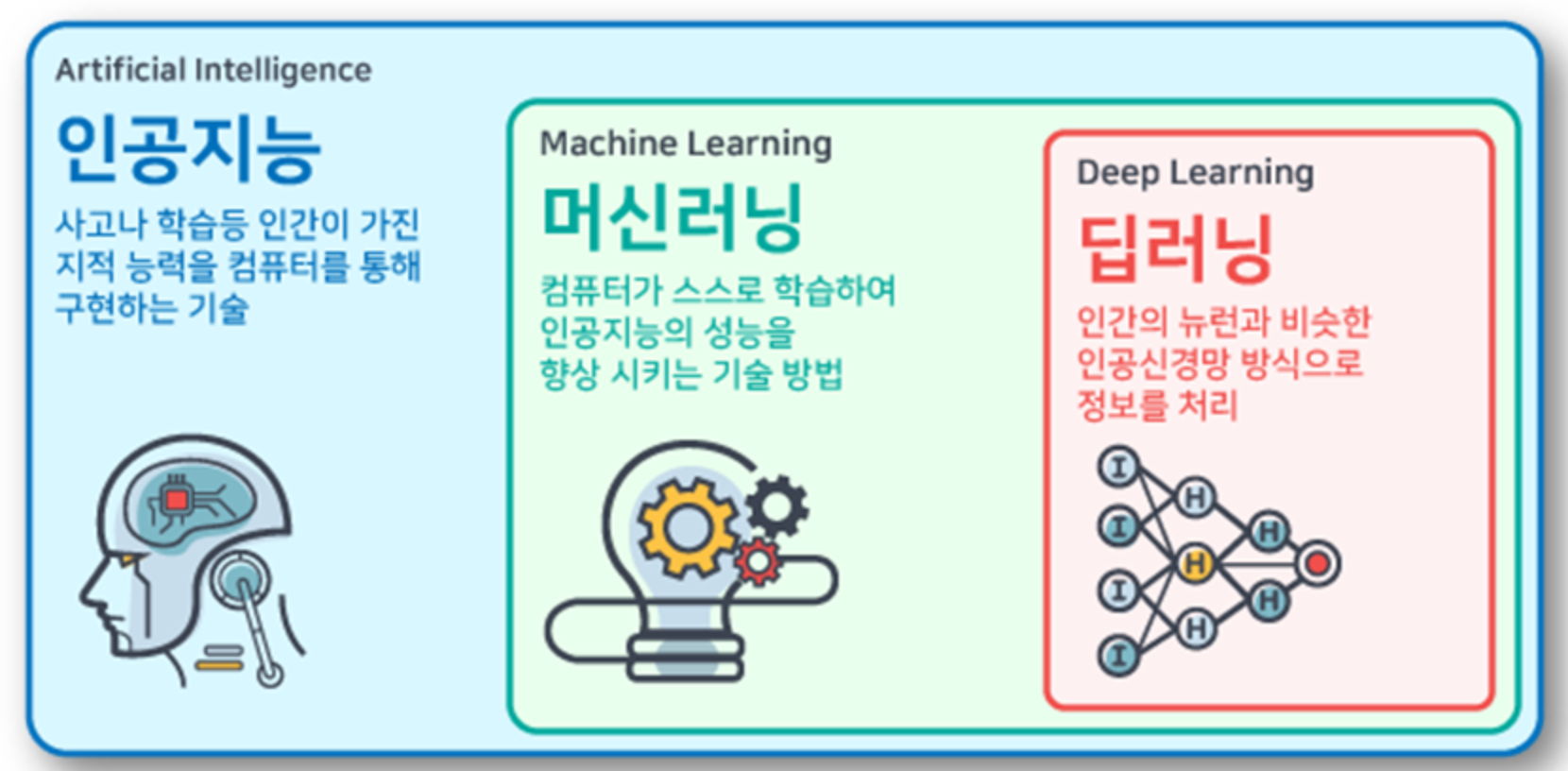
머신러닝(Machine Learning, ML)이란?
이미지 출처 : https://hyeonjiwon.github.io/machine%learning/ML-1/
인공지능(AI)의 하위 분야- 컴퓨터가 명시적으로 프로그램되지 않고도 데이터를 통해 학습하고 경험을 통해 성능을 개선하는 기술
- 데이터에서 패턴과 구조를 분석하여 예측하거나 결정을 내릴 수 있는 모델을 개발하는 데 중점을 둠.
머신러닝의 정의
- 머신러닝은 1950년대 AI의 선구자
아서 사무엘이 “명시적으로 프로그래밍하지 않고도 컴퓨터가 학습할 수 있도록 하는 연구 분야”로 정의함.
전통적인 프로그래밍에서는 사람이 규칙과 논리를 명확히 정의해야 하지만, 머신러닝은 데이터를 기반으로 컴퓨터가 스스로 규칙을 학습함.
머신러닝의 원리
- 데이터 준비
- 머신러닝의 핵심은
데이터이다.데이터는 학습 알고리즘에 입력되며 그 품질과 양은 모델 성능에 큰 영향을 끼친다. - 데이터 전처리 과정에서는 결측값 처리, 이상치 제거, 정규화 등의 작업이 이루어진다.
- 머신러닝의 핵심은
- 모델 선택 및 학습
- 적합한 알고리즘이나 모델을 선택하는 단계. 문제 유형에 따라
선형 회귀,의사 결정 트리,신경망등 다양한 모델이 사용된다. - 학습 과정에서는 데이터를 활용하여 모델의
매개변수(파라미터)를 조정하며,손실 함수(Loss Function)를 최소화하는 방향으로 최적화한다. 이를 위하여 경사 하강법과 같은 최적화 기법이 사용된다.
- 적합한 알고리즘이나 모델을 선택하는 단계. 문제 유형에 따라
- 평가 및 튜닝
- 학습된 모델은 테스트 데이터를 통해 성능을 평가받는다. 이 과정에서
과적합이나과소적합을 방지하기 위해하이퍼파라미터 튜닝이 이루어진다. - 대표적인 평가 지표로는 정확도(Accuracy), 정밀도(Precision), 재현율(Recall) 등이 사용된다.
- 학습된 모델은 테스트 데이터를 통해 성능을 평가받는다. 이 과정에서
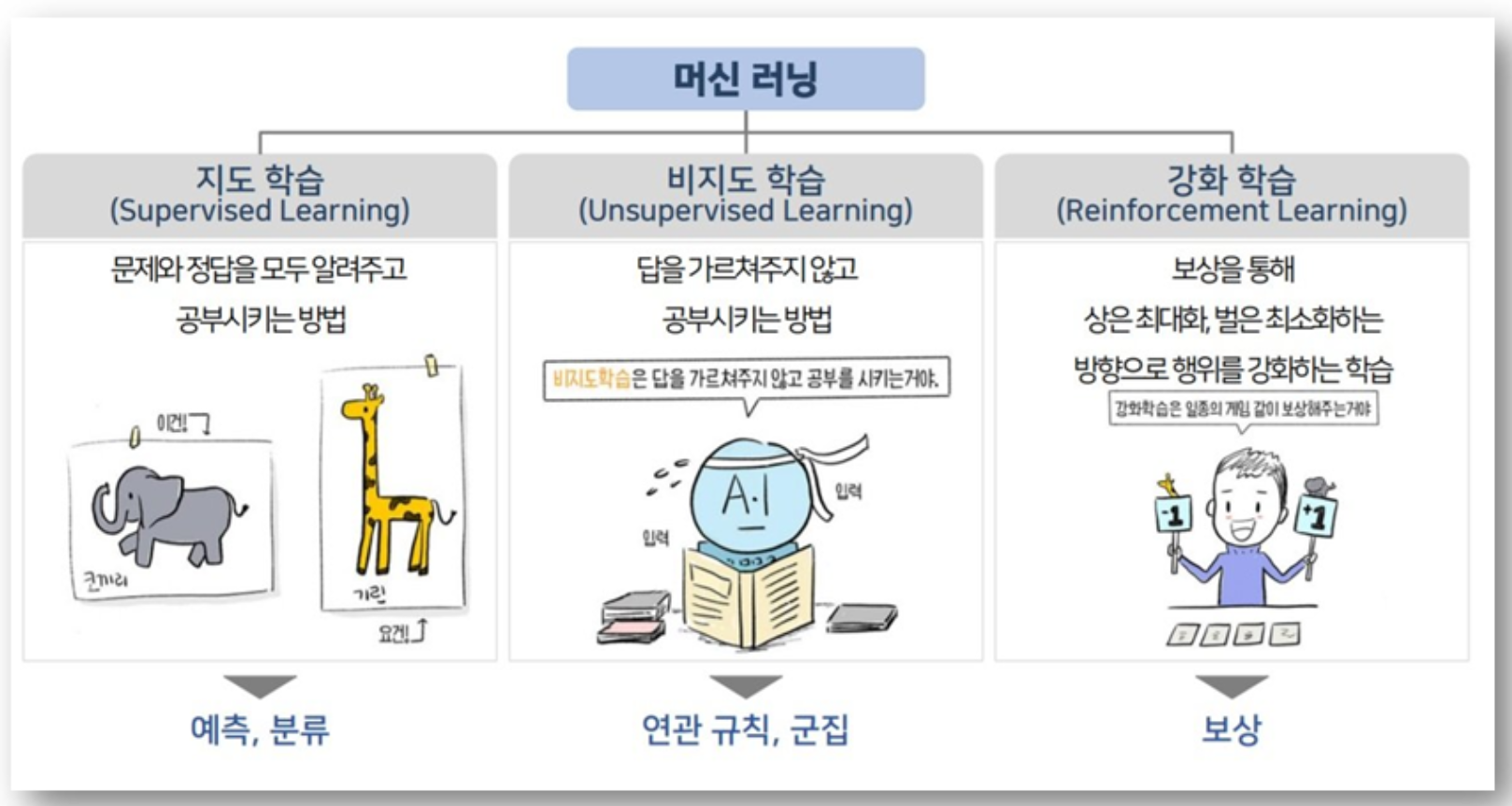
머신러닝의 유형
이미지 출처 : https://jeongminhee99.tistory.com/68
-
지도 학습(Supervised Learning)
: 입력 데이터와 해당 출력(레이블)이 제공되는 경우- 예시 - 이메일 스팸 분류, 주택 가격 예측
: 지도 학습은 학습 결과를 바탕으로 미래의 무엇을 예측하냐에 따라분류,회귀,예측으로 구분할 수 있다.
분류(Classification)
: 데이터가 범주형 변수를 예측하기 위해 사용될 때 지도학습을분류라고 한다. 이미지에 강아지나 고양이와 같은 레이블을 할당하는 경우가 해당된다. 레이블이 두 개인 경우는이진 분류, 범주가 두 개 이상인 경우는다중 클래스 분류라고 부른다.회귀(Regression)
: 연속 값을 예측할 때 문제는 회귀 문제가 된다. 트레이닝 데이터를 이용하여 연속적인 값을 예측하는 것을 말한다.예측(Forecasting)
: 과거 및 현재 데이터를 기반으로 미래를 예측하는 과정이다. 예측은 동향(trends)을 분석하기 위해 가장 많이 사용된다. 예로 들면 올해와 전년도 매출을 기반으로 내년의 매출을 추산하는 과정을 말한다.
- 예시 - 이메일 스팸 분류, 주택 가격 예측
-
비지도 학습(Unsupervised Learning)
: 레이블 없이 데이터의 패턴이나 구조를 찾는 경우- 예시 - 고객 군집화, 차원 축소
: 비지도 학습은 수행할 때 미분류 데이터만을 제공받는다. 모델은클러스터링 구조,저차원 다양체,희소 트리 및 그래프등과 같은 데이터의 기저를 이루는 고유 패턴을 발견하도록 설정된다. 클러스터링(Clustering)
: 특정 기준에 따라 유사한 데이터 사례들을 하나의 세트로그룹화한다. 이 과정은 종종 전체 데이터 세트를 여러 그룹으로 분류하기 위해 사용된다. 사용자는 고유한 패턴을 찾기 위해 개별 그룹 차원에서 분석을 수행할 수 있다.
차원 축소(Dimension Reduction)
: 고려 중인 변수의 개수를 줄이는 작업이다. 많은 애플리케이션에서 원시 데이터(raw data)는 아주 높은 차원의 특징을 지닌다. 이때 일부 특징들은 중복되거나 작업과 아무런 상관이 없다. 따라서 차원수를 줄이면 관계를 도출하기 용이하다.
- 예시 - 고객 군집화, 차원 축소
-
강화 학습(Reinforcement Learning)
: 환경과 상호작용하며 보상을 최대화하는 행동을 학습-
예시 - 게임 AI, 로봇 제어
: 강화 학습은 환경으로부터의 피드백을 기반으로
행위자(agent)의 행동을 분석하고 최적화한다. 모델은 어떤 액션을 취해야 할지 듣기보다는 최고의 보상을 산출하는 액션을 발견하기 위해 다양한 시나리오들을 시도한다. 대표적인시행 착오(trial-and-error)와지연 보상(delayed reward)는 다른 기법과 구별되는강화 학습(RL)만의 특징이다.
-
-
준지도 학습(Semi-Supervised Learning)
: 일부 데이터만 레이블이 제공된 경우를 처리하는 방식
머신러닝과 딥러닝의 차이는?
머신러닝(Machine Learning, ML)은 인공지능의 한 분야로 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야를 말한다.딥 러닝(Deep Learning, DL)은 심층 학습으로도 불리우며 여러 비선형 변환 기법의 조합을 통하여 높은 수준의 추상화를 시도하는 기계 학습 알고리즘의 집합으로 정의된다. 큰 틀에서 사람의 사고방식을 컴퓨터에게 가르치는 기계학습의 한 분야라고 이야기할 수 있다. 딥 러닝은 특징 추출부터 패턴까지 모든 과정을사람의 개입 없이 심층인공신경망을 토대로 학습 방식을 구현하는 기술이다.
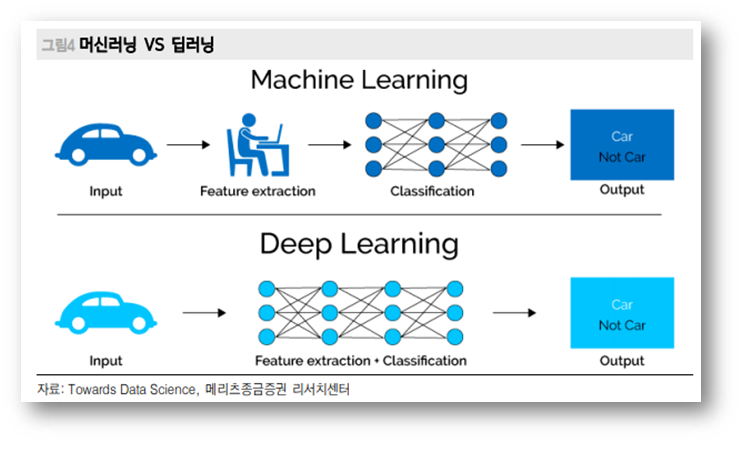
위 사진이 설명하는 바는 아래와 같다.
- 머신 러닝은 인간이 데이터에 대한 결과 값을 미리 알려주어야 하고 목표치에 가까운 결과 값의 특징을 미리 정의해야 한다.
- 딥러닝은 인간의 신경망인 뉴런의 작동 원리를 모방한 인공 신경망을 이용하여 방대한 데이터로부터 결과값을 추출하는 원리로 작동한다.

열심히 살아야지