☑️ 객체지향의 함정
객체지향이란 시스템을 상호작용하는 자율적인 객체들의 공동체로 바라보고 객체를 이용해 시스템을 분할하는 방법이다.
정의가 말이 어려운데 간단한 예제들과 그림을 통해서 살펴보자.
객체 지향이라고 하면 위 그림과 같은 키워드들이 떠오른다. 이론적인 것들 말이다. ex) 객체 지향 = 클래스
이론이 필요할 때도 있겠지만 실무에서는 실제로 객체 지향적인 코드를 짤 수 있는지가 중요하다. 단 번에 객체 지향적인 코드가 머릿속에 그려지고 바로 짤 수 있는 사람은 아마 없을 것이다. 그런 얘기를 하고 싶은 게 아니라 어떻게 접근하는지, 어떻게 설계하는지, 어떻게 수정하는지가 핵심이다.
객체지향에 대한 대표적인 선입견, 오류는 객체지향이 클래스와 클래스 간의 관계를 표현하는 시스템의 정적인 측면에 중점을 둔다는 것이다. 중요한 것은 정적인 클래스가 아니라 협력에 참여하는 동적인 객체이며, 클래스는 단지 시스템에 필요한 객체를 표현하고 생성하기 위해 프로그래밍 언어가 제공하는 구현 메커니즘이라는 사실을 기억해야 한다. 객체지향의 핵심은 클래스를 어떻게 구현할 것인가가 아니라 객체가 협력 안에서 어떤 책임과 역할을 수행할 것인지를 결정하는 것이다. 객체는, 절대 독립적인 존재로 바라보면 안된다. 꼭 협력 속에서 역할을 수행하는 유동적인 존재로 봐야 한다.
☑️ 정렬(정렬 알고리즘)
정렬은 n개의 숫자가 입력으로 주어졌을 때, 이를 사용자가 지정한 기준에 맞게 정렬하여 출력하는 방식이다.
예를 들어 n개의 숫자가 저장되어있는 배열을, 오름차순의 조건으로 작성하여 입력하면 오름차순으로 정렬된 배열을 출력으로 구할 수 있다.
여러 종류들의 정렬을 알아보자.
1. 선택 정렬(Selection Sort)
- 선택 정렬은 이름에 맞게 현재 위치에 들어갈 값을 찾아 정렬하는 배열이다. 현재 위치에 저장될 값의 크기가 작냐, 크냐에 따라 최소 선택 정렬(Min-Selection Sort)과 최대 선택 정렬(Max-Selection Sort)로 구분할 수 있다. 최소 선택 정렬은 오름차순으로 정렬될 것이고, 최대 선택 정렬은 내림차순으로 정렬될 것이다.
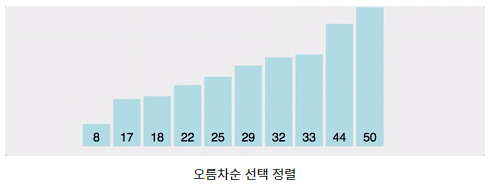
2. 버블 정렬(Bubble Sort)
- 버블 정렬은 가장 쉬운 정렬 알고리즘이지만 시간 복잡도가 좋은 퍼포먼스를 내지 못해서 실제로는 잘 사용되지 않는다.
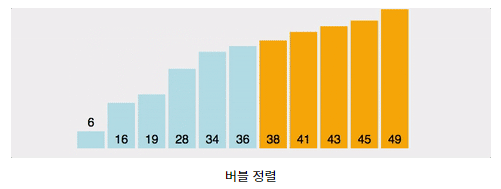
3. 삽입 정렬(Insertion Sort)
- 삽입정렬은 1부터 n까지 Index를 설정하여 현재위치보다 아래쪽을 순회하며 현재위치의 값을 현재위치보다 아래쪽으로 순회하며 알맞은 위치에 넣어주는 정렬알고리즘이다. 삽입정렬은 이미 정렬이 되어있다면 O(n)의 시간복잡도를 가지게된다. 정렬이 되어있는 경우라면 한번 순회하며 체크만 하기 때문이며 Big-O 시간복잡도는 O(n²)이다.
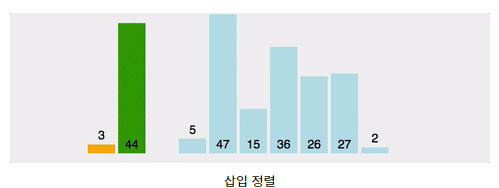
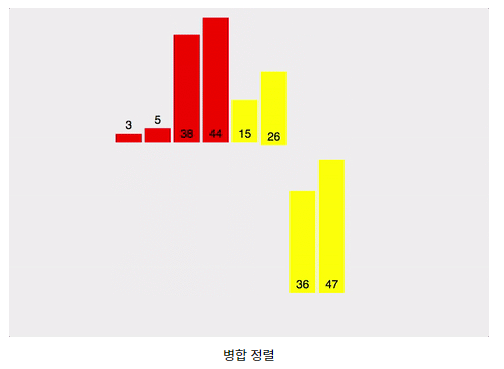
4. 병합 정렬(Merge Sort)
- 병합정렬은 정렬할 리스트를 반으로 쪼개나가며 좌측과 우측 리스트를 계속하여 분할해 나간 후 각 리스트내에서 정렬 후 병합(merge) 정렬 후 병합하는 과정을 통해 정렬하는 알고리즘이다. 병합정렬은 가장 많이 쓰이는 정렬 알고리즘 중 하나 이며 시간복잡도는 최소 O(nlogn)을 보장하게 된다.
☑️ 해시(Hash)
해시란 데이터를 다루는 기법 중에 하나로 검색과 저장이 아주 빠르게 진행된다. 아주 빠르게 진행될 수 있는 이유는 데이터를 검색할 때 사용할 key와 실제 데이터의 값이 (value가) 한 쌍으로 존재하고, key값이 배열의 인덱스로 변환되기 때문에 검색과 저장의 평균적인 시간 복잡도가 O(1)에 수렴하게 된다.
해시 함수, 해시 알고리즘, 해시 코드?
데이터의 value값을 배열의 인덱스인 정수로 변환하기 위해서는 일련의 과정이 필요하다. 예를 들어 데이터를 문자열로 받게 되었을 때 문자 한 글자 한 글자의 아스키코드 값을 더하는 과정으로 문자열을 정수 값으로 변환할 수 있다.
(만약, hello라는 문자열을 정수형 key 값으로 바꾼다면, h + e + l + l + o -> 104 +101 + 108 + 108 + 111 = 532라는 해시 코드로 변환할 수 있다.)
해시 코드를 사용해서 해시 테이블(배열)에 저장하기
해시 코드로 나올 수 있는 숫자의 경우의 수는 아주 많다. 저장할 배열의 크기는 물리적 한계가 있고 수많은 해시 코드들을 대처할 수 없다. 이런 경우 해시 코드를 배열의 크기로 나누고, 그 나머지를 인덱스로 사용하게 되면 0부터 배열의 사이즈-1 만큼의 숫자로 변환하여 사용할 수 있다. 예를 들어 해쉬 코드가 532이고 배열의 크기가 10인 경우 나머지가 2가 나오고, 이 나머지 값을 인덱스로 사용한다.
☑️ 효율성과 성능
오래전부터 컴퓨터 과학자들은 효율적인 검색 알고리즘을 만들기 위해 수많은 노력을 기울였다. 당시에는 컴퓨터가 비싼 시절이었고 성능과 효율성이 서로 연결이 되어있었는데, 지금은 전자 장치의 값이 극적으로 줄어서 성능과 효율성이 분리됐다. 성능과 효율이 분리된 상황을 응용하는 방법인 샤딩과 샤딩의 변종인 맵리듀스를 알아보자.
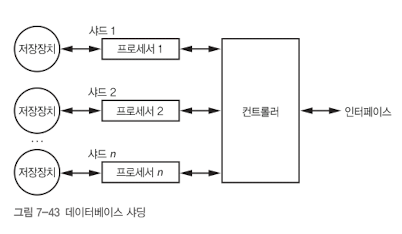
위에 그림처럼 데이터베이스를 각각 다른 기계에서 실행되는 여러 사드로 나누는 방식을 샤딩(sharding) 혹은 수평 파티셔닝(horizontal partitioning)이라고 한다. 인터페이스를 통해 요청이 들어온 데이터베이스 연산을 모든 샤드에 전달하고, 컨트롤러가 그 결과를 하나로 모은다. 이 기법은 사용하면 작업을 여러 작업자로 나눠 수행할 수 있기 때문에 성능이 향상된다.
샤딩의 변종으로 맵리듀스(MapReduce)가 있다. 맵리듀스는 근본적으로 컨트롤러가 중간 결과를 모으는 방법을 코드로 직접 작성할 수 있게 해 준다. 이를 활용하면 ‘모든 수학 강의의 학생 수를 세라’와 같은 연산을 모든 학생의 목록을 읽어와서 세어보지 않고도 처리할 수 있다.
