1. softmax (분류 함수)
softmax는 모델의 출력을 확률로 해석하며 분류 문제의 경우 softmax+선형모델 조합으로 풀 수 있다. 가장 중요한 점은 다중 클래스 분류이므로 여러개의 선택지 중 하나를 선택할 확률을 나타낸다.
softmax(O) = , ... ,
의 수식으로 나타내며, 는 선택지의 수이다. 예를 들어 3가지의 선택지(의자,책상,책)가 있다면 3차원 벡터이고, 수식은 아래와 같다.
softmax(O) = , , = =
또한, softmax는 지수함수의 계산이므로 오버플로우가 발생될 수 있다. 따라서 입력층의 최대값을 활용하여 오버플로우를 방지한다.
코드
def softmax(x):
c = np.max(x) ##오버플로우 방지를 위한 최대값
a = np.exp(x-c)
sum_a = np.sum(a)
y = a / sum_a
return y
a = np.array([0.3,2.9,4.0])
print(softmax(a))결과적으로 출력값의 모든 합이 1이 되어야한다.
2. MNIST 손글씨 분류
가장 유명한 MNIST 손글씨를 데이터셋으로 하여 분류를 진행해본다.

이러한 손글씨인데.. 글씨를 픽셀값에 따라 행렬로 표현한다. 예제 코드는 아래와 같다.
# 1. MNIST 데이터셋 임포트
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 2. 데이터 전처리 -> 0~1사이의 값을 갖도록
x_train, x_test = x_train/255.0, x_test/255.0
#3. 모델 구성
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax) ##10개의 숫자로 분류하기 때문에 10개의 유닛수로 생성해야한다.
])
# 4. 모델 컴파일
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 5. 모델 훈련
model.fit(x_train, y_train, epochs=5)
# 6. 정확도 평가
test_loss, test_acc = model.evaluate(x_test, y_test)
print('테스트 정확도:', test_acc)모델 구성(Sequential)
tensorflow의 모델 구성 방식은 3가지 정도로 나눌 수 있다 (Sequential, functional, Subclassing). 여기서는 Sequential에 대한 설명을 알아볼 것이다.
Sequential은 하나의 입력텐서에 대한 하나의 출력 텐서 방식에 적합하다. 즉, 일대일 대응 방식이 유리하다는 것이다.
model = keras.Sequential(
[
layers.Dense(2, activation="relu"),
layers.Dense(3, activation="relu", name ="ddd"), ##이름 지정가능
layers.Dense(4),
]
)
model.pop() ##레이어 제거layer의 목록을 생성자에 전달하여 구성할 수 있다. 즉, layers.Dense(생성 유닛 수, 활성화함수)이다.
-활성화 함수 = 입력의 총 합을 출력으로 변환하는 함수
-relu = 활성화 함수의 일부분. max(0,x)이므로 0 이상이라면 x가 되는 경사함수. sigmoid의 gradient vanishing(기울기 소실)을 보완. -> 기울기 소실의 문제는 최적화가 더 이상 진행되지 않는다는 것이므로 큰 문제점임.
입력층의 형상(shape)을 입력
앞 서 보인 코드에서 Flatten(n차원 배열을 1차원으로 평탄화)을 통한 입력층의 형상을 기입했다. 이러한 과정은 가중치가 입력층의 형상에 따라 변하기 때문이다. 따라서 입력층의 형상을 전달하기 위해 input_shape인자를 첫 번째 레이어에 작성해야한다.
tf.keras.layers.Flatten(input_shape=(28,28)) ##데이터셋이 28x28이므로모델 컴파일
loss = 손실함수 지정 (손실함수란, 신경망에서 얼마나 '못'처리했는지를 나타내줌.) 아래는 softmax에 대한 손실함수
- 교차 엔트로피 오차(cross entropy) -> 정답 레이블 t와 출력 레이블 y의 log 값 합
- 오차 제곱합(sum of squares for error) -> 출력 레이블 y와 정답 레이블 t의 차이 제곱합
def sum_squares(y,t): ##오차제곱
return 0.5 * np.sum((y-t)**2)
def cross_entropy(y, t): ##교차엔트로피제곱
delta = 1e-7
return -np.sum(t * np.log(y + delta))optimzer = 훈련 과정
metrics = 훈련 과정 모니터링(accuracy는 정확도를 출력)
모델 훈련 fit(학습데이터, 레이블, 에포크)
-에포크는 훈련 횟수이다.
3. 실행 결과
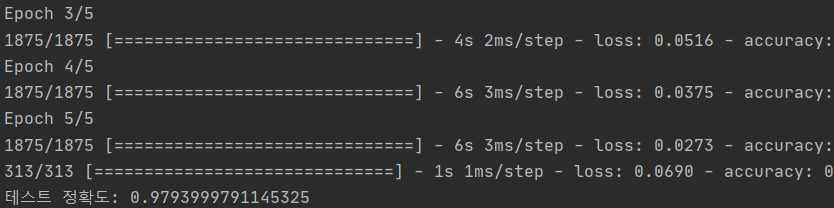
대략 98%의 정확성을 띄게 된다.
