용하는 것이 좋다.
- 각각의 서버가 독립적으로 유일성이 보장된 id를 생성할 수 있기 때문이다.(고유성)
- 데이터베이스가 2대 이상 확장 될 여지가 있다면, auto_increment 보다 TSID, snowflake가 좋다.
ID 생성 전략 비교: UUID, Snowflake, TSID 성능 비교
1. 목표와 테스트 환경
목표:
다양한 ID 생성 전략( UUID, Snowflake, TSID)의 성능과 유일성을 비교하고, 실제 프로젝트에 적합한 전략을 선택할 수 있도록 분석한다.
테스트 환경:
- 1,000,000개의 ID를 생성하여 시간 측정.
- JMH(Java Microbenchmark Harness)를 사용해 Throughput(처리량) 측정 및 테스트 코드를 통한 실행 시간 측정.
- Java 17 환경, 로컬 시스템에서 수행.
2. ID 생성 전략 설명
| 전략 | 설명 |
|---|---|
| UUID | 128 bit 무작위 문자열. 충돌 가능성이 거의 없으며 네트워크 독립적이다. |
| Snowflake | 트위터의 고유 ID 전략. 시간 + 노드 ID + 시퀀스 번호로 구성되며 정렬 가능. |
| TSID | Snowflake와 유사하지만 랜덤 컴포넌트를 추가해 성능 최적화. 빠르고 간단함. |
3. 테스트 결과
- 단순 시간 측정 (1,000,000개의 ID 생성)
package io.soo.sample.codenotesample;
import java.util.UUID;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
public class IdGenerationTest {
private static SnowflakeGenerator snowflakeGenerator;
private static TsidGenerator tsidGenerator;
@BeforeAll
static void setUp() {
snowflakeGenerator = new SnowflakeGenerator(1, 1);
tsidGenerator = new TsidGenerator();
}
@Test
void testIdGenerationPerformance() {
long start, end;
//UUID 테스트
start = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
UUID.randomUUID();
}
end = System.currentTimeMillis();
System.out.println("UUID 1,000,000 IDs: " + (end - start) + " ms");
// Snowflake 테스트
start = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
snowflakeGenerator.nextId();
}
end = System.currentTimeMillis();
System.out.println("Snowflake 1,000,000 IDs: " + (end - start) + " ms");
// TSID 테스트
start = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
tsidGenerator.generate();
}
end = System.currentTimeMillis();
System.out.println("TSID 1,000,000 IDs: " + (end - start) + " ms");
}
}package io.soo.sample.codenotesample;
public class SnowflakeGenerator {
private final long epoch = 1640995200000L; // Epoch 기준 시간
private final long workerId, datacenterId;
private long sequence = 0L;
private long lastTimeStamp = -1L;
public SnowflakeGenerator(long workerId, long datacenterId) {
this.workerId = workerId;
this.datacenterId = datacenterId;
}
public synchronized long nextId() {
long timeStamp = System.currentTimeMillis();
if (timeStamp == lastTimeStamp) {
sequence = (sequence + 1) & 4095;
if (sequence == 0) {
while (timeStamp <= lastTimeStamp) {
timeStamp = System.currentTimeMillis();
}
}
} else {
sequence = 0;
}
lastTimeStamp = timeStamp;
return ((timeStamp - epoch) << 22) | (datacenterId << 17) | (workerId << 12) | sequence;
}
}package io.soo.sample.codenotesample;
import java.util.concurrent.atomic.AtomicLong;
public class TsidGenerator {
private final AtomicLong counter = new AtomicLong();
public long generate() {
return (System.currentTimeMillis() << 22) | counter.incrementAndGet();
}
}
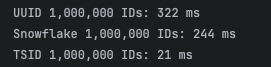
- 결과 해석:
- TSID: 가장 빠른 성능으로 ID를 생성(21 ms).
- Snowflake: TSID보다 약간 느리지만 여전히 빠른 결과(244 ms).
- UUID: 무작위 문자열 생성으로 가장 느린 성능(322 ms).
- JMH 벤치마크 결과 (Throughput 측정)
package io.soo.sample.codenotesample;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Level;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Thread)
public class IdGenerationBenchmark {
private SnowflakeGenerator snowflakeGenerator;
private TsidGenerator tsidGenerator;
@Setup(Level.Trial)
public void setUp() {
snowflakeGenerator = new SnowflakeGenerator(1, 1);
tsidGenerator = new TsidGenerator();
}
@Benchmark
public UUID benchMarkUUID() {
return UUID.randomUUID();
}
@Benchmark
public long benchMarkSnowflake() {
return snowflakeGenerator.nextId();
}
@Benchmark
public long benchMarkTSID() {
return tsidGenerator.generate();
}
}

- 결과 해석:
- TSID: 처리량이 50,135 ops/ms로 월등히 높다.
- UUID: 7,251 ops/ms로 Snowflake보다 약간 높지만 랜덤 특성으로 인덱스 효율성은 낮다.
- Snowflake: 4,083 ops/ms로 처리량이 비교적 낮으나 시간 기반 정렬과 유일성 보장으로 실무에서 유용하다.
4. 유일성 테스트 결과
package io.soo.sample.codenotesample;
import java.util.UUID;
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CountDownLatch;
import java.util.stream.IntStream;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
public class IdGenerationThreadTest {
private static SnowflakeGenerator snowflakeGenerator;
private static TsidGenerator tsidGenerator;
private static final int THREAD_COUNT = 100;
private static final int IDS_PER_THREAD = 10_000; // 각 쓰레드에서 생성할 ID 수
@BeforeAll
static void setUp() {
snowflakeGenerator = new SnowflakeGenerator(1, 1);
tsidGenerator = new TsidGenerator();
}
@Test
void testUUIDUniquenessInMultithreadedEnvironment() throws InterruptedException {
testIdUniqueness(() -> UUID.randomUUID().toString(), "UUID");
}
@Test
void testSnowflakeUniquenessInMultithreadedEnvironment() throws InterruptedException {
testIdUniqueness(() -> String.valueOf(snowflakeGenerator.nextId()), "Snowflake");
}
@Test
void testTSIDUniquenessInMultithreadedEnvironment() throws InterruptedException {
testIdUniqueness(() -> String.valueOf(tsidGenerator.generate()), "TSID");
}
private void testIdUniqueness(IdSupplier idSupplier, String generatorName) throws InterruptedException {
Set<String> idSet = ConcurrentHashMap.newKeySet();
CountDownLatch latch = new CountDownLatch(THREAD_COUNT);
Runnable generateIds = () -> {
IntStream.range(0, IDS_PER_THREAD).forEach(i -> idSet.add(idSupplier.get()));
latch.countDown();
};
// 다중 쓰레드 실행
IntStream.range(0, THREAD_COUNT).forEach(i -> new Thread(generateIds).start());
latch.await(); // 모든 쓰레드의 작업 완료 대기
// 중복 검사
int totalIdsGenerated = THREAD_COUNT * IDS_PER_THREAD;
if (idSet.size() == totalIdsGenerated) {
System.out.println(generatorName + " - All IDs are unique!");
} else {
System.out.println(generatorName + " - Duplicate IDs found! Total: " + totalIdsGenerated +
", Unique: " + idSet.size());
}
}
@FunctionalInterface
interface IdSupplier {
String get();
}
}- 결과 해석:
- 세 가지 전략 모두 동시 요청 환경에서 유일성을 보장했다.
- UUID는 무작위 값, Snowflake와 TSID는 시간 및 시퀀스 기반 생성 방식으로 중복이 발생하지 않았다.
5. 각 ID 전략의 장단점 다시한번 정리
- UUID
- 장점:
- 충돌 가능성이 거의 없음.
- 설정이 간단하고 네트워크 독립적.
- 단점:
- 성능 저하: 랜덤 값 생성의 오버헤드.
- 인덱스 비효율: 데이터베이스 B+ Tree 정렬과 호환되지 않아 성능 저하.
- 장점:
- Snowflake
- 장점:
- 시간 기반으로 정렬 가능.
- 분산 시스템에서 유일성 보장.
- 단점:
- 설정이 복잡(노드 ID 및 시퀀스 관리).
- TSID 대비 성능이 낮음.
- 장점:
- TSID
- 장점:
- 성능이 가장 빠름: 테스트 결과 처리량이 월등히 높음.
- 시간 기반으로 정렬 가능.
- 설정이 간단하고 경량화된 구조.
- 단점:
- 밀리초 단위의 시퀀스 충돌 가능성이 있으나 실무에서는 무시 가능한 수준.
- 장점:
6. 최종 분석
TSID가 모든 면에서 가장 우수한 성능을 보였다.
- 성능: 1,000,000개의 ID를 단 21ms에 생성.
- 유일성: 멀티 쓰레드 환경에서도 충돌 없이 유일한 ID 생성.
- 실용성: 설정이 간단하며 분산 환경에서도 안정적이다.
Snowflake는 정렬과 유일성에서 강점을 가지지만 성능 면에서 TSID에 미치지 못한다.
UUID는 간단하지만 성능 저하와 인덱스 비효율성을 해결해야 한다.
성능이 가장 중요한 환경에서는 TSID를 사용하고, 정렬과 확장이 필요한 분산 시스템에서는 Snowflake를 사용하는 것이 적합할 것 같다. UUID는 설정이 간단하지만 성능과 인덱스 효율성을 고려해야 하며, 그래서 내린 결론은 각 전략의 특성을 이해하고 프로젝트 상황에 맞게 선택하는게..!

https://techblog.woowahan.com/17221/
내추럴 ID!!