데이터들을 보면 단위가 다른 경우가 종종 있다.
예를 들어, 지출금액, 수입금액, 수출금액 등등의 단위가 서로 다르면 비교하기가 힘들다.
이런 경우 컬럼마다 차이가 크게 나는 데이터들은 모델학습에 문제가 발생할 수도 있으므로,
일반적으로 전처리(Preprocessing) 과정에서 데이터를 정규화해준다.
정규화를 하는 방법은 다양하지만, 가장 잘 알려진 표준화(Standardization)와 Min-Max Scaling을 알아보자. 범주형 데이터에선 작동하지 않는다. 고로 수치형 칼럼들만 골라야 한다.
우선, vgsales라는 비디오게임 매출 데이터를 기반으로 작업한다.
그 중 수치형 데이터들로만 이루어진 컬럼들을 따로 정해주면 아래와 같다.
cols=["NA_Sales", "EU_Sales", "JP_Sales", "Other_Sales", "Global_Sales"]Standardization
데이터의 평균(Mean)은 0, 분산(Variance)은 1로 변환
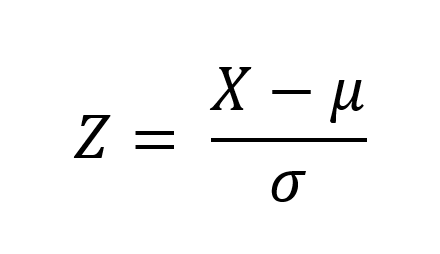
위에 이미지를 코드로 구현해보면 아래와 같다.
vgsales_std = (vgsales[cols] - vgsales[cols].mean())/vgsales[cols].std()<참고사이트>
Min-Max Scaling
데이터의 최솟값(Min)은 0, 최댓값(Max)은 1로 변환
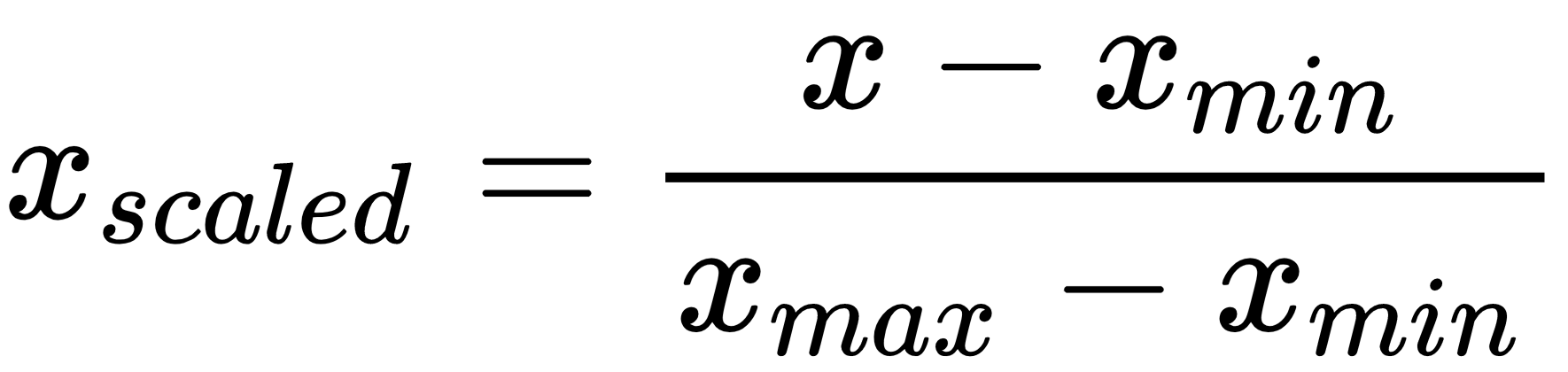
위에 이미지를 코드로 구현해보면 아래와 같다.
vgsales_min_max = (vgsales[cols]-vgsales[cols].min())/(vgsales[cols].max()-vgsales[cols].min())<참고사이트>
근데 위 두 방법을 이미 구현해놓은 package가 있다^_^. 끌어다 쓰자....
scikit-learn을 이용한
Standardization, Min-Max Scaling을 수식을 구현해서 계산하는 방법도 있지만,
scikit-learn의 StandardScaler, MinMaxScaler를 사용하는 방법도 있다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
train = [[10, -10], [30, 10], [50, 0]]
test = [[0, 1]]주의할 점
train 데이터와 test 데이터가 나눠져 있는 경우,
train 데이터를 정규화시켰던 기준 그대로 test 데이터도 정규화 시켜줘야 한다.
scaler.fit_transform(train)
scaler.transform(test)이 역시도 vgsales 데이터들에 적용해보겠다.
[코드]
scaler.fit_transform(vgsales[cols])[결과]
array([[1.00000000e+00, 1.00000000e+00, 3.68884540e-01, 8.00378430e-01,
1.00000000e+00],
[7.00891781e-01, 1.23363198e-01, 6.66340509e-01, 7.28476821e-02,
4.86280672e-01],
[3.82019764e-01, 4.43831840e-01, 3.70841487e-01, 3.13150426e-01,
4.32853862e-01],
...,
[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00],
[0.00000000e+00, 3.44589938e-04, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00],
[2.41021933e-04, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00]])
