파일시스템
pandas & csv
데이터 합치기 : merge, join, concat
pd.merge()
pd.merge(df1, df2)pd.merge(how='inner')
공통의 데이터에 대해서만 데이터를 합치는 것
pd.merge(df1, df2, how='inner')pd.merge(how='outer')
전체 데이터에 합치는 연산
pd.merge(df1, df2, how='outer')df.join()
merge() 대신 join() 메소드를 이용이 가능하다.
df1.join(df2, how='outer', lsuffix='_caller', rsuffix='_other')df.concat()
이어 붙이기
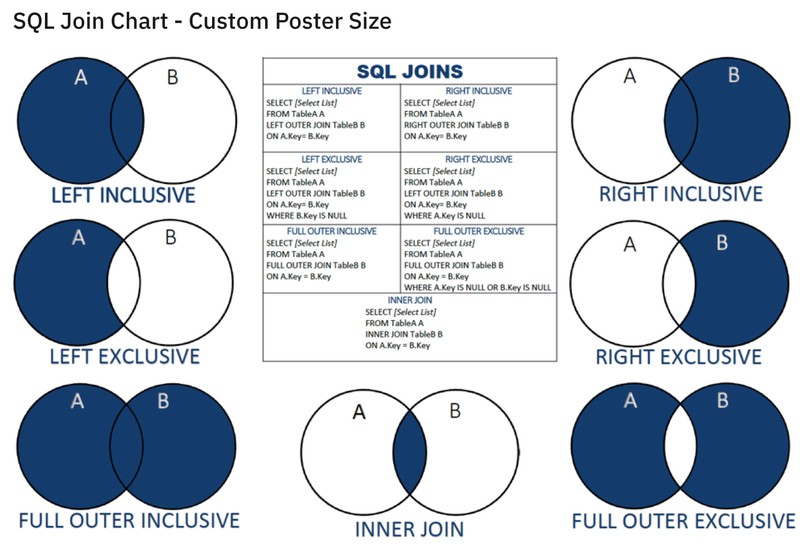
pd.concat([df1,df2])join에 대한 내용은 밑에 이미지를 첨부하겠다.
Pandas의 유용한 기능들
필터링 연산
1. df'컬럼 명'
df['A']2. loc()
행 또는 열(컬럼)을 지정, 데이터를 추출
df.loc[[행],[열]]print(df.loc[0])
print(df.loc[0, 'B'])
print(df.loc[:, 'A'])3. iloc()
정수 인덱스 를 사용하여 행 또는 열(컬럼)을 지정, 데이터를 추출
df.iloc[[행],[열]]print(df.iloc[0])
print(df.iloc[:, 0])
print(df.iloc[0, 'B']) # error
print(df.iloc[0, 1])그룹연산: groupby(), apply()
groupby()
- groupby()객체를 생성 한 후
- groupby()객체의 연산을 수행한다.
- max(), min(), sum(), mean()
- apply()
apply()
df.groupby(['Columns1']).max().apply(np.sqrt)다중 사용자 환경
데이터 관리 시스템(DBMS)를 이용하여 다수 사용자들에게 대응할 수 있는 실시간 트랜잭션 처리 기능을 갖춘 시스템을 이용하여 다중 사용자 환경에 대응할 수 있다.
SQL
SQL문 종류
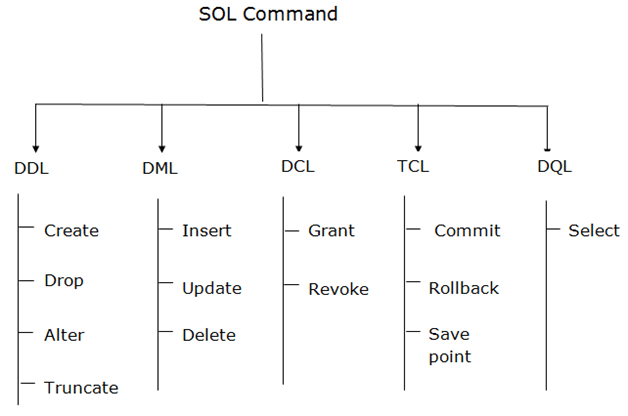
출처 : https://www.javatpoint.com/dbms-sql-command
DDL(Data Definition Language, 데이터 정의어)
테이블이나 관계의 구조를 생성하는 데 사용.
- 테이블, 데이터베이스, 사용자에 대한 생성, 삭제
- 제약조건(constraint),
- 권한(permission)을
위에 내용들을 설정한다.
DML (Data Manipulation Language, 데이터 조작어)
테이블의 데이터를 조회, 삽입, 갱신, 삭제할 때 사용하며, 이런 식의 데이터의 기본 조작 행위를 CRUD라고 줄여서 부릅니다.
- 생성(Create): INSERT
- 조회(Read): SELECT
- 갱신(Update): UPDATE
- 삭제(Delete): DELETE
파이썬으로 데이터베이스 다루기
파이썬 DB-API
[API 메인 함수]
- connect(): 데이터베이스의 연결을 만든다.
- cursor(): 질의를 관리하기 위한 커서 객체를 만든다.
- execute(), excutemany(): 데이터베이스에 하나 이상의 SQL명령을 실행한다.
- fetchone(), fetchmany(), fetchall(): 실행 결과를 얻는다.
sqlite3 모듈을 이용한 데이터베이스 연결
connect() : 연결
conn = sqlite3.connect('example.db')cursor() : 커서 객체 만들기
c = conn.cursor()execute(), executemany() : 쿼리 명령어
# Create table
c.execute('''CREATE TABLE stocks
(date text, trans text, symbol text, qty real, price real)''')
# Insert a row of data
c.execute("INSERT INTO stocks VALUES ('2021-01-01','BUY','RHAT',100,35.14)")commit() : 데이터베이스에 반영
conn.commit()close() : 종료
conn.close()