🔎Set : 요소의 중복 허용 X, 저장 순서 유지하지 않는 컬렉션
- 조쌤은 로또 프로그램을 만드실 때 HashSet을 이용하심. 왜? 중복된 값이 안나오고 저장 순서도 안나오니까!
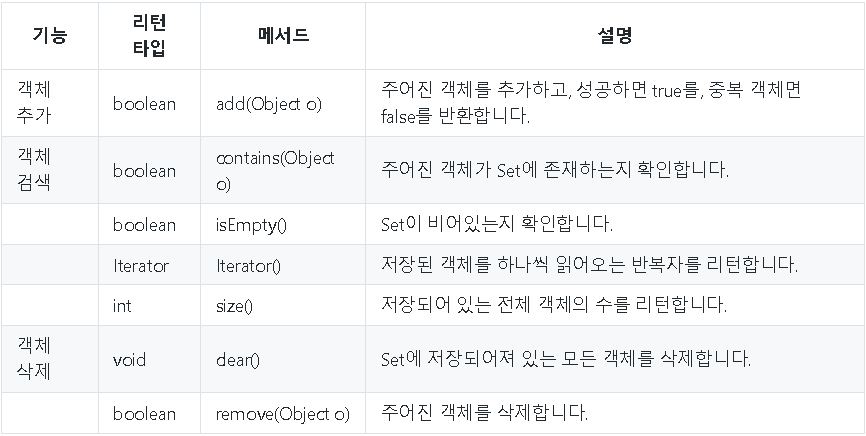
Set 인터페이스에 정의된 메서드
✏️ HashSet
HashSet은 Set 인터페이스를 구현한 가장 대표저인 컬렉션 클래스다.
Set 인터페이스의 특성을 그대로 이어 받아 중복된 값을 허용하지 않고, 저장 순서를 유지하지 않는다.
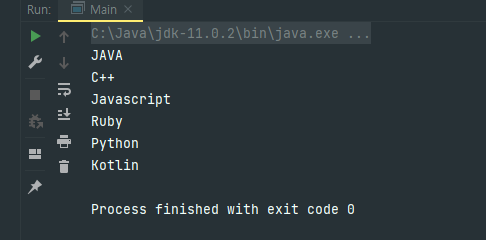
public class Main {
public static void main(String[] args) {
// HashSet 생성
HashSet<String > languages = new HashSet<String>();
// HashSet에 객체 추가
languages.add("Java");
languages.add("Python");
languages.add("Javascript");
languages.add("C++");
languages.add("Kotlin");
languages.add("Ruby");
languages.add("Java"); // 중복
// 반복자 생성하여 it에 할당
Iterator it = languages.iterator();
// 반복자를 통해 HashSet을 순회하며 각 요소들을 출력
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
HashSet에 값을 추가할 때, 해당 값이 중복된 값인지 판단하는 과정
1.add(Object o)를 통해 객체를 저장하고자 합니다.
2.이 때, 저장하고자 하는 객체의 해시코드를 hashCode() 메서드를 통해 얻어냅니다.
3.Set이 저장하고 있는 모든 객체들의 해시코드를 hashCode() 메서드로 얻어냅니다.
4.저장하고자 하는 객체의 해시코드와, Set에 이미 저장되어져 있던 객체들의 해시코드를 비교하여, 같은 해시코드가 있는지 검사합니다.
이 때, 만약 같은 해시코드를 가진 객체가 존재한다면 아래의 5번으로 넘어갑니다.
같은 해시코드를 가진 객체가 존재하지 않는다면, Set에 객체가 추가되며 add(Object o) 메서드가 true를 리턴합니다.
5.equals() 메서드를 통해 객체를 비교합니다.
true가 리턴된다면 중복 객체로 간주되어 Set에 추가되지 않으며, add(Object o)가 false를 리턴합니다.
false가 리턴된다면 Set에 객체가 추가되며, add(Object o) 메서드가 true를 리턴합니다
✏️TreeSet
TreeSet은 이진 탐색 트리 형태로 데이터를 저장합니다. 데이터의 중복 저장을 허용하지 않고 저장 순서를 유지하지 않는 Set 인터페이스의 특징은 그대로 유지한다.
(노드 : 하나하나의 저장공간)
이진 탐색 트리(Binary Search Tree)란 하나의 부모 노드가 최대 두 개의 자식 노드와 연결되는 이진 트리(Binary Tree)의 일종으로, 정렬과 검색에 특화된 자료 구조이다.
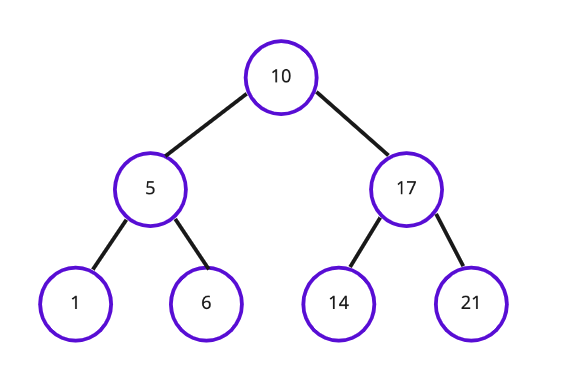
최상위 노드를 '루트'라고 한다. 그림에서는 10에 해당.
이진 탐색 트리는 모든 왼쪽 자식의 값이 루트나 부모보다 작고, 모든 오른쪽 자식의 값이 루트나 부모보다 큰 값을 가지는 특징을 가지고 있다.
class Node {
Object element; // 객체의 주소값을 저장하는 참조변수 입니다.
Node left; // 왼쪽 자식 노드의 주소값을 저장하는 참조변수입니다.
Node right; // 오른쪽 자식 노드의 주소값을 저장하는 참조변수입니다.
}public class TreeSetExample {
public static void main(String[] args) {
TreeSet<String> workers = new TreeSet<>();
workers.add("Lee Java");
workers.add("Park Hacker");
workers.add("Kim coding");
System.out.println(workers);
System.out.println(workers.first());
System.out.println(workers.last());
System.out.println(workers.higher("Lee"));
System.out.println(workers.subSet("Kim","Park"));
}
}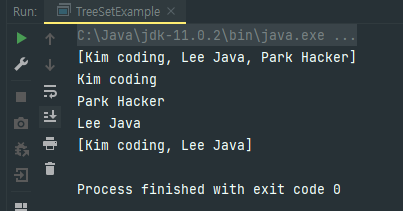
요소를 추가하기만 했음에도 불구하고, 자동으로 사전 편찬 순에 따라 오름차순으로 정렬된 것을 확인할 수 있습니다. 이는 TreeSet의 기본 정렬 방식이 오름차순이기 때문이다.
