학습 내용 요약
- 논리회귀
- 머신러닝 전처리
- 다양한 머신러닝 모델
1. 논리회귀
논리회귀는 선형회귀로 풀기 힘든 문제를 해결하기 위해 고안된 방법이다. 예를 들어, 시험 점수로 학생의 통과 여부를 판단하는 문제, 메일이 스팸인지 아닌지 판별하는 문제 등 둘 중 하나를 결정하는 문제는 선형회귀로는 풀 수가 없었다. 그래서 분류를 통해 문제를 풀고자 했고, 이를 위한 알고리즘 중 하나가 논리회귀이다.
1) 이진 논리회귀
(1) 설명
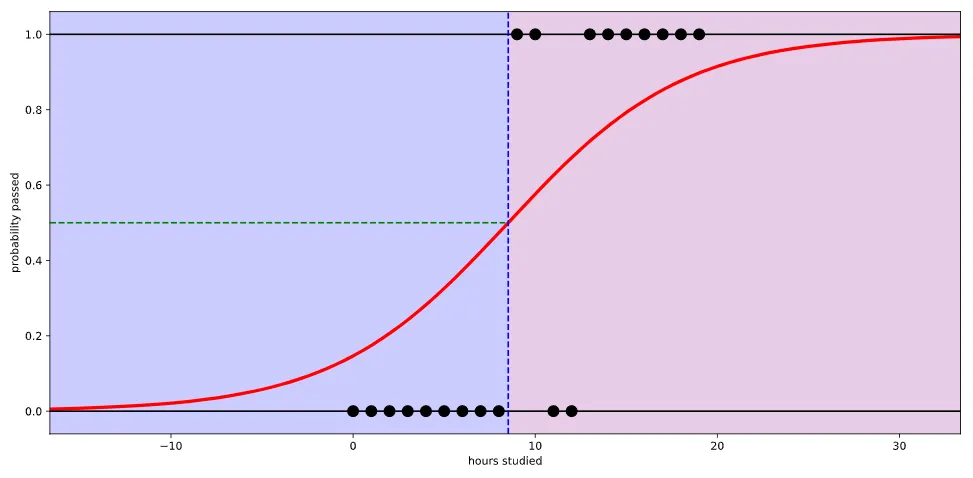
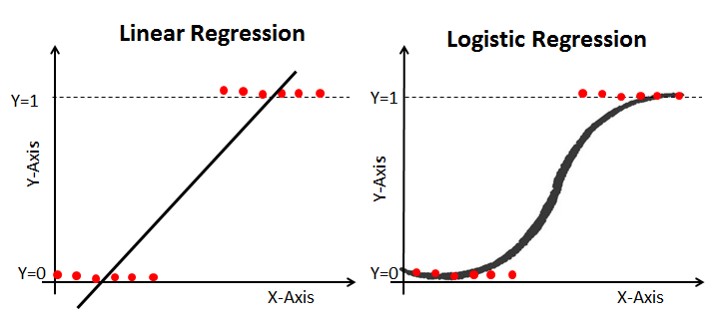
위 그림처럼 정답값을 예측하기 위해 결과가 0~1 사이로 나오도록 그래프를 변형해서 문제를 푸는 것이 이진 논리회귀이다.
실질적인 계산은 선형회귀와 같지만, 출력값에 활성화 함수인 sigmoid 함수를 적용시켜 아래와 같이 값의 범위를 0~1로 만든다.
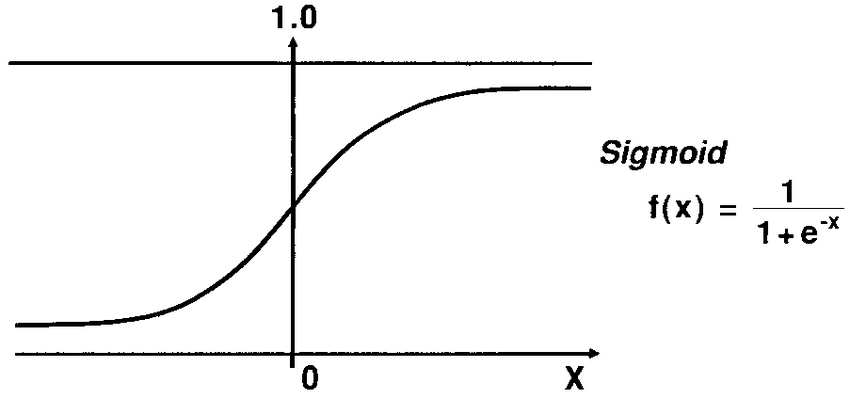
그래서 논리회귀에서의 가설을 보면 다음과 같은 형태가 된다.
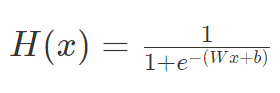
여기서 구해야할 것은 주어진 데이터에 가장 적합한 가중치 (W)와 편향(b)이다. 인공지능 알고리즘이 하는 것은 결국 주어진 데이터에 적합한 가중치를 구하는 것이다.
(2) 손실함수
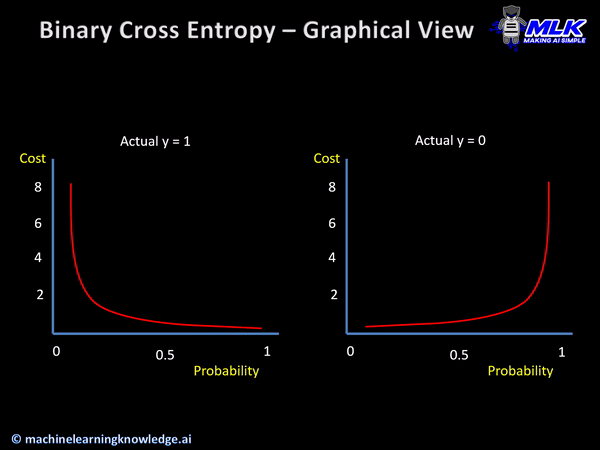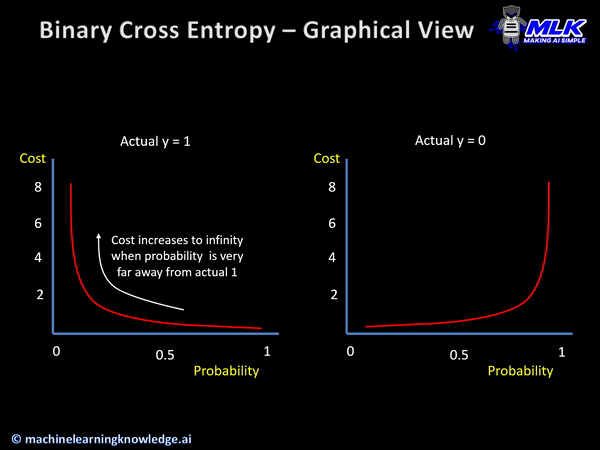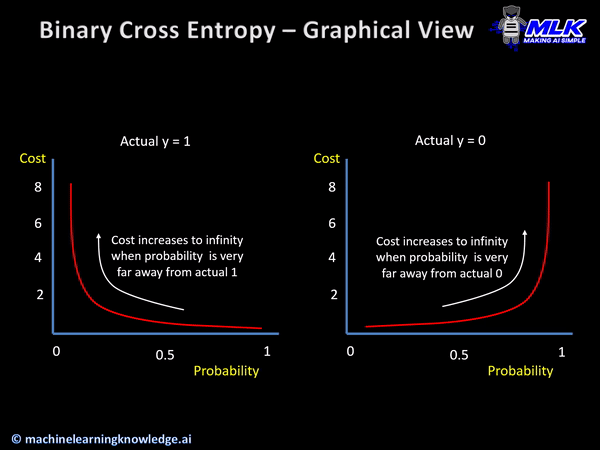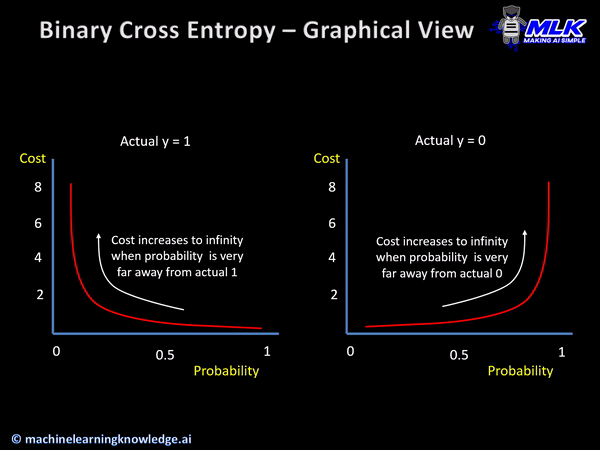
그래프를 보면 왼쪽은 정답값이 1일때 예측값이 1이 되도록, 오른쪽은 0일때 예측값이 0이 되도록 만들어야 한다.
위 그래프처럼 가로축을 라벨(클래스)로 표시하고 세로축을 확률로 표시한 그래프를 확률 분포 그래프이다. 확률 분포 그래프의 차이를 비교할 때는 crossentropy라는 함수를 사용한다. 우리는 임의의 입력값에 대해 나오는 그래프를 crossentropy를 사용해 위 그래프처럼 나오도록 해야 한다는 것이다.
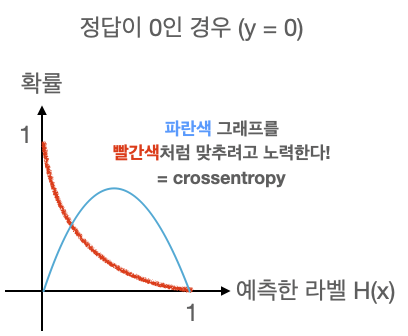
이상으로 살펴본 손실함수는 이진 논리회귀에서 사용하는 binary crossentropy이다.
2) 다항 논리회귀
(1) 설명
이진 논리회귀와 마찬가지로 입력값에 대해 결과값을 범주형 데이터로 나오는 경우 풀기 위해 고안된 방법이다. 다항 논리회귀는 셋 이상의 결과값으로 분류하는 문제를 푸는 방식인 것이다.
이 방식은 선형모델에서 나온 예측의 결과를 확률로 표현하고, 모두 더하면 1이 되도록 한다. 이때 사용하는 활성화 함수가 softmax 함수다.
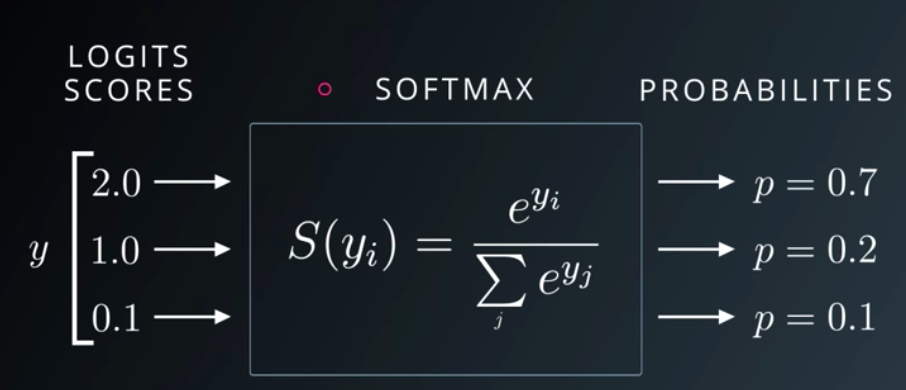
(2) 원핫인코딩
one-hot encoding은 다항 논리회귀에서 출력값의 범주형 데이터 형태를 0, 1로 컴퓨터가 알기 쉽게 나타내 주는 방법이다. 예를 들면,
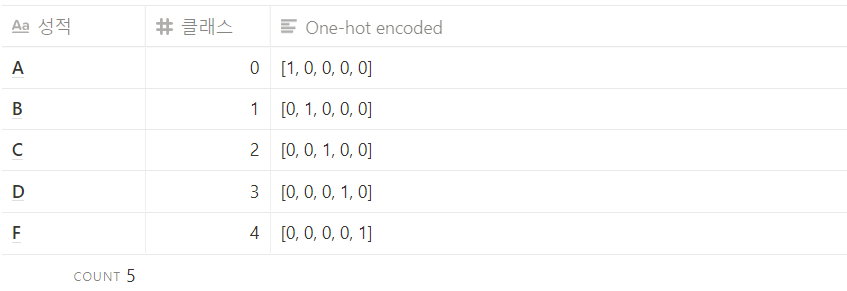
이렇게 각 인덱스 번호에 맞춰 1과 0을 입력해 주도록 만드는 것이다.
원핫인코딩을 하는 방법은 아래와 같다.
- 클래스(라벨)의 개수만큼 배열을 0으로 채움
- 각 클래스의 인덱스 위치를 정함
- 각 클래스에 해당하는 인덱스에 1을 넣음
(3) 손실함수
다항 논리회귀에서 쓰는 손실함수는 categorical crossentropy이다. 이진 논리회귀와 마찬가지로 예측값으로 나온 확률 분포 그래프를 정답값으로 나온 확률 분포 그래프에 가까워지도록 차이를 최소화하는 방향으로 학습시키는 것이 목표다.
2. 머신러닝 전처리
머신러닝 모델을 학습시킬 데이터를 준비해야 한다. 그전에, 우리는 데이터를 활용가능하고 직접 비교 가능한 상태로 만드는 작업을 해야 하는데, 그 과정을 전처리라고 한다. 데이터 전처리는 이상치 제거, 빈 값 제거, 정규화, 표준화 등 많은데, 언급한 네 가지에 대해 살펴보자.
1) 정규화(Normalization)
데이터를 0~1 사이의 범위를 갖도록 조정하는 것이다. 같은 특성의 데이터 중에서 가장 작은 값을 0으로 만들고, 가장 큰 값을 1로 만드는 것이다. 간단히 말하면, 데이터의 범위를 손보는 것이다.
2) 표준화(Standardization)
데이터의 분포를 정규분포로 만듦. 데이터의 평균이 0, 표준편차가 1이 되도록 한다. 즉, 데이터의 중심이 0에 맞춰지게 한다. 쉽게 말해, 데이터들의 단위를 조정하는 것이다.
이처럼 표준화를 시키게 되면 일반적으로 학습 속도(최저점 수렴 속도)가 빠르고, Local minima에 빠질 가능성이 적다고 한다.
3) 결측값(null or na) 처리
결측값이 있으면 데이터간 비교를 제대로 할 수 없기 때문에 모델 학습 전에 특정 조치를 취해야 한다. 결측값을 모두 제거하거나, 0으로 채우는 등 여러 방법이 있다.
파이썬에서는 dropna() 함수로 결측값 제거를 수행할 수 있다.
4) 이상치 제거
어떤 데이터가 30~60 사이로 나타났는데, 특정 몇 개가 100, 98 이런 값이라면, 이 톡 튀어나온 데이터로 인해 제대로 비교를 할 수 없는 경우가 생긴다. 이를 위해 너무 극단적인 범위의 값은 제외하는 작업이 이상치 제거이다.
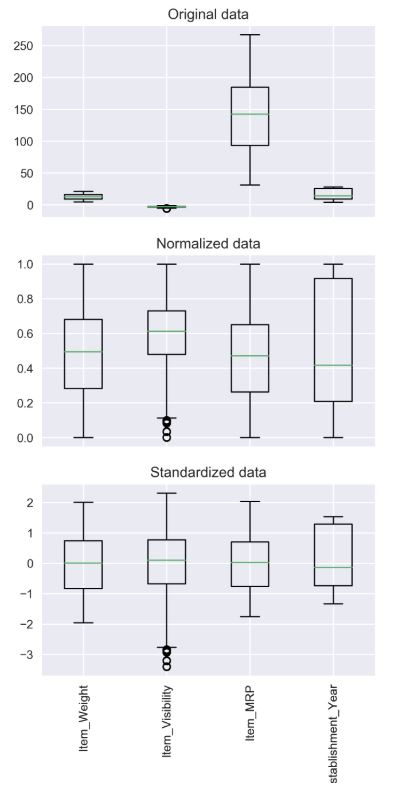
보통 위 네 가지의 전처리 순서는 아래와 같이 진행된다고 한다.
① 결측값 처리
② 표준화
③ 이상치 제거
④ 정규화
3. 다양한 머신러닝 모델
1) SVM(Support Vector Machine)
어떤 특징(feature)을 그래프의 축으로 하고, 각 집단의 최전선 간 거리(margin)가 최대가 되는 구간의 중간 지점에 두 집단을 분류하기 위한 선(support vector)을 긋는다. 이때 margin이 가장 넓어지도록 학습시키는 알고리즘이다.
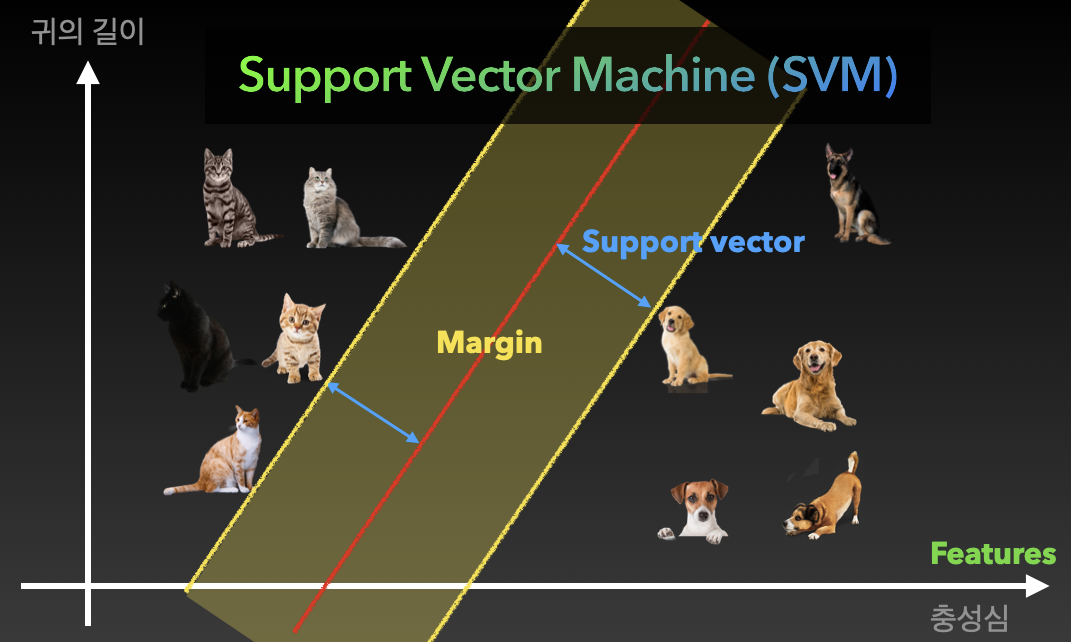
그런데 분류가 어려운 예외 상황이 발생한다면, 더 자세히 분류하기 위해 feature를 추가해서 차원을 높인 그래프에서 구분한다.
2) KNN(k-Nearest Neighbors)
비슷한 특성을 지닌 개체끼리 군집화하는 방법. 해당 개체의 일정 거리 내 다른 개체 수(k)에 따라 위치를 결정하는 알고리즘이다.

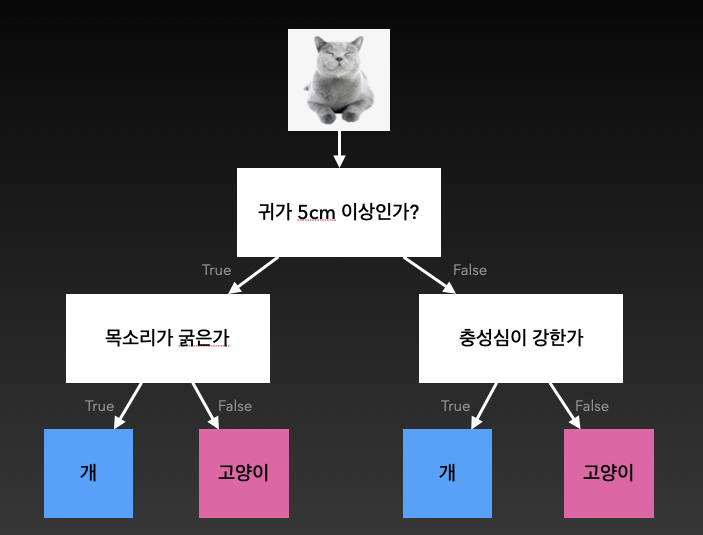
3) 의사결정나무(Decision Tree)
yes, no를 반복하면서 답을 맞춰가는 방식이다.
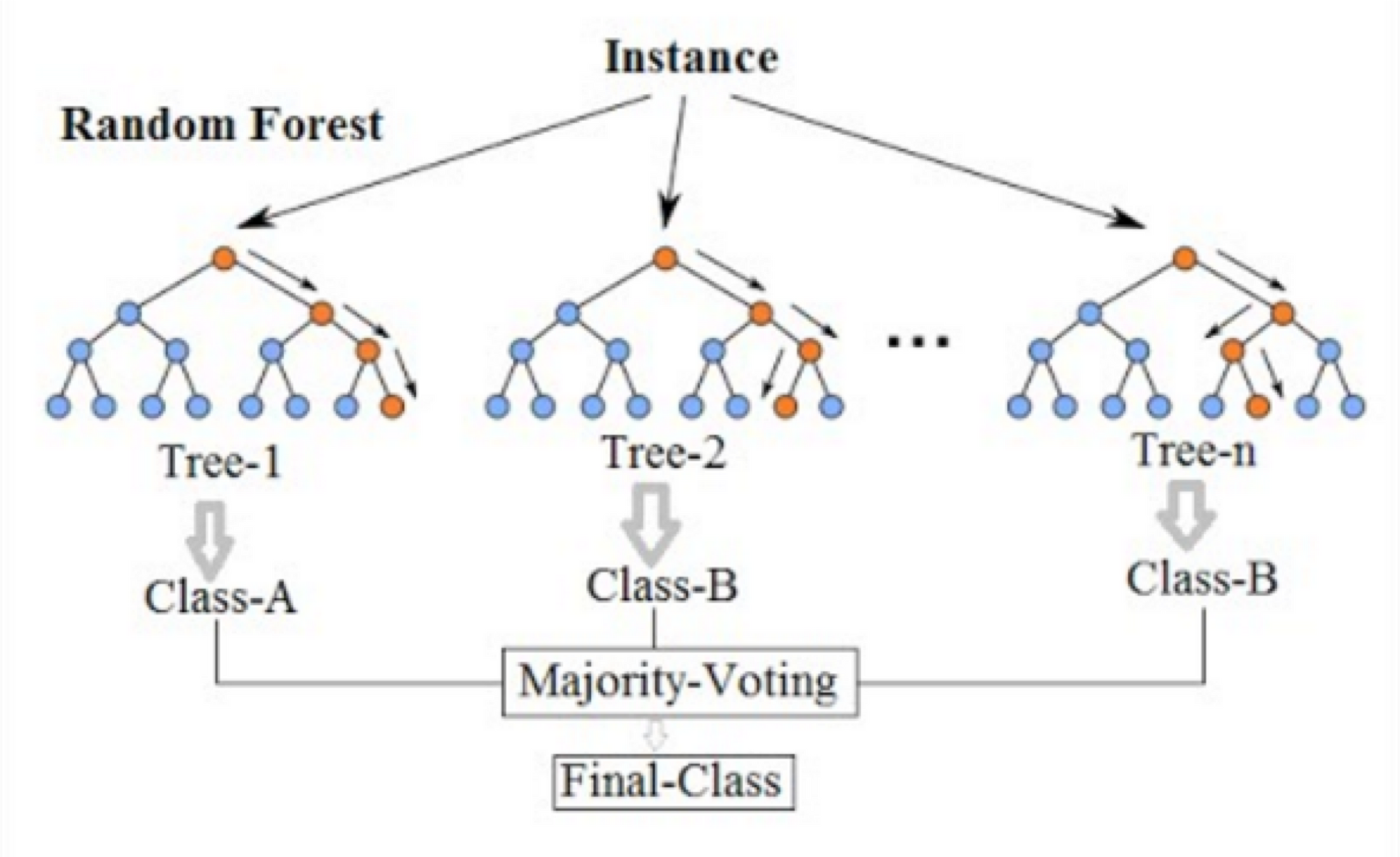
4) Random Forest
복수의 의사결정나무를 합친 모델이다. 각 나무별로 결과를 도출하고, 이를 모아 최종 투표를 거쳐 답을 결정하는 방식이다.
어렵거나 완전히 이해 못한 내용
내용을 정리하면서 결국 논리회귀와 분류는 유사한 것 아닌가 하는 생각을 했다. 하지만 그럼 왜 굳이 분류와 논리회귀로 구분을 지었을까 하는 점은 아직 의문이다. 이 부분을 아직 완전히 명확하게 이해하지 못했다. 그 외에는 어떤 개념이고 어떤 상황에서 쓸 수 있는지 이해했고, 코드를 통해 숙달하면 구현하는 흐름은 더 잘 이해할 수 있겠다.
참고 자료
https://wikidocs.net/35476
https://heeya-stupidbutstudying.tistory.com/32
https://ko.wikipedia.org/wiki/%EB%A1%9C%EC%A7%80%EC%8A%A4%ED%8B%B1_%ED%9A%8C%EA%B7%80
