1. 관계형 모델
-1. 관계형 모델의 개념
- 실제 세계의 데이터를 관계라는 개념을 사용해서 표현한 데이터 모델
- 하나의 개체(entity)에 관한 데이터를 relation하나에 담아서 DB에 저장
- relation : formal model에 가까움
- SQL : 실질적으로 standatd model(pratical model에 가까움)에 존재함
- practical model과 formal model에는 차이점이 있다
- SQL -> practical model
- realtion -> formal model -> 녹음본
-2. Relation
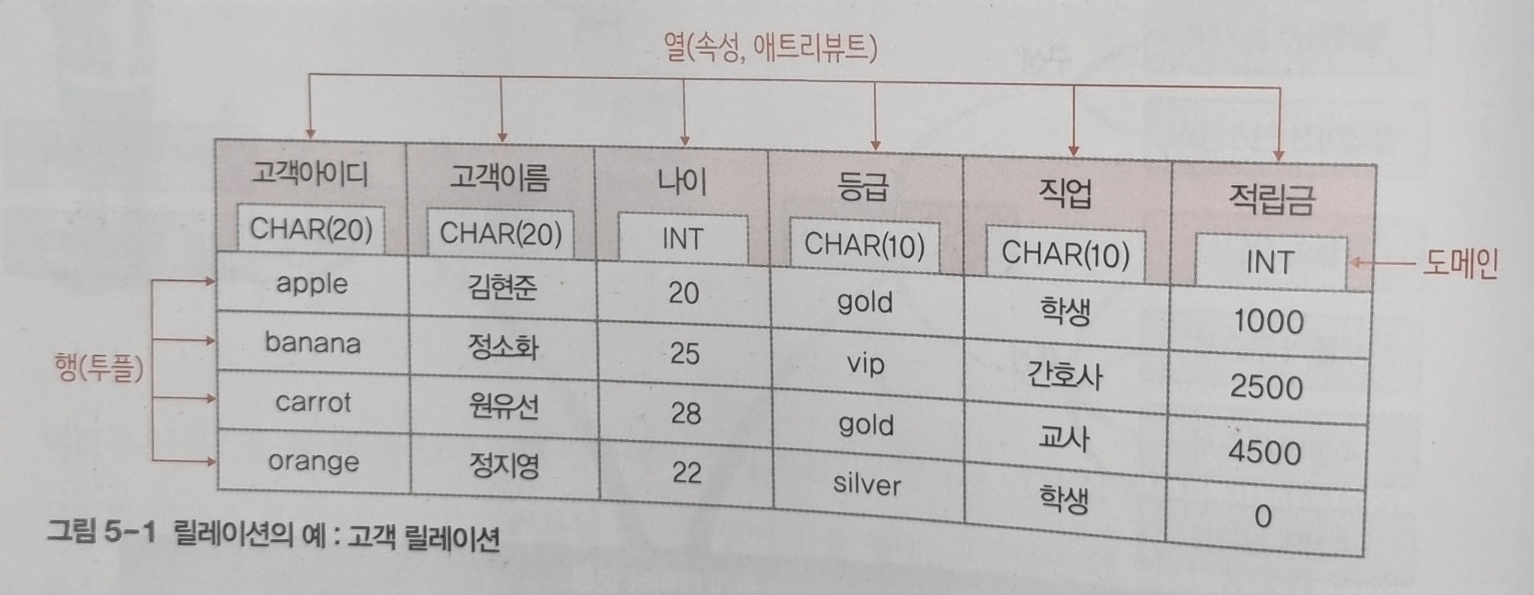
- A table of tuples
- 테이블들이 가진 각각의 columns = 애트리뷰트
- row = tuple
-3. Formal Relational Concepts
-
Domain
: a set of atomic values
엔티티의 속성들이 가질 수 있는 값들의 집합
속성에 대응하는 컬럼에 대한 데이터 타입(Data Type)과 길이 = 일종의 제약조건
두 속성의 도메인이 같다 = 두 속성의 데이터 타입과 길이가 같다
정의된 도메인명은 일반적인 데이터 타입처럼 사용할 수 있음 -
Attribute
: 어떤 대표성을 가진 이름 + relation에서 존재하는 도메인을 가지고 있음
각각의 애트리뷰트 -> Ai
애트리뷰트의 도메인 -> dom(Ai) -
Relation Schema
: Ai(애트리뷰트)의 집합 -> R
R(A1,A2,...,An)으로 표기
R이 가지는 애트리뷰트의 시퀀스 -
카디널리티(cardinality)
: 하나의 relation에서 튜플의 전체 개수
ex) 5-1고객 릴레이션의 카디널리티 = 4 -
예제
STUDENT(Name, SSN, BirthDate, Addr)
- Degree of relation: 4(애트리뷰트 개수 = 4개)
- Tuple t(of R(A1,A2,...,An))
: tuple -> 인스턴스 정보, R -> 스키마 정보
set of values t = <v1, v2, .. vn> -> 특정 애트리뷰트의 domain따르는 value들의 순서가 있는 집합
n-tuple라고 부름
1개의 튜플
- Relation instances r(R): a set of tuples
: relation schema따르는 tuple들의 집합
r(R) = {t1, t2,... tm} -> 스키마 따르는 튜플들의 집합, 어떤 애트리뷰트가 가질 수 있는 값의 공간
r(R) =⊂ dom(A1) x dom(A2) x..x dom(An)
-> 도메인을 곱한 것 = 전체 집합의 subset(부분집합)
-4. Informal Terms
- Table
- Column Header
- All possible Colums Values
- Row
- Table Definition
- Populated Table
-5. Formal Terms
- Relation
- Attribute
- Domain
- Tuple
- Schama of a Relation
- State of the Relation Informal/ Formal 녹음본 + 책
2. 릴레이션의 특징
-1. 릴레이션(table)의 특징
- relation r(R)에 있는 tuple들의 순서는 의미 x
- relaion schema R 에 있는 attribute들의 순서는 중요함
+ 각 tuple들 안에 있는 value들의 순서도 중요
-> 애트리뷰트들 순서 바꾸면 value들의 순서도 바뀌어야 하기 때문 - 한 tuple안에 있는 각 value들은 atomic(더 이상 나뉘지 x)하고, null value가 있으면 좋지 않음
-> 이때 null value : unknown, inapplicable - 표현 방법
: t[Ai] = vi -> tuple t 에서 Ai에 해당하는 value vi를 구해라
여러개 물어보는 경우
-> t[Au,Av,..,Aw] 질의로 얻어내려고 선택한 attribute value
릴레이션 이름(A1, A2, ..., An) -> 릴레이션 스키마
-2. 릴레이션 인스턴스
- 어느 한 relationd에 존재하는 튜플들의 집합
- 릴레이션 인스턴스에 포함된 튜플 -> 릴레이션 스키마에서 정의한 각 속성에 대응하는 실제값으로 구성
- 현재 릴레이션의 실제 내용 쉽게 파악 가능
- relation instance = relation extension(외연)
-3. 릴레이션의 특성
- 튜플의 유일성
: 하나의 릴레이션에는 동일한 튜플이 존재할 수 없다 - 튜플의 무순서
: 하나의 릴레이션에서 튜플 사이의 순서는 무의미하다 - 속성의 무순서
: 하나의 릴레이션에서 속성 사이의 순서는 무의미함 - 속성의 원자성
: 속성 값으로 원자값(더 이상 분해할 수 없는 값) 만 사용할 수 있다
3. 관계형 무결성 제약조건
- 제약조건: 옮은 값 유지하게 하는 조건으로, 지켜져야만 함
-1. Key 제약조건
: key(후보키)를 꼭 가져야 함
- R의 슈퍼키(SK)
- 유일성을 만족하는 key -> unique하게 identify할 수 있어야 함
- tuple들을 unique하게 identify할 수 있어야 함
- R의 후보키 (candidate key)
- 최소화된 superkey
ex) 슈퍼키 고객아이디 + 고객이름 -> 후보키 고객아이디- superkey를 구성하는 attribute중 하나라도 빼면 key의 역할을 못하는 최소한의 key
- 여러개가 있을 수 있음
- 기본키 (Primary Key)
- 기본키, 후보키 중 기본적으로 사용하기 위해 선택한 키
- 속성 이름에 밑줄을 그어 표시
- 널 값을 가질수 있거나, 값이 자주 변경되는 키는 기본키로 부적합함
- 단순한 후보키가 좋음
- 대체키
- 기본키로 선택되지 못한 후보키들
- 왜래키
- 어떤 릴레이션에 소속된 속성 or 속성의 집합 -> 다른 릴레이션의 기본키가 되는 키
- 다른 릴레이션의 기본키를 그대로 참조하는 속성의 집합 = 왜래키
- 릴레이션들 사이의 관계를 표현하기 위해 필요함
- 왜래키는 PK를 참조하지만 기본키가 아니기 때문에 NULL값을 가질 수 있음
-2. 엔티티 무결성
: key가 Null이 되면 안됨, 모든 테이블이 기본 키(primary key)를 가져야 함 -> 모든 tuple이 unique하게 identify할 수 있는 key 및 attribute value가 unique하게 구분되어야 함
- Relational Database Schema
-> S = database이름, Ri = Relation의 schema, S = {R1,R2,...,Rn} - 엔티티 무결성 제약조건 만족시키려면 새로운 튜플이 삽입되는 연산과 기존 튜플의 기본키 속성 값이 변경되는 연산이 발생할 때 기본키에 널 값이 포함되는 상황에서는 연산의 수행을 거부하면 됨
-3. 참조 무결성
: R1(부르는/참조하는)안에 있는 FK attribute값은 R2(불리워지는/참조되는)안에 나타는 PK attribute값만 가져야 함, 이때 foreign key -> 참조 되는 테이블의 primary key 출신
-> 모든 외래 키 값은 참조하는 릴레이션의 기본키(primary key)의 속성(애트리뷰트)값과 일치하는 값이거나 NULL값 둘 중 한 상태에만 속해야 함
-> 왜래키는 참조 가능한 값만 가져야 함
-4. relation에 대한 갱신 연산
- 데이터에 대한 처리 요구 = 질의(query)
- 관계 대수: 원하는 결과를 얻기 위해 데이터의 처리 과정을 순서대로 기술
- 관계 해석: 원하는 결과를 얻기 위해 처리를 원하는 데이터가 무엇인지 기술
4. 관계 대수와 연산자
-1. 관계 대수
- 원하는 결과를 얻기 위해 릴레이션을 처리하는 과정을 순서대로 기술하는 언어
- 연산자들의 집합으로 정의
- 피연산자(연산의 대상이 되는 것) -> 릴레이션
- 관계 대수는 릴레이션을 연산
-2. 일반 집합 연산자
- 연산을 위해 피연산자 2개 필요(일반 집합 연산자는 2개의 릴레이션 연산)
- 합집합, 교집합, 차집합은 피연산자인 2개의 ㄹ리레이션이 합병 가능해야 함
-> 합병 가능하다 =
두 릴레이션의 차수가 같다, 2개의 릴레이션에서 서로 대응되는 속성의 도메인이 같다(속성 이름은 달라도 됨)
1. 합집합
- R과 S의 합집합
-> 릴레이션 R에 속하거나 릴레이션S에 속하는 모든 튜플로 결과 릴레이션 구성 - 중복된 건 한번만
2. 교집합
- R과S의 교집합
-> R과S에 공통으로 속하는 튜플로 결과 릴레이션 구성 - 교집합 연산 결과 degree = R,S의 degree
- 결과 cardinality < R,S의 cardinality
3. 차집합
- R과S의 차집합(순서 중요)
-> R-S의 경우 R에는 존재하지만 S에는 존재하지 않는 튜플들로 결과 릴레이션 구성 - 차집합 연산 결과 degree = R,S의 degree
- 차집합 연산 결과 cardinality <= R,S의 cardinality
4. 카티션 프로덕트
- R X S
- R과S에 속한 튜플들 모두 연결해서 만들어진 새로운 튜플로 결과 relation구성
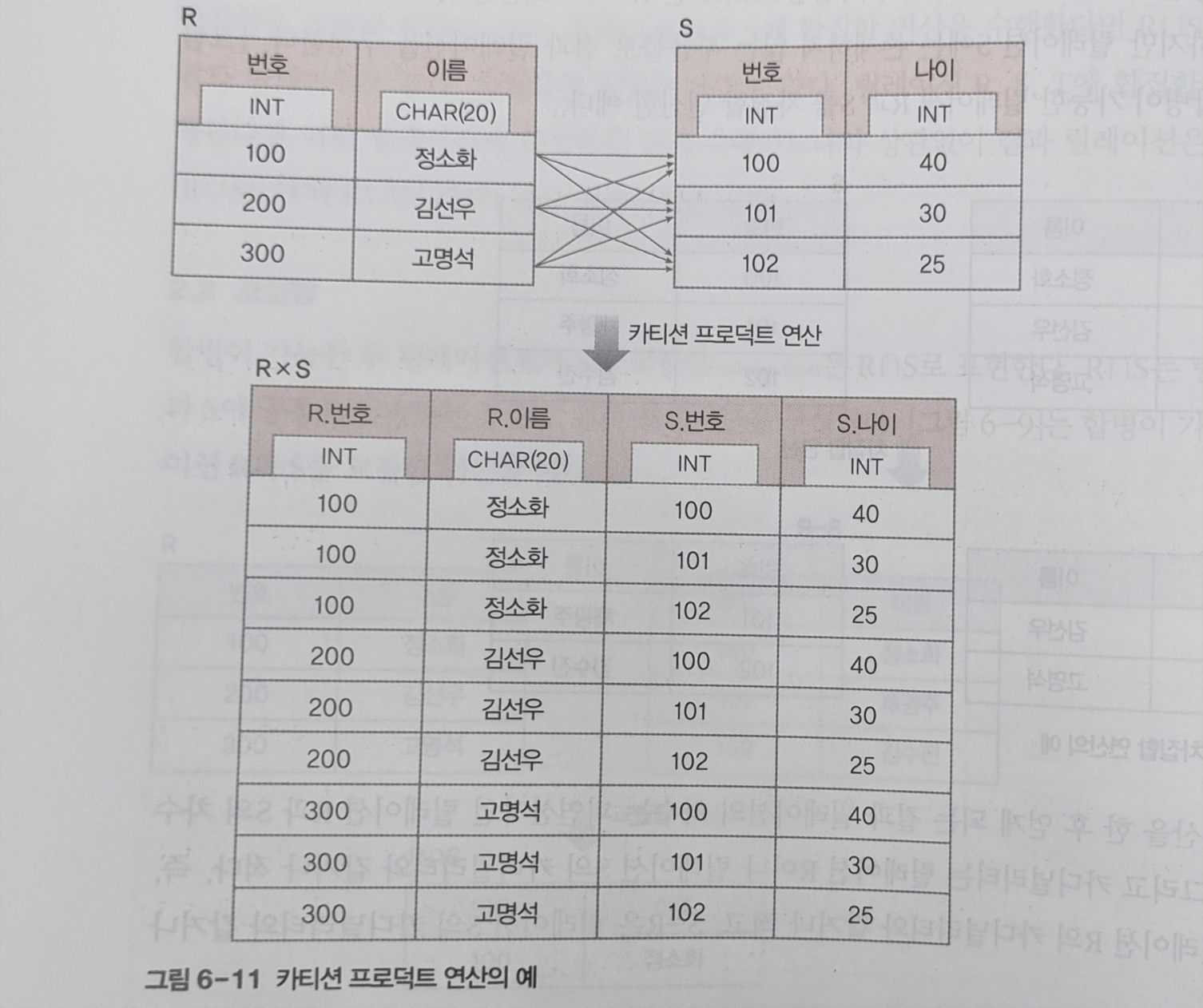
- 결과 릴레이션 애트리뷰트 -> 릴레이션 이름.속성이름 으로 표기
- 결과 릴레이션 degree = R + S 의 degree
- 결과 릴레이션 cardinality = R x S 의 Cardinality
-3. 순수 관계 연산자
- 릴레이션의 구조, 특성 이용하는 연산자
- select, project, join, division
- 릴레이션에 저장된 데이터 처리하는데 사용됨
1. SELECT
- 릴레이션에서 주어진 조건만 만족하는 튜플만 선택 -> 결과 릴레이션 구성
- 해당 릴레이션의 수평적 부분집합( 릴레이션을 수평으로 절단한 모양)
- 릴레이션 where 조건식 << 이렇게 작성
- 만약 조건식을 속성, 상수의 비교로 구성한다면 속성들의 도메인이 같아야 함(그래야 비교 가능하니까)
2. PROJECT
- 릴레이션에서 선택한 속성에 해당하는 값, 결과 릴레이션 구성
- 결과 릴레이션 -> 주어진 릴레이션의 일부 열로만 구성
- 해당 릴레이션에서 수직적 부분집합 생성
- 릴레이션[속성리스트] << 로 작성
3. JOIN
- 관계가 있는 여러 릴레이션 사용
- 조인 속성을 이용해 두 릴레이션 조합 -> 하나의 결과 릴레이션 구성
- 조인 속성 : 두 릴레이션이 공통으로 가지고 있는 속성 -> 두 릴레이션이 관계가 있음을 나타냄
- 조인 연산의 결과 릴레이션 : 피연산자 릴레이션에서 조인 속성의 값이 같은 튜플만 연결하여 만들어진 새로운 튜플 포함 ( 조인 속성과 관련된 튜플들 포함)
- 세타조인
- 주어진 join조건 만족하는 두 릴레이션의 모든 튜플 연결한 새로운 튜플로 결과 릴레이션 구성한 것
- 속성이 중복되어서 나타날 수 있음
4. DIVISION
- R÷S로 표기
- S의 모든 튜플과 관련있는 R의 튜플로 결과 릴레이션 구성
- 이때 R이 S의 모든 속성을 포함하고 있어야 연산이 가능함
= S의 속성과 도메인이 같은 속성을 R이 포함하고 있어야 함
5. SQL
- DDL : 테이블 생성, 변경, 제거
- DML : 테이블에 새 데이터 삽입, 저장된 데이터 수정,삭제,검색
- DCL : 데이터 접근 권한 사용자별로 부여, 취소 기능 제공, 데이터베이스 관리자가 주로 사용
-1. SQL에서 Schema와 Catalog의 개념
- SQL -> ;(세미콜론)으로 끝남
- table들 끼리 관계성이 있다면 묶어서 한 특정 DB에 둠
- catalog : SQL환경에서 schema들을 모아놓은 곳
-2. SQL에서 table 생성하는 방법
- CREATE TABLE 테이블 이름 (
속성 이름 데이터 타입 [NOT NULL][DEFAULT 기본값] -> 기본 제약조건
[PRIMARY KEY(속성 리스트)] -> 기본키, table당 1개씩만 존재
[UNIQUE (속성 리스트)] -> 대체키, 테이블 당 여러개 존재 o
[FORIGN KEY(속성 리스트) REFERENCES 테이블 이름(속성 리스트) [ON DELETE 옵션] _ [ON UPDATE 옵션]] -> 왜래키, 테이블에 여러개 존재 가능, forign key인 속성의 이름과 어떤 테이블을 참조했는지 적어줘야 함
[CONSTRAINT 이름] _ [CHECK 조건] -> 데이터 무결성을 위한 제약조건, 테이블에 여러 개 존재 가능
); -> SQL문은 세미콜론으로 문장 끝 표시
-
base tables
: create table문으로 정의한 테이블
base relation이라고 부름
base table의 relation과 tuples는 DBMS에 의해 생성되고 file형식으로 저장됨 -> 만약 이 file을 열려면 DBMS system이 필요함 -
Vitrual relations
: 뷰 라고 부름, base table를 기반으로 만들어진 가상 테이블
논리적으로만 존재
view statement를 통해 생성됨
file이 아님 -> file로 유지 x, API처럼 루틴으로 운용
뷰를 통해 base table의 내용을 쉽게 검색할 수 있지만 변경은 제한적임 -
attribute의 data type
| 데이터 타입 | 의미 |
|---|---|
| INT | 정수 |
| CHAR(n) | 길이가 n인 고정 길이 문자열 |
| VARCHAR(n) | 최대 길이가 n인 가변 길이 문자열 |
| FLOAT(n) | 길이가 n인 부동 소수점 실수 |
| DATE | 연,월,일로 표현되는 날짜 |
| TIME | 시, 분, 초로 표현되는 시간 |
| DATETIME | 날짜와 시간 |
-3. SQL 에서 속성 데이터의 유형과 도메인
1. 속성 데이터 유형
- Bit-string data types
- Boolean data types
- DATE data type
- Additional data types
- Timestamp data type : 기본 날짜형 확장한 형태의 데이터 타입
- INTERVAL data type : 날짜, 시간, timestamp 임의로 +-
- DATE, TIME, Timestamp, INTERVAL같은거는 타입 맞추거나 타입 연산을 해줘야 비교 가능
2. 도메인
-
도메인 : 하나의 속성이 취할 수 있는 동일한 타입의 원자값들의 집합
-
도메인을 통해 애트리뷰트(속성)의 데이터 타입을 쉽게 바꿀 수 있음
-
임의의 애트리뷰트에서 취할 수 있는 값의 범위가 SQL에서 지원하는 전체 데이터 타입의 값이 아니고 일부분 일 때, 사용자는 그 값의 범위를 도메인으로 정의할 수 있음
-
정의된 도메인명 = 일반적인 데이터 타입처럼 사용
-
도메인 생성문
-> CREAT DOMAIN 도메인명 데이터_타입
[DEFAULT 기본값][CONSTRAINT VALID-도메인명 CHECK(범위 값)]; -
예) 성별을 '남' 또는 '여'와 같은 정해진 한 개의 문자로 표현되는 도메인 SEX를 정의하는 SQL문
CREATE DOMAIN SEX CHAR(1) // 정의된 도메인은 문자형이고 크기는 1이다.
DEFAULT '남' //도메인 SEX를 지정한 속성의 기본값은 '남' 이다.
CONSTRAINT VALID-SEX CHECK(VALUE IN ('남','여'));
//SEX를 지정한 속성에는 '남', '여'중 하나의 값만을 저장할 수 있다
- 4. SQL의 제약 조건
- 관계 데이터 모델에서는 3가지의 constraint types가 존재
- key constraint
- entity integrity constraint
- referential integrity constraints
- CREATE TABLE문으로 테이블 정의할 때 CHECK 키워드로 특정 속성에 대한 제약조건 지정 가능 -> 테이블에는 CHECK로 지정한 제약조건 만족하는 튜플만 존재하게 됨
- CREATE TABLE문으로 테이블 정의할 때 CONSTRAINT 키워드와 함께 고유의 이름 부여 가능 -> 제약조건 여러 개 지정할 때 고유의 이름 부여하면 테이블 생성 이후 제약조건 수정, 제거 시 식별 용이
- 실제로 DB를 운용할 때 constraint 넣어줘야 함
-5. SQL에서 쿼리 검색
- SELECT문 사용
- SELECT문 -> database로 부터 정보를 검색해서 가져오는 것
- 기본형식: SELECT [ALL | DISTINCT] 속성리스트
FROM 테이블리스트; - SELECT 키워드 + 검색하고 싶은 속성의 이름을 콤마로 구분하여 차례로 나열, FROM키워드 + 검색하고 싶은 속성이 있는 테이블의 이름을 콤마로 구분하여 나열
- SQL에서 튜플 -> 중복 o, relational model에서 튜플 -> 중복x
- SQL튜플에서는 중복되는 내용 key로 식별/구분
-6. SQL에서 테이블 연산
1. CREATE
- 테이블 이름, attribute, attribute의 data type정함
- ()로 시작/끝 명시
- Constraint NOT NULL은 attribute타입 우측에 쓸 수 있음
- attribute 콤마로 구분
- CREATE UNIQUE INDEX명령어 사용 -> key attribute명시할 수 있음
= index를 만들되(create index) 똑같은 값은 허용하지 않음(unique)
2. DROP
- 테이블의 정의를 지우는 연산
- 구조의 삭제(인스턴스의 삭제 아님) -> 싹 다 지우는거
- DROP TABLE EMPLOYEE RESTRICT -> EMPLOYEE 테이블이 참조되는 경우 삭제되지 않음
- DROP TABLE EMPLOYEE CASCADE -> EMPLOYEE 테이블과 관련된 거 모두 찾아내서 삭제
3. ALTER TABLE
-
테이블 수정
-
컬럼 추가 (Add)
ALTER TABLE table_name ADD COLUMN ex_column varchar(32) NOT NULL; -
컬럼 변경 (Modify)
ALTER TABLE table_name MODIFY COLUMN ex_column varchar(16) NULL; -
컬럼 이름까지 변경 (Change)
ALTER TABLE table_name CHANGE COLUMN ex_column ex_column2 varchar(16) NULL; -
컬럼 삭제 (Drop)
ALTER TABLE table_name DROP COLUMN ex_column; -
테이블 이름 변경 (RENAME)
ALTER TABLE table_name1 RENAME table_name2;
