
주 2회 ML & DL Study & Q&A 피드백 진행
해당 포스트
📗 회귀분석
스터디원🙎♀️ @dbswls6685
2023-02-24 2회차
❓ 질문 1
Q. 독립변수의 수랑 과적합이랑 무슨 상관이 있는가?
A. 회귀분석에서 독립 변수가 많을수록 모델의 설명력은 좋아질 수 있지만 변수 간의 다중공선성이나 차원의 저주가 발생할 수 있고 이는 과적합으로 이어질 수 있다.
'차원의 저주'란 차원이 증가하면서 학습 데이터 수가 차원의 수보다 적어져 성능이 저하되는 현상을 말한다.
❓ 질문 2
Q. 모델 복잡도 조절 어떻게 하는가?
A. 차원 축소를 실행하여 모델의 복잡도를 줄인다.
인공신경망에서는 은닉층의 갯수나 파라미터의 수로 결정된다. 이를 조절하여 모델의 복잡도를 줄여서 과적합을 방지할 수 있다.
❓ 질문 3
Q. 모델의 복잡도를 감소하면 왜 일반성이 향상되는가? 모델이 복잡할수록 정확도가 높아지는거 아닌가?
A. 과적합된 모델 = 현재 데이터에 필요 이상으로 복잡한 모델, 하지만 복잡할수록 정확도는 높다.
일반화된 모델 = 단순화시켜 조금 손실이 발생하더라도 새로운 데이터에 대한 예측성을 높인다.
❓ 질문 4
Q. 편향(bias)이란?
A. 한 쪽으로 치우친 성질을 의미하며, 예측값들과 정답간의 거리가 멀면 결과의 편향이 높다고 말한다.
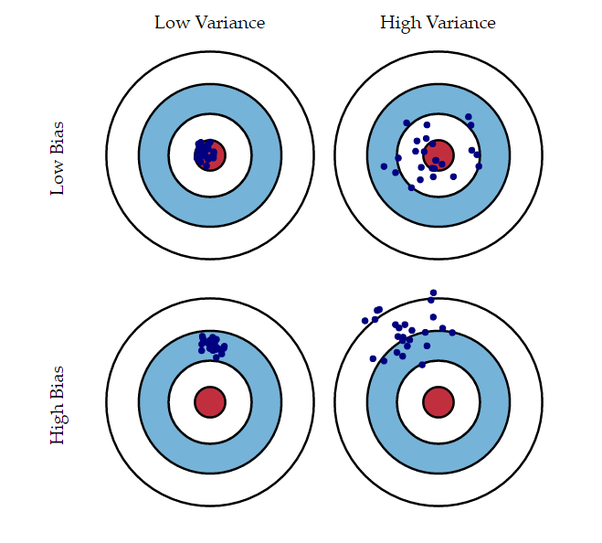
과녁의 빨간색이 정답, 파란 점들이 예측값일 때
위의 2개의 그림은 정답(빨간색)쪽으로 예측값들(파란 점)이 모여있으므로 편향이 낮다고 할 수 있다. 이 그림 중 편향이 가장 큰 것은 4번째 그림이다.
❓ 질문 5
Q. 파라미터(parameter)란?
A. 모형 내부 요소로, 모형의 성능에 직접적인 영향을 미치는 값이다. 모형이 데이터를 학습한 결과 값으로 자동으로 결정된다.
예로는 인공신경망의 가중치, SVM의 서포트 벡터, 선형회귀모형의 결정계수 등이 있다.
❓ 질문 6
Q. 맨하튼 거리, 유클리드거리
A.
맨해튼 거리 = L1 Distance
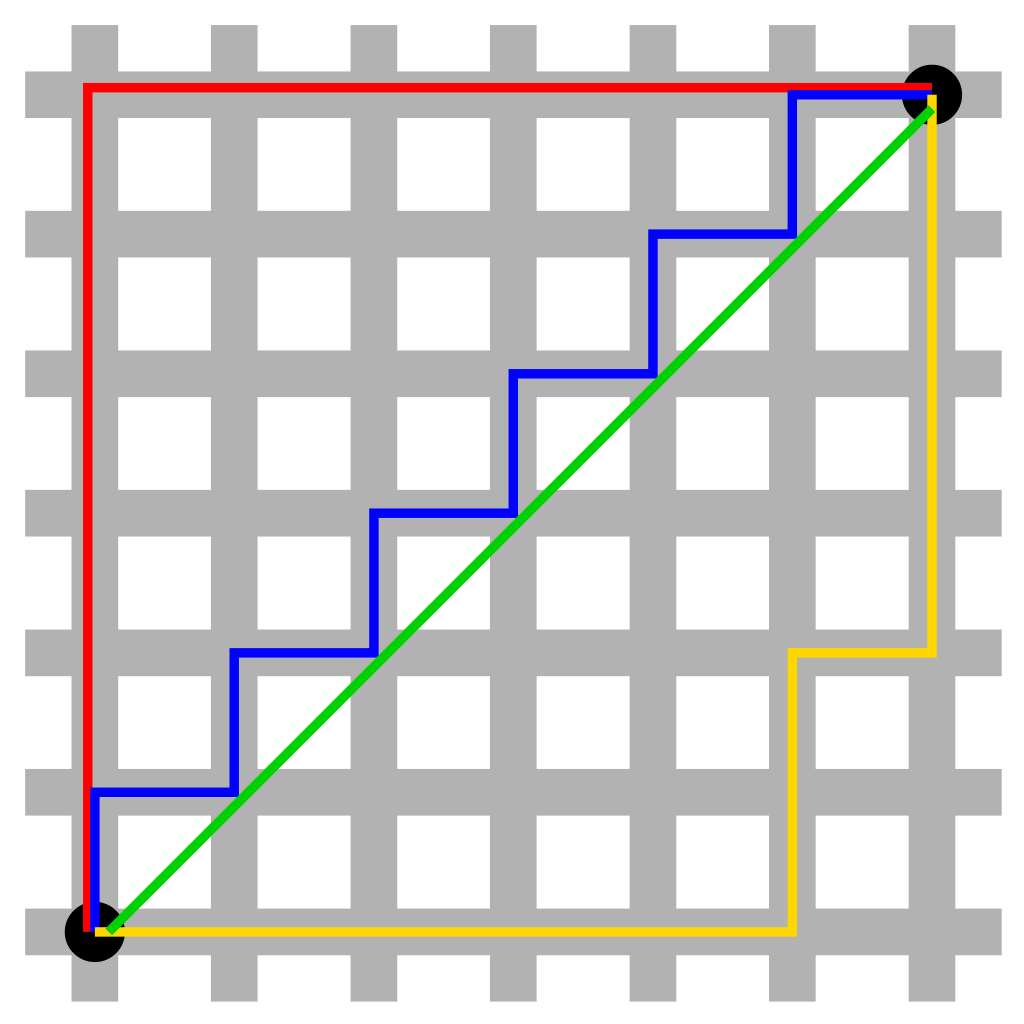
그림에서 빨간색, 파란색, 노란색의 선 길이는 모두 12로 가장 짧은 맨해턴 거리이다. 초록색 직선은 유클리드 거리로, 가장 길이가 짧다.
유클리드 거리 = L2 Distance
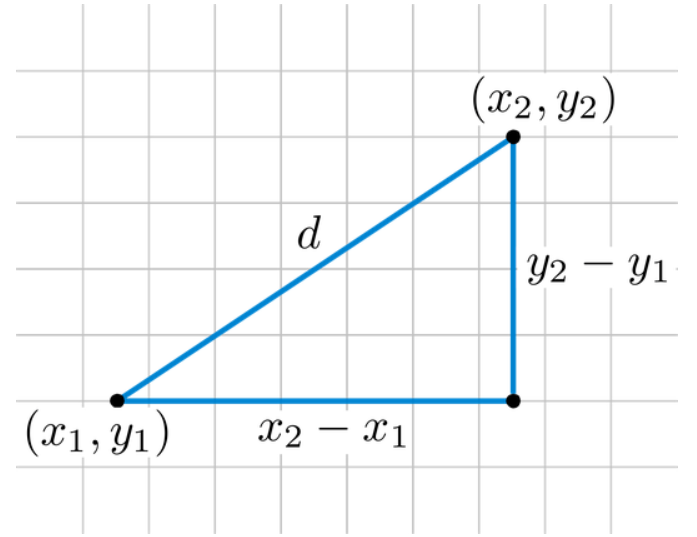
피타고라스 정리 이용
맨하튼 거리와 유클리드 거리는 머신러닝에서 각각 L1,L2 규제로 활용한다.
맨하튼 거리는 절댓값, 유클리드 거리는 제곱을 이용한다.
❓ 질문 7
Q. 손실 함수가 너무 작아지지 않도록 해야한다는데 무슨 의미인가?
A. 손실 함수가 작아진다는 것은 실제 값과 예측 값 간의 차이가 줄어든다는 의미이다. 즉, 손실함수가 0이면 두 값의 차이가 없으므로 오차가 0이므로 최소화하는게 좋다.
❓ 질문 8
Q. L2 규제의 손실합수는 실제 값과 예측 값 오차들의 제곱합이라고 설명했는데, 이것은 왜 이상치에 대해 더 큰 영향을 받는가?
A.
손실함수는 오차이므로 최소화 할수록 좋다.
L1의 손실함수는 오차(실제값 - 예측값)에 절댓값을 씌운다.
하지만 L2의 손실함수는 (실제값 - 예측값)에 제곱을 한다.
이상치의 경우는 오차 값이 커질 것이고, 절댓값을 적용한 손실함수보다 제곱을 한 손실함수 즉 오차가 더 클 것이다.
따라서 L1보다 이상치에 큰 영향을 받는다고 말한다.
