Regularization & Normalization
Regularization는 정칙화라고 불리며, 오버피팅을 해결하기 위한 방법 중의 하나이다.
L1, L2 Regularization, Dropout, Batch normalization 등이 있다.
이 방법들은 모두 오버피팅을 해결하고자 하는 방법 중에 하나이다.
Normalization는 정규화라고 불리며, 데이터의 형태를 좀 더 의미 있게 혹은 트레이닝에 적합하게 전처리하는 과정이다. 데이터를 z-score로 바꾸거나 minmax scaler를 사용하여 0과 1사이의 값으로 분포를 조정한다.
L1 Regularization
L1 Regularization은 sklearn에서 Lasso라고 자주 불린다.
L1 regularization (Lasso)의 정의
여기서 주목해야할 점은 이며, 이 부분이 없다면 Linear regression과 동일하다.
참고
norm은 벡터나 행렬, 함수 등의 거리를 나타내는 것. Lp norm 의 정의는 아래와 같으며 자세한 내용은 링크를 확인하자.
인 경우 L1 norm은 로 나타낼 수 있으며,
이는 위에서 보인 에 들어가 있는 수식과 일치한다.
때문에 이므로 L1 Regularization이라고 부르는 것이다.
하지만 사이킷런(sklearn)이나 케라스(keras), 텐서플로우(tensorflow) 등의 패키지에서는 Lasso 라는 이름을 더 자주 사용한다.
주의할 점! L1 Regularization을 사용할 때는 X(입력 데이터)가 2차원 이상인 여러 컬럼 값이 있는 데이터일 때 실제 효과를 볼 수 있다는 점을 알아두자.
L2 Regularization
L2 Regularization(Ridge) 의 정의
L2 Regularization에서 부분이 핵심이다.
L1 / L2 Regularization의 차이점

위의 그림은 L1과 L2의 차이점을 나타낸 그래프이다.
- L1 Regularizaion(Lasso)는 를 이용하여 마름모 형태의 제약조건이 생긴다.
- L2 regularization은 이므로 원의 형태이다.
- L2는 0에 가지는 않고 0에 가깝게 감을 확인할 수 있으며, 또한 제곱이 들어가 있기 때문에 절댓값으로 L1 Norm을 쓰는
Lasso보다는 수렴이 빠르다.
- L1 Regularization은 가중치가 적은 벡터에 해당하는 계수를 0으로 보내면서 차원 축소와 비슷한 역할을 한다.
- L2 Regularization은 0이 아닌 0에 가깝게 보내지만 제곱 텀이 있기 때문에 L1 Regularization보다는 수렴 속도가 빠르다.
데이터에 따라 적절한 Regularization 방법을 활용해야 한다.
Extra : Lp norm
Norm이라는 개념은 벡터뿐만 아니라 함수, 행렬에 대해서 크기를 구하는 것이다.
딥러닝에서는 주로 벡터, 행렬의 Norm정도만 알아두면 된다.
vector norm
Norm으로 아래와 같이 된다.
matrix norm
행렬의 norm의 경우는 벡터와 조금 다르며, 주로 , 만 알아두면 된다. 현재 는 X 행렬이다.
- 인 경우에는 컬럼(column)의 합이 가장 큰 값이 출력되고
- 인 경우에는 로우(row)의 합이 가장 큰 값이 출력된다.
Dropout
드롭아웃(Dropout) 기법은 2014년도에 나온 논문이다.
- 제목 : Dropout: A Simple Way to Prevent Neural Networks from Overfitting
- 발표 : 2014년
- 링크
드롭아웃 기법이 나오기 전의 신경망은 fully connected architecture 로 모든 뉴런들이 연결되어 있었지만, 드롭아웃이 나오면서 확률적으로 랜덤하게 몇 가지의 뉴럴만 선택하여 정보를 전달하게 되었다. dropout은 이름 그대로 몇 가지의 값들을 모든 뉴런에 전달하는 것이 아닌 확률적으로 버리면서 전달하는 기법이다.
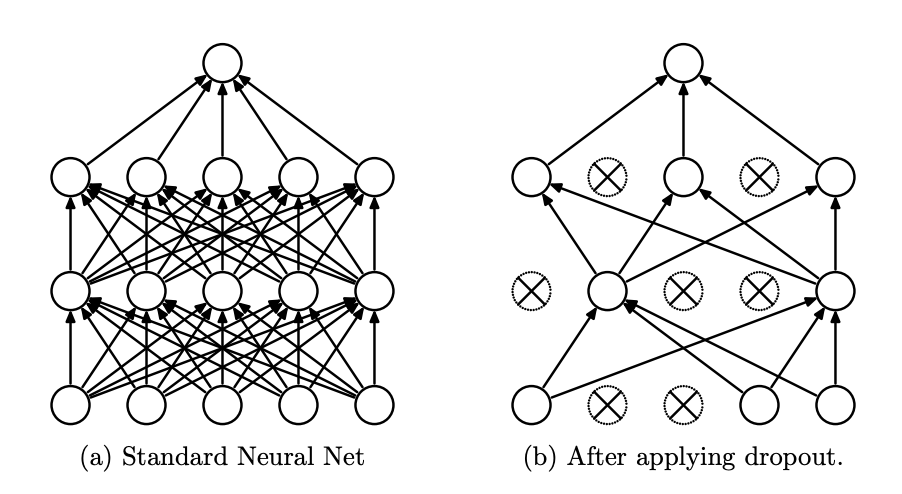
출처 : https://jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf
드롭아웃은 오버피팅을 막는 Regularization layer 중 하나이다.
- 확률을 너무 높이면, 제대로 전달되지 않으므로 학습이 잘되지 않고,
- 확률을 너무 낮추는 경우는 fully connected layer와 같아진다.
- fully connected layer에서 오버피팅이 생기는 경우에 주로 Dropout layer를 추가해준다.
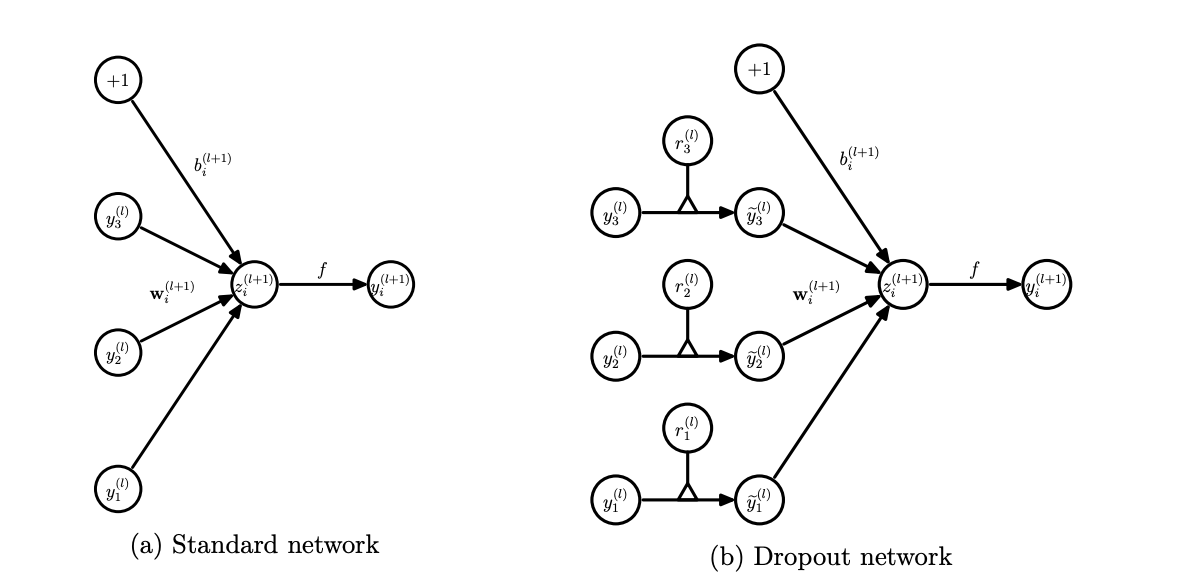
출처 : https://jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf
dropout의 논문이 나온지 꽤 지났기 때문에 이것을 이용한 여러 프레임 워크들이 있다.
keras dropout
Batch Normalization
Batch Normalization은 gradient vanishing, explode 문제를 해결한다.
- 제목 : Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- 발표: 2015년
- 링크
- Input: Values of x over a mini-batch: Parameters to be learned:
- Output:
1. mini-batch mean
2. mini-batch variance
3. normalize
4. scale and shift
수식에서 중요한 부분은 normalize 부분에서 분모에 이 추가 된 것이며, 이 부분으로 인해 normalize 과정에서 gradient가 사라지거나(vanishing), 폭등하는(explode) 사태를 방지할 수 있다.
