- SQL에 대해서 설명해주세요. C언어와 같은 프로그래밍 언어와 어떤차이가 있나요?
DMBS 상에서 데이터를 읽고 쓰고 삭제하는 등 데이터를 관리하기 위한 일종의 프로그램 언어이다.
프로그래밍 언어는 개발자가 처리 순서를 처음부터 끝까지 정해줘야하는 절차적 언어라면 SQL은 개발자가 처리 절차를 지정하지 않고 원하는 결과를 정의하여 요청하는 선언적 언어입니다.
좀 더 풀어서 말하자면
프로그래밍 언어로 결과를 얻으려면 계산 과정까지 사용자가 만들어줘야 하지만 SQL은 "무엇을" 얻고 싶은지를 명시하고, "어떻게" 처리할지는 데이터베이스 시스템에 맡깁니다.
SQL은 특정 회사에서 만드는 것이 아니라 국제표준화기구에서 SQL에 대한 표준을 정해서 발표하고 있습니다 (ANSI 표준). 그런데 문제는 SQL을 사용하는 DBMS를 만드는 회사가 여러 곳이기 때문에 표준 SQL이 각 회사 제품의 특성을 모두 포용하지 못합니다. 그래서 DBMS를 만드는 회사에서는 되도록 표준 SQL을 준수하되, 각 제품의 특성을 반영한 SQL 이 존재합니다. (SQL dialect)
- 개발자가 작성한 SQL이 어떤 과정을 통해 실행 되는지 설명해주세요.
(좋은 글 참고 : https://velog.io/@jincrates/1%EC%9E%A5-SQL-%EC%B2%98%EB%A6%AC-%EA%B3%BC%EC%A0%95%EA%B3%BC-IO)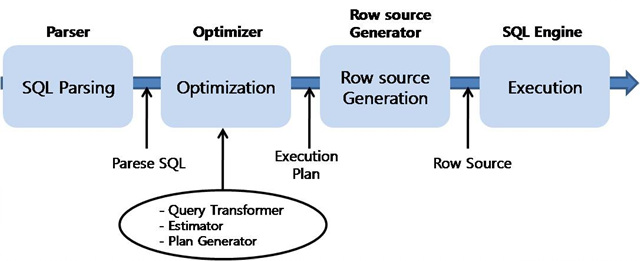
- DML은 무엇인가요? 어떤 구문이 있는지도 설명해주세요.
DML : ( Data Manipulation Language) > 데이터 조작어
- SELECT: 데이터 조회
- INSERT : 데이터 삽입
- UPDATE : 데이터 수정
- DELETE : 데이터 삭제
- DDL은 무엇인가요? 어떤 구문이 있는지도 설명해주세요.
DDL : ( Data Define Language) > 데이터 정의어
- CREATE : 데이터베이스, 테이블등을 생성
- ALTER : 테이블을 수정
- DROP : 데이터베이스, 테이블을 삭제
- TRUNCATE : 테이블을 초기화
- DCL은 무엇인가요? 어떤 구문이 있는지도 설명해주세요.
DCL : ( Data Control Language) > 데이터 제어어
- GRANT : 특정 데이터베이스 사용자에게 특정 작업에 대한 수행 권한을 부여
- REVOKE : 특정 데이터베이스 사용자에게 특정 작업에 대한 수행 권한을 박탈, 회수
- COMMIT : 트랜잭션의 작업을 저장
- ROLLBACK : 트랜잭션의 작업을 취소, 원상복구
- 참조 무결성에 대해서 설명해주세요(외래키 정의부터).
외래키 (Foreign Key)
한 릴레이션 R1 의 튜플과 다른 릴레이션 R2 의 하나의 튜플과의 연관 관계를 표시하기 위하여 사용함
R1 의 속성집합 FK 의 도메인이 R2 의 기본키 일 때 , FK 를 R1 의 외래키라 함
R1 을 참조 릴레이션 , R2 를 피참조 릴레이션이라고 함
R1 과 R2 가 다른 릴레이션일 필요는 없음
참조 무결성
외래키 값은 피참조 릴레이션의 기본키 값이거나 NULL 값이어야 한다
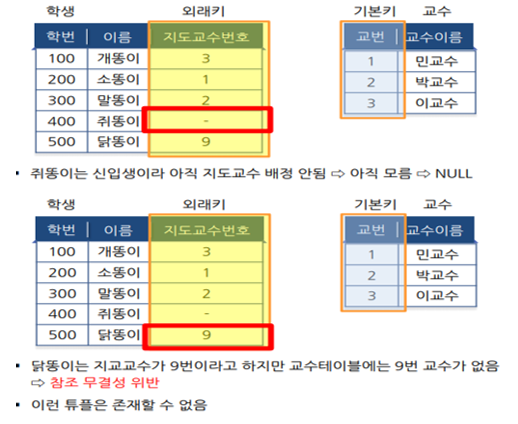
- CASCADE 설정에 대해서 설명해주세요.
기본키를 수정/삭제를 하기 위한 방법으로 FK의 참조값을 NULL로 만들어 참조를 모두 끊은 후, 필요한 수정/삭제를 진행해주는 것인데 해당 방법은 참조키에 NOT NULL 제약 조건이 걸려있다면 활용할 수 없고, 꼼꼼하게 모든 쿼리를 날려야하기 때문에 위험한 방법이기 때문에 이 때 CASCADE 옵션을 사용한다. DB의 값을 수정/삭제할 때, 해당 값을 참조하고 있는 레코드 역시 종속적으로 수정/삭제를 가능하게 해준다.
- VIEW에 대해서 설명해주세요.
(사용자용 테이블 생성)
- 뷰의 장점
- 보안에 도움이 된다 > 권한만큼의 정보를 줄 수 있다
- 복잡한 쿼리를 단순화 시켜 줄 수 있다. > 테이블 2개를 JOIN시켜 놓고 뷰로 만들어 놓으면 하나의 테이블을 만들어 놓는다 즉, 계속 JOIN하는 쿼리를 생성할 필요 없이 2개의 테이블을 조인시켜 놓은 하나의 테이블을 세팅 해놓고 사용할 수 있는 장점을 얻는다
- SELECT 절의 처리순서에 대해서 설명해주세요.

FROM 절에서 테이블이나 뷰를 지정하고, WHERE 절에서 조건을 걸어 특정 행을 선택합니다.
그 후, GROUP BY 절을 사용하여 그룹화하거나, HAVING 절을 사용하여 그룹에 조건을 적용합니다.
이후, SELECT 절에서 지정한 열들을 계산하거나 선택하여 결과를 생성합니다.
마지막으로 ORDER BY 절을 통해 결과를 정렬합니다.
- SELECT ~ FOR UPDATE 구문에 대해서 설명해주세요.
SELECT FOR UPDATE문을 실행하면 LOCK을 획득하고, 해당 세션이 UPDATE 쿼리 후 COMMIT하기 전까지는 다른 세션들이 해당 ROW를 수정하지 못하도록 하는 기능입니다. > 동시성 문제를 잡을 수 있다
(이거 직접적으로 사용하기 보다 뭔가 이거 기반으로 더 고도화시킨 기능이 있을 거 같은데,.,)
- GROUP BY절에 대해서 설명해주세요.
제일 중요한 목표 : 데이터를 그룹화한다
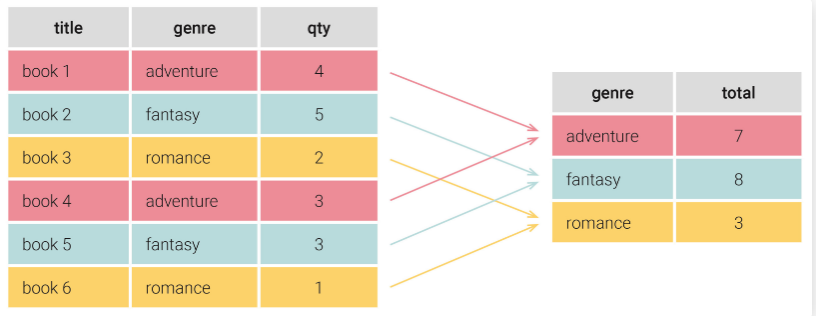
- ORDER BY절에 대해서 설명해주세요.
ORDER BY 절은 SQL 쿼리에서 사용되어 결과 집합을 특정 열을 기준으로 정렬하는 역할을 합니다.
이를 통해 쿼리 결과를 오름차순(ASC)이나 내림차순(DESC)으로 정렬할 수 있습니다.
주로 조회된 데이터를 사용자에게 보기 좋게 정렬하거나, 특정 기준에 따라 정렬된 결과를 필요로 할 때 사용됩니다.
ORDER BY 절은 SELECT 문의 마지막에 위치하며, 정렬하고자 하는 열의 이름을 지정합니다.
(조인을 왜 쓰냐부터 시작해야 할 것 같습니다!)
조인(JOIN) 두 개 이상의 테이블을 서로 묶어서 하나의 결과 집합으로 만들어 내는 것을 말한다.
(왜 분리시켜 놨지?) > 중복으로 인한 이상현상을 피하고 DB 정규화를 지키기 위해서 분리시켜 놓았습니다
결과를 도출하기 위해 테이블을 묶는 것이 조인입니다.
- INNER JOIN과 OUTER JOIN의 차이점에 대해서 설명해주세요.
- INNER JOIN (가장 일반적인 JOIN) > 두 테이블의 교집합, 즉 공통된 데이터를 반환합니다 (결과물에서 join의 기준이 되는 컬럼을 보면 두 테이블이 겹쳐지는 데이터만을 가져옵니다)
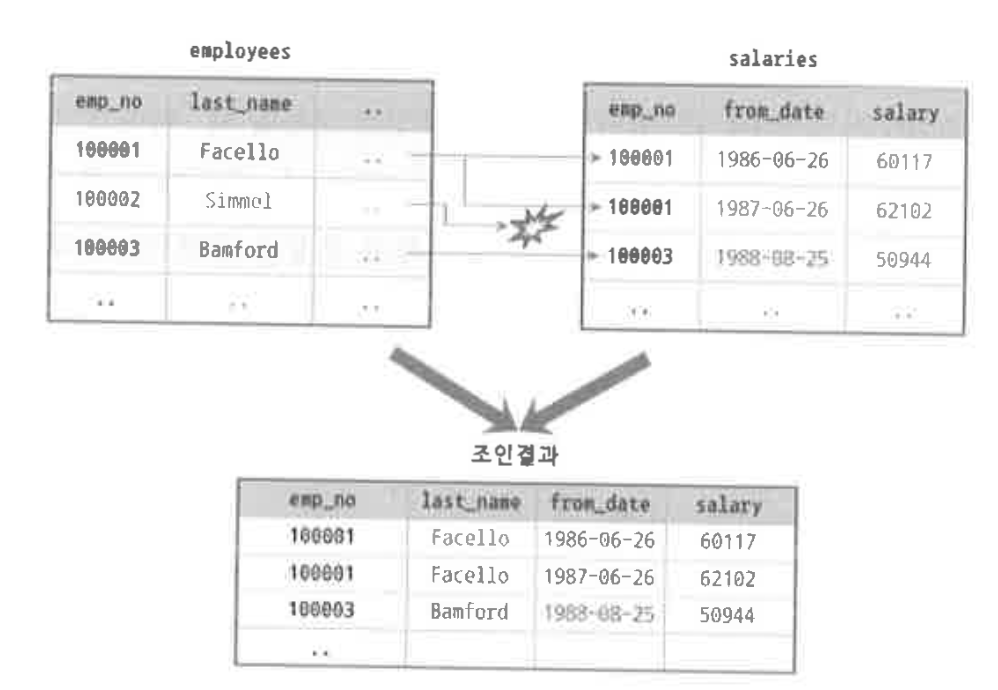
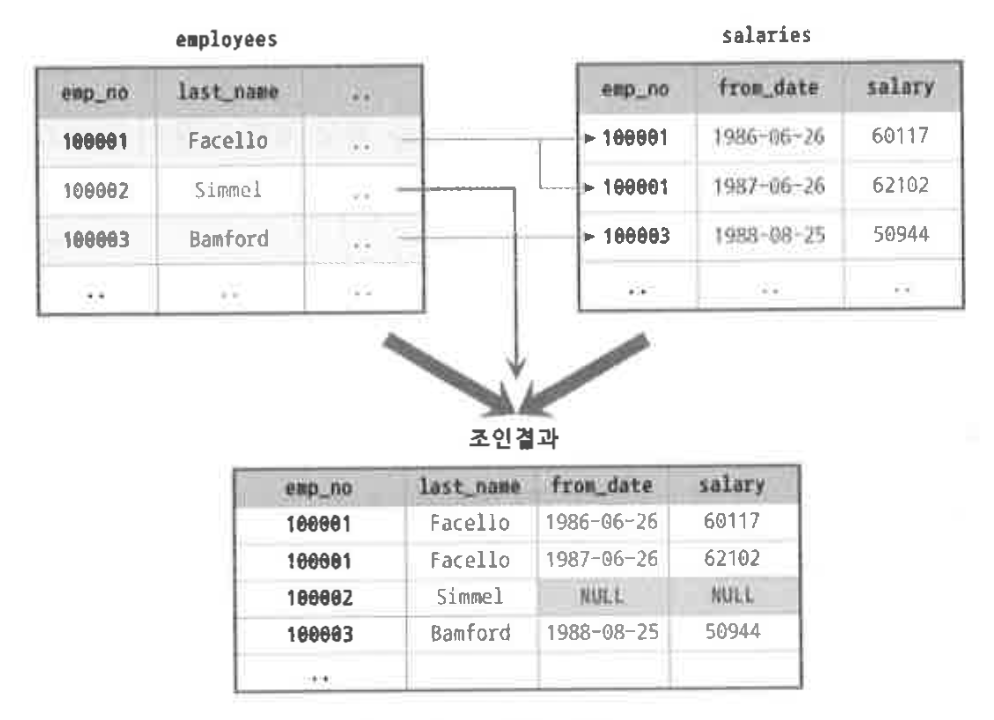
- INNER JOIN (가장 일반적인 JOIN) > 두 테이블의 교집합, 즉 공통된 데이터를 반환합니다 (결과물에서 join의 기준이 되는 컬럼을 보면 두 테이블이 겹쳐지는 데이터만을 가져옵니다)
Mysql은 full Outer join이 없다 Left outer join과 Right Outer join을 한 결과를 UNION함수로 묶어서 결과를 만들어야 한다
- LEFT OUTER JOIN, RIGHT OUTER JOIN에 대해서 설명해주세요.
(왼쪽 테이블은 다 살려줄게) / (오른쪽 테이블은 다 살려줄게) > 각각 비어있는 곳은 NULL로 채웁니다.
- CROSS JOIN에 대해서도 설명해주세요.
(언제 쓰는 건지 궁금.. 실제로 사용 하나?)
한쪽 테이블의 모든 행들고 다른 쪽 테이블의 모든 행을 조인시키는 기능을 합니다. 그래서 CROSS JOIN의 결과는 두 테이블 개수를 곱한 개수가 됩니다.
- 서브쿼리에 대해서 설명해주세요.
서브쿼리(subquery)란 다른 쿼리 내부에 포함되어 있는 SELETE 문을 의미한다.
서브쿼리를 포함하고 있는 쿼리를 외부쿼리(outer query)라고 부르며, 서브쿼리는 내부쿼리(inner query)라고도 부른다.
서브쿼리는 다음과 같이 괄호() 로 감싸져서 표현 된다.
- DROP, TRUNCATE, DELETE에 각각에 대해 설명해주세요. 어떤차이가 있나요
Drop : 테이블 완전 삭제 / TRUNCATE : (컬럼은 살려는 드릴게) 테이블의 데이터 전체 삭제 / DELETE : 원하는 데이터 삭제, RollBack가능하다
데이터 전체 삭제시 TRUNCATE가 권장 되나 이후 정상적 복구는 불가능하다.
- DISTINCT에 대해서 설명해주세요. 사용해본 경험도 설명해주세요.
컬럼을 조회할 때, 중복되는 값을 제거하고 조회합니다. (사용해 본 경험은 아직 없고 정보처리기사 문제에서 본 적이 있어서 어떻게 써야 하는지와 어떤 결과가 출력되는지 학습한 경험이 있습니다.)
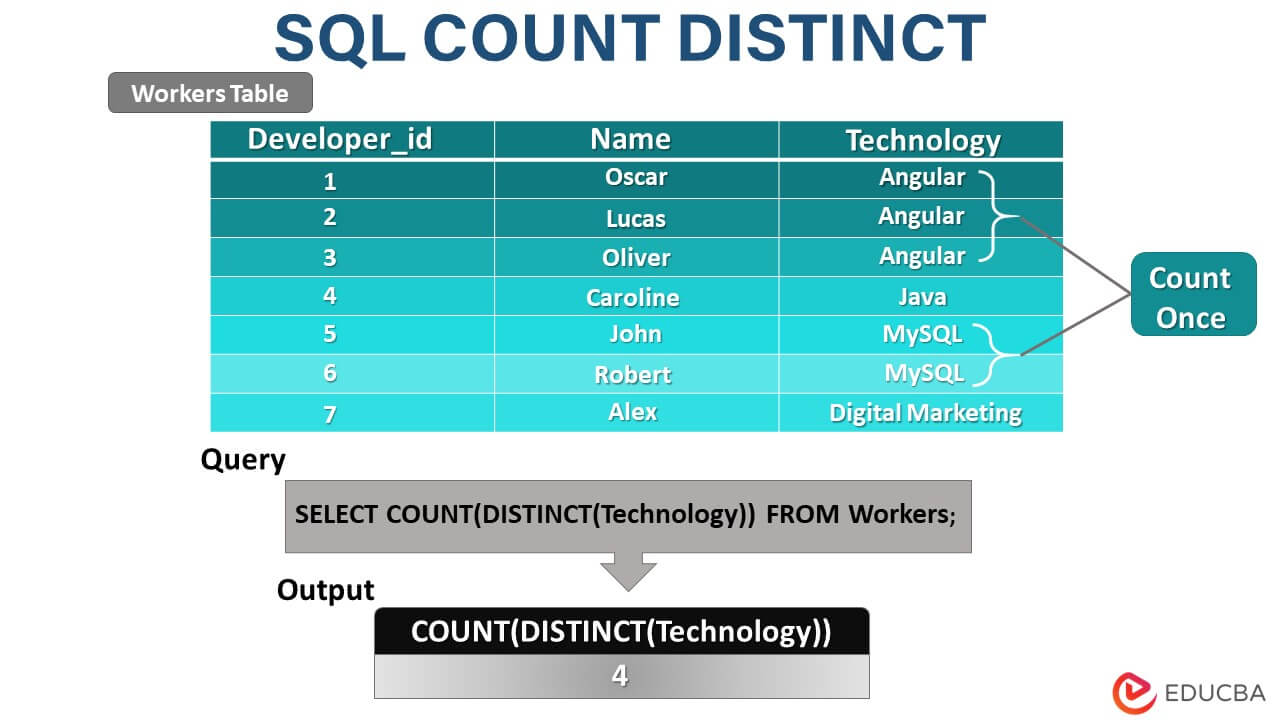
SELECT DISTINCT는 중복 데이터를 제거하는 효과적인 방법이지만, 대량의 데이터를 처리할 때 성능 저하를 유발할 수 있습니다. 따라서, SELECT DISTINCT 사용 시 데이터셋의 크기와 성능을 고려하여 사용해야 합니다.
(질문 : 그렇다면 대량의 데이터에서 중복되지 않는 데이터를 얻으려면 어떻게 대응해야 하는건가요?)
출처: https://statuscode.tistory.com/137 [Status Code:티스토리]
- SQL Injection 공격이 무엇인지 어떻게 공격을 예방할 수 있는지 설명해주세요.

클라이언트의 입력값을 조작하여 서버의 데이터베이스를 공격할 수 있는 공격방식을 의미합니다. 주로 사용자가 입력한 데이터를 제대로 필터링, 이스케이핑하지 못했을 경우에 발생합니다.
(공격 난이도 대비 성공하게 되면 효과가 파괴적이다! / 2017년 여기어때도 당한적이 있다.)
SELECT user FROM user_table WHERE id='admin' AND password=' ' OR '1' = '1';
user_table의 모든 정보를 조회하게 됩니다.
- Prepared Statement 구문사용
Prepared Statement 구문을 사용하게 되면, 사용자의 입력 값이 데이터베이스의 파라미터로 들어가기 전에DBMS가 미리 컴파일 하여 실행하지 않고 대기합니다. 그 후 사용자의 입력 값을 문자열로 인식하게 하여 공격쿼리가 들어간다고 하더라도, 사용자의 입력은 이미 의미 없는 단순 문자열 이기 때문에 전체 쿼리문도 공격자의 의도대로 작동하지 않습니다.
내부에 구현된 메서드로 sql 인젝션에 위험이 될 문자들을 변환시켜준다

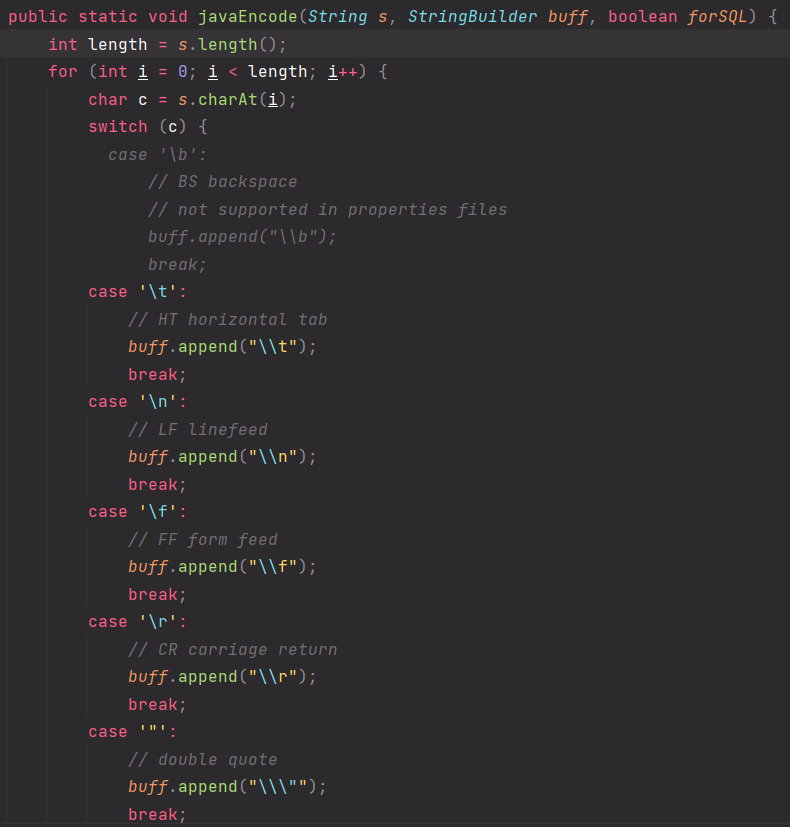
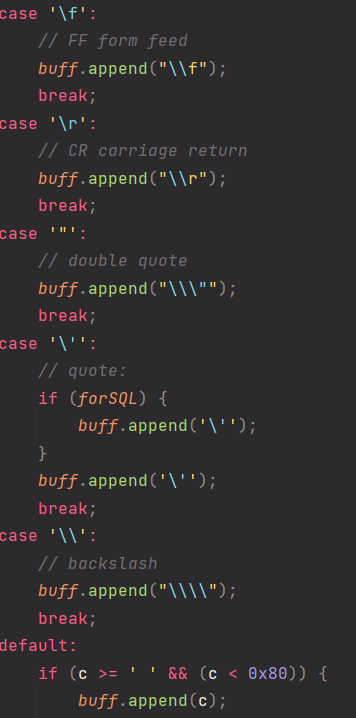
- Error Message 노출 금지
공격자가 SQL Injection을 수행하기 위해서는 데이터베이스의 정보(테이블명, 컬럼명 등)가 필요합니다. 데이터베이스 에러 발생 시 따로 처리를 해주지 않았다면, 에러가 발생한 쿼리문과 함께 에러에 관한 내용을 반환헤 줍니다. 여기서 테이블명 및 컬럼명 그리고 쿼리문이 노출이 될 수 있기 때문에, 데이터 베이스에 대한 오류발생 시 사용자에게 보여줄 수 있는 페이지를 제작 혹은 메시지박스를 띄우도록 하여야 합니다.
- 알고 있는 SQL 안티패턴이 있다면 설명해주세요. ( 이 두가지 외에도 많은 안티패턴이 존재합니다)
"동적 쿼리 문자열 구성"입니다.
이 패턴은 사용자 입력을 받아 동적으로 SQL 쿼리를 문자열로 구성하는 방법으로, 이는 보안 문제를 야기할 수 있습니다.
"패스워드 평문 보관" > 보안 문제와 관련이 있습니다. ( 패스워드에 해시 알고리즘을 적용한 값으로 저장한다)
- 페이지네이션을 구현한다고 했을때 쿼리를 어떻게 작성해야할까요?
<대표적인 구현방법 2가지>(페이지네이션을 구현해본적이 없습니다. 그러나 페이지네이션을 하지 않고 데이터를 전부 가져왔다가 DB에서 가져온 데이터가 짜 놓은 HTML 화면 밖으로 빠져나가서 어떻게 해야되나 고민해 본 적은 있습니다. )
- 서버에서 데이터를 가져올 때 모든 데이터를 다 가져올 수는 없습니다.
그렇기에 서버와 클라이언트 모두에게 특정한 정렬 기준에 따른 지정된 갯수의 데이터를 가져오는 것이 필요합니다. 흔히 이를 페이지네이션(Pagination)이라고 합니다.
1. 오프셋 기반 페이지네이션
DB의 offset 쿼리를 사용해서 페이지 단위로 구분하여 요청 / 응답하게 구현
2. 커서 기반 페이지네이션
클라이언트가 가져간 마지막 row의 순서상 다음 row들을 n개 요청/응답하게 구현
- 서버에서 데이터를 가져올 때 모든 데이터를 다 가져올 수는 없습니다.
아 그래서 둘 중 어느 것을 어떤 상황에 골라야 하나요?
