Scikit-learn 라이브러리의 내장 데이터셋인 iris 데이터셋을 가지고 통계적인 수치도 뽑아보고 그래프도 그려보면서 가지고 놀아보기
토이 데이터셋이라 아무렇게나 돌려봐도 된다.
iris 데이터셋

그렇다고 한다.
데이터 구조 및 정보 확인
라이브러리 및 데이터셋 불러오기
from pandas import Series, DataFrame
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
iris = load_iris()
df = pd.DataFrame(iris['data'], columns = iris['feature_names'])
df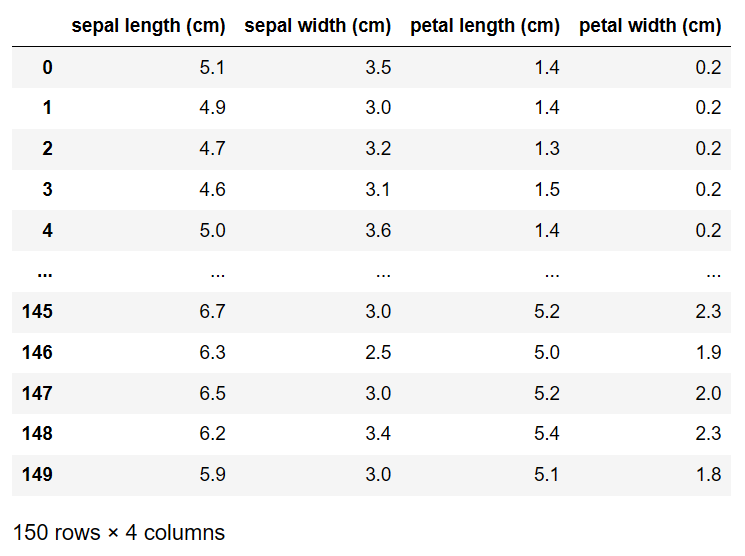
데이터 정보확인
df.info()
간단한 통계 수치 확인하기
df.describe()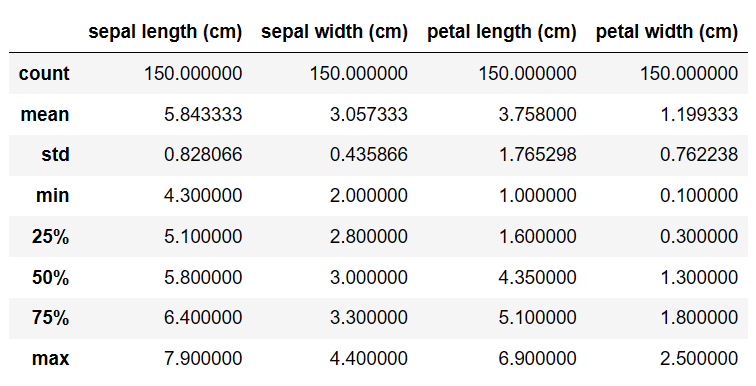
필터링
-
새로운 열(class_name) 추가
(target 열의 각 원소에 해당하는 종을 매핑하여 추가)df['target'] = iris['target'] df['class_name'] = df['target'].apply(lambda idx : iris['target_names'][idx]) df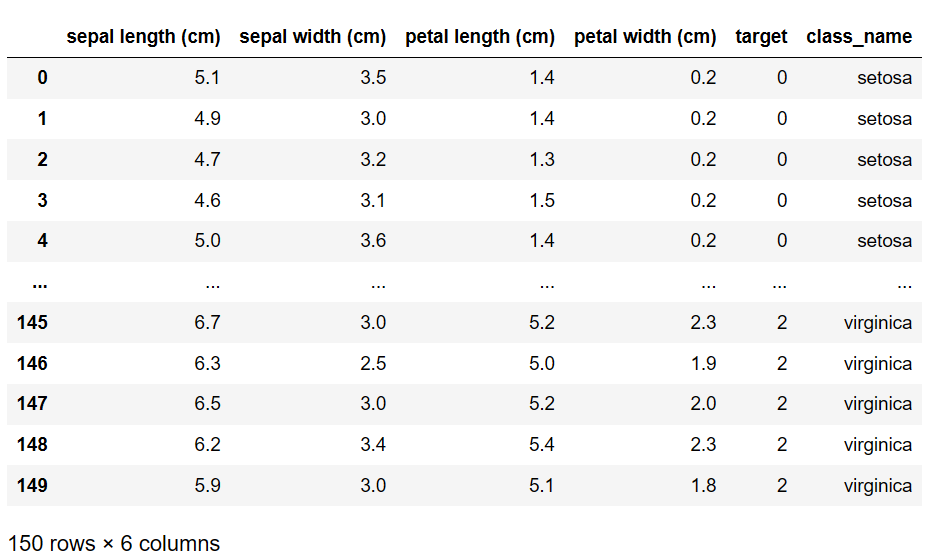
- iris['target_name']에 대하여

- iris['target_name']에 대하여
-
'species'가 'setosa'인 행들만 선택하여 새로운 데이터프레임 만들기
setosa_df = df[df['class_name'] == 'setosa'] setosa_df
(이하 생략)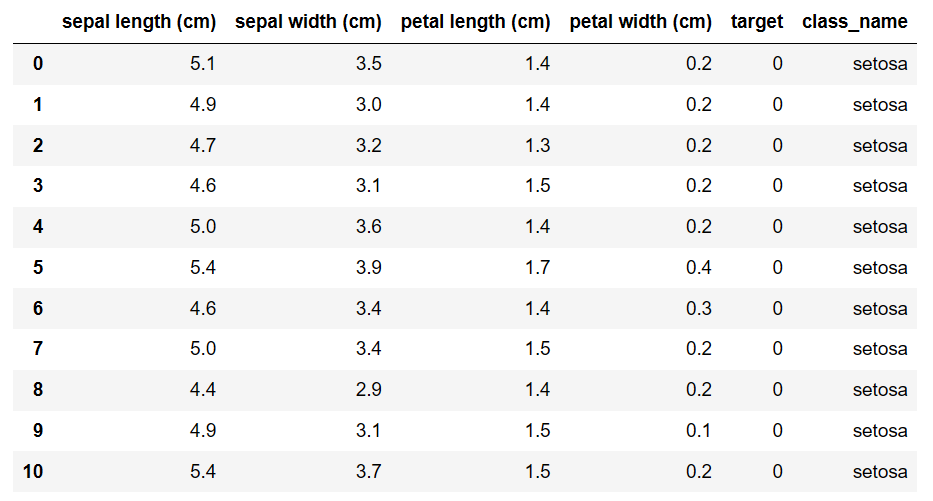
그룹별 통계량 계산하기
-
각 품종('species')별로 'sepal length'의 평균을 계산하기
sepal_length_mean = df.groupby('class_name')['sepal length (cm)'].mean() sepal_length_mean
새로운 열 추가하기
-
각 행의 'sepal length'와 'sepal width'의 합을 계산하여 새로운 열 'sepal sum'을 추가하기
sepal_length_mean = df.groupby('class_name')['sepal length (cm)'].mean() sepal_length_mean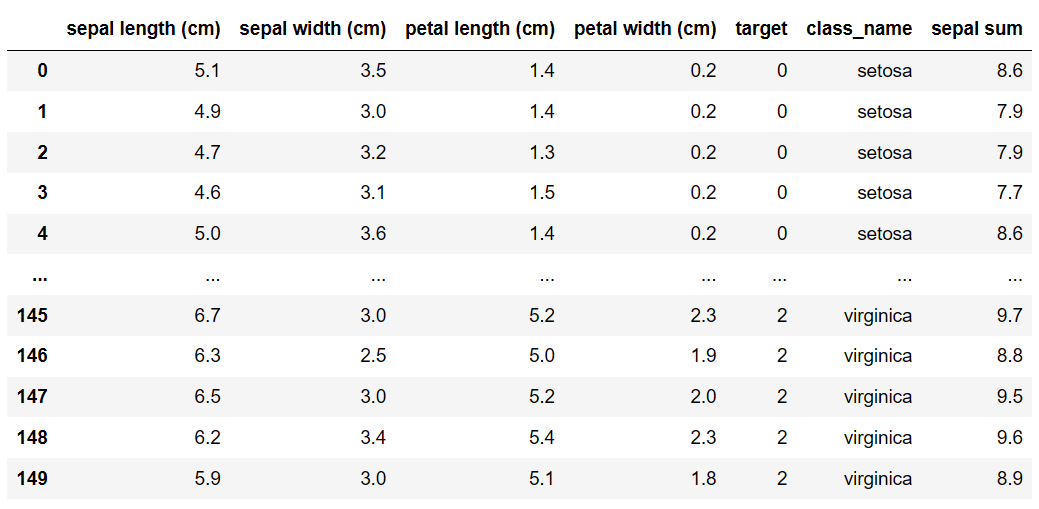
데이터 정렬하기
-
'petal length' 기준으로 데이터프레임을 내림차순으로 정렬하기
sorted_df = df.sort_values(by= 'petal length (cm)', ascending= False) sorted_df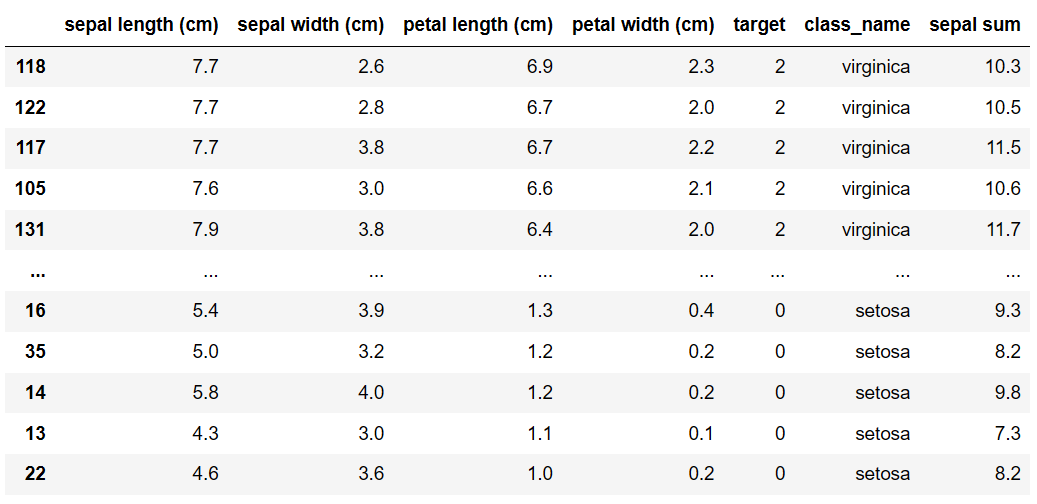
특정 값 세기
-
각 품종('species')별로 몇 개의 샘플이 있는지 세어보기
species_counts = df['class_name'].value_counts() species_counts
데이터 결합하기
-
'sepal length'와 'petal length'의 평균을 계산한 후, 이를 새로운 데이터프레임으로 결합하기
# 평균 계산 sepal_length_mean = df['sepal length (cm)'].mean() petal_length_mean = df['petal length (cm)'].mean() # 데이터프레임으로 변환 mean_df = pd.DataFrame({ 'Mean Sepal Length': [sepal_length_mean], 'Mean Petal Length': [petal_length_mean] }) mean_df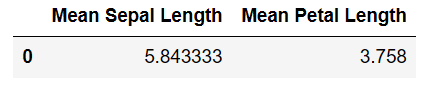
피벗 테이블 만들기
-
각 품종별 'sepal length'와 'petal length'의 평균을 피벗 테이블로 만들기
pivot_table = df.pivot_table(index='class_name', values=['sepal length (cm)', 'petal length (cm)'], aggfunc='mean') pivot_table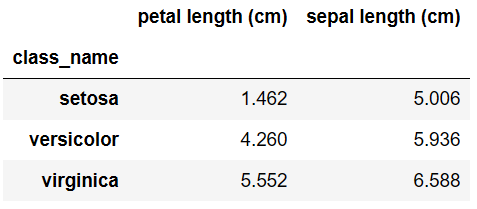
결측값 처리
-
'sepal width' 열에 임의로 결측값을 10개 추가하고, 결측값을 처리하는 방법을 두 가지 이상 적용해 보기
# 결측값 추가 df_with_nan = df.copy() df_with_nan.loc[np.random.choice(df_with_nan.index, 10), 'sepal width (cm)'] = np.nan # 추가 됐는지 확인 missing_values = df_with_nan.isna().sum() missing_values
# 방법 1: 평균값으로 대체 mean_sepal_width = df_with_nan['sepal width (cm)'].mean() df_mean_imputed = df_with_nan.fillna(mean_sepal_width) print("평균값 대체 결과:") df_mean_imputed.head()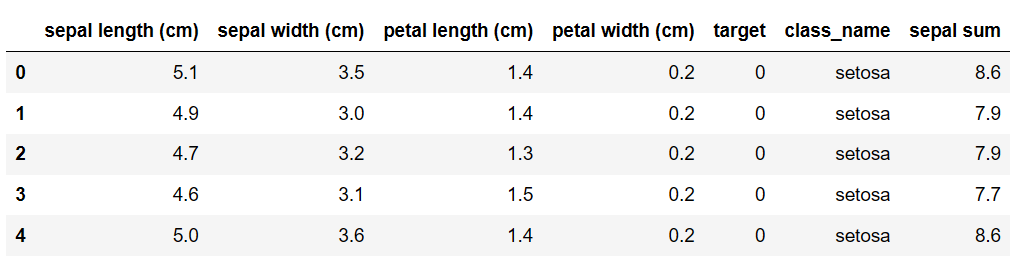
mean_sepal_width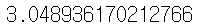
# 방법 2: 중앙값으로 대체 median_sepal_width = df_with_nan['sepal width (cm)'].median() df_median_imputed = df_with_nan.fillna(median_sepal_width) print("중앙값 대체 결과:") df_median_imputed.head()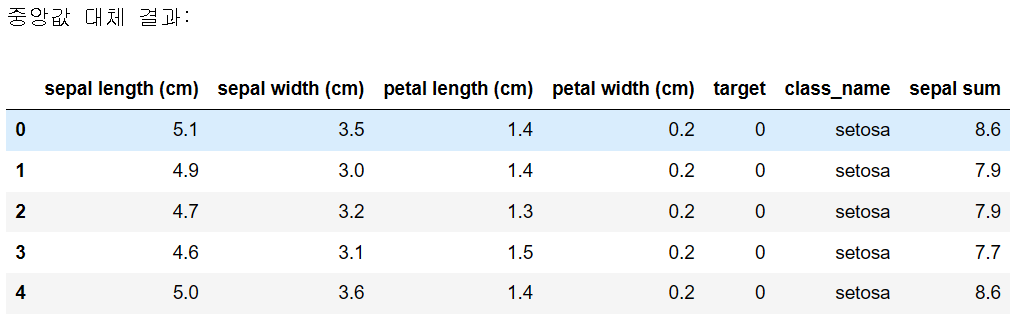
median_sepal_width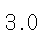
# 확인 # 평균값으로 대체한 데이터프레임의 'sepal width (cm)' 열 추출 sepal_width_mean = df_mean_imputed['sepal width (cm)'] # 중앙값으로 대체한 데이터프레임의 'sepal width (cm)' 열 추출 sepal_width_median = df_median_imputed['sepal width (cm)'] # 두 열을 비교하여 같은지 다른지 확인 comparison = sepal_width_mean.equals(sepal_width_median) if comparison: print("두 데이터프레임의 'sepal width (cm)' 열의 값은 완전히 일치합니다.") else: print("두 데이터프레임의 'sepal width (cm)' 열의 값은 일치하지 않습니다.")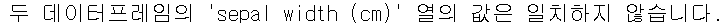
데이터 변형
-
'sepal length'와 'sepal width'의 비율을 계산하여 새로운 열 'Sepal Ratio'를 추가하기
# 'sepal ratio' 열 추가 df['sepal ratio'] = df['sepal length (cm)'] / df['sepal width (cm)'] df.head()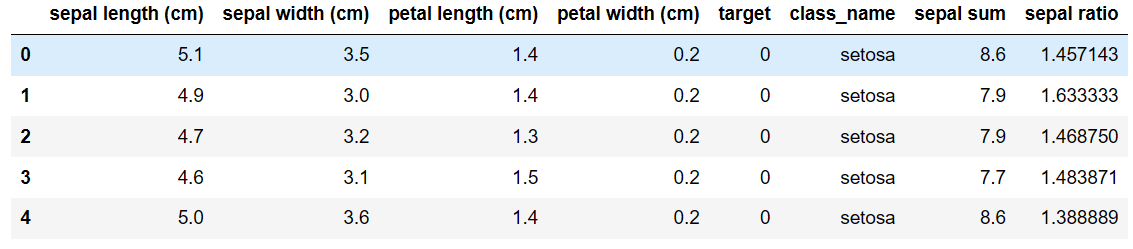
특정 조건에 따른 새로운 열 생성
-
'sepal length'가 5.0 이상인 경우 'Large', 미만인 경우 'Small'을 값으로 가지는 새로운 열 'sepal size'를 생성하기
# 'sepal size' 열 추가 df['sepal size'] = np.where(df['sepal length (cm)'] >= 5.0, 'Large', 'Small') df.head()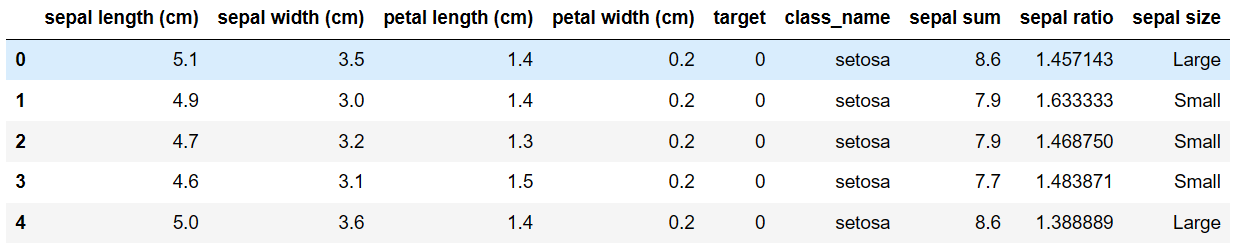
다양한 통계량 계산
-
각 품종(Species)별로 'sepal length'와 'sepal width'의 합계, 평균, 표준편차를 계산하기
# 품종별로 데이터 그룹화 grouped = df.groupby('class_name') # 각 그룹별로 'sepal length'와 'sepal width'의 합계, 평균, 표준편차 계산 summary_stats = grouped.agg({ 'sepal length (cm)': ['sum', 'mean', 'std'], 'sepal width (cm)': ['sum', 'mean', 'std'] }) # 결과 출력 summary_stats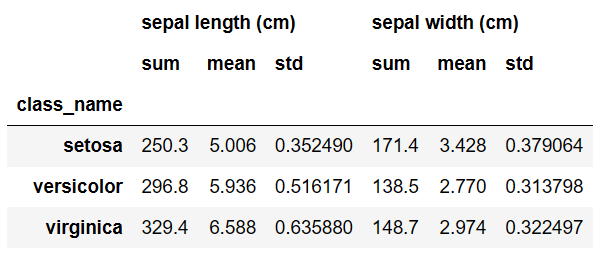
복잡한 조건 필터링
-
'sepal length'가 5.0 이상이고 'sepal width'가 3.5 이하인 데이터만 선택하고, 이 데이터의 'petal length'와 'petal width'의 합을 새로운 열 'petal sum'으로 추가하기
# 조건에 맞는 데이터 선택 selected_data_index = df[(df['sepal length (cm)'] >= 5.0) & (df['sepal width (cm)'] <= 3.5)].index # petal_sum df.loc[selected_data_index, 'petal sum'] = df.loc[selected_data_index, 'petal length (cm)'] + df.loc[selected_data_index, 'petal width (cm)'] df.loc[~df.index.isin(selected_data_index), 'petal sum'] = "해당없음" # 결과 출력 df.head(10)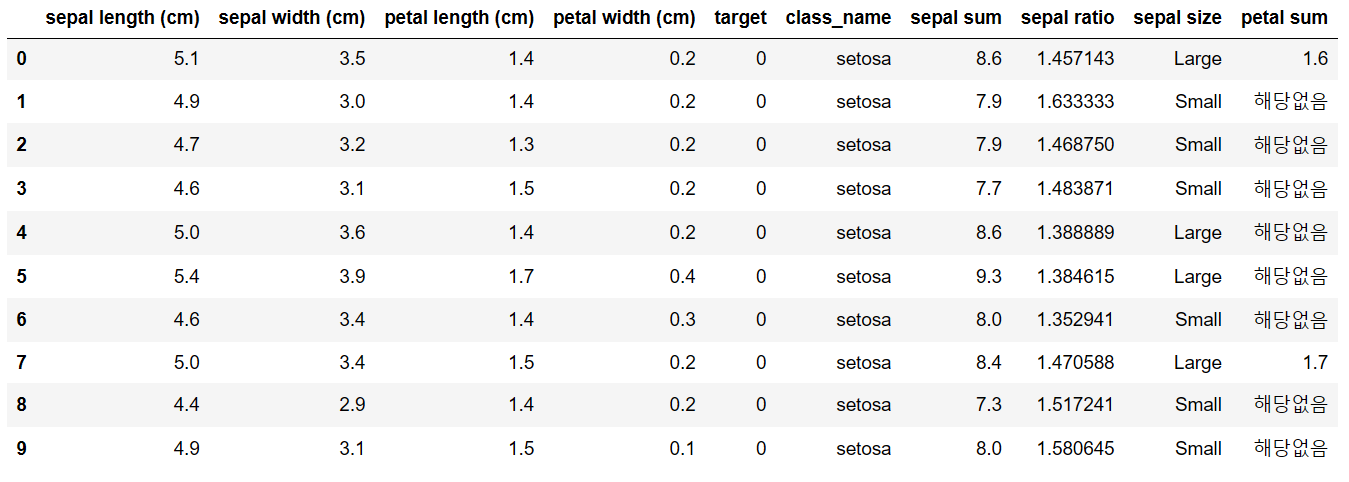
산점도 그리기
-
'sepal length'와 'sepal width'의 관계를 나타내는 산점도 그리기
# 산점도 그리기 sns.scatterplot(x = 'sepal length (cm)', y = 'sepal width (cm)', data = df, hue = 'target') plt.show()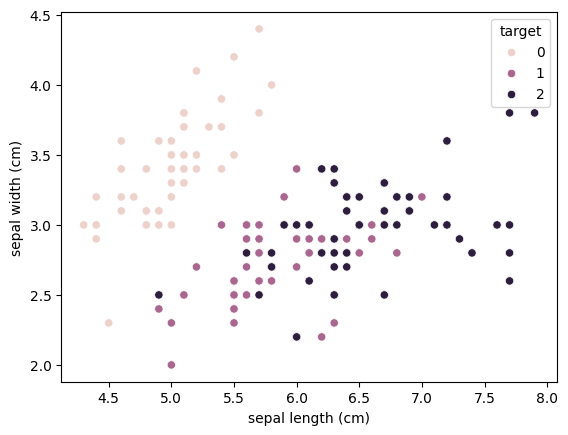
히스토그램 그리기
-
'sepal length'의 분포를 나타내는 히스토그램 그리기
# 품종이 sesota(target = 0)인 행들만 필터링 filtered_data = df[df['target'] == 0] # 히스토그램 그리기 sns.histplot(filtered_data['sepal length (cm)'], kde= True) plt.title('Sepal Length Distribution for sesota') plt.xlabel('Sepal Length (cm)') # 그래프 보여주기 plt.show()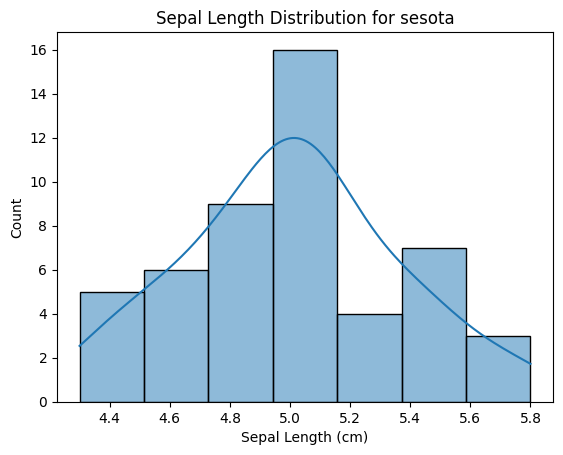
# 품종이 versicolor(target = 1)인 행들만 필터링 filtered_data = df[df['target'] == 1] # 히스토그램 그리기 sns.histplot(filtered_data['sepal length (cm)'], kde= True, color = 'orange') plt.title('Sepal Length Distribution for versicolor') plt.xlabel('Sepal Length (cm)') # 그래프 보여주기 plt.show()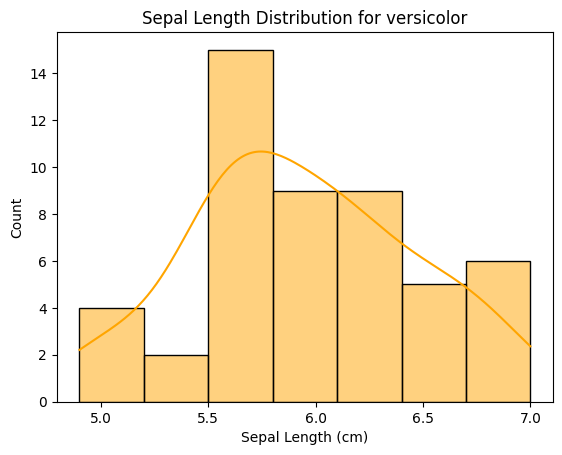
# 품종이 virginica(target = 2)인 행들만 필터링 filtered_data = df[df['target'] == 2] # 히스토그램 그리기 sns.histplot(filtered_data['sepal length (cm)'], kde= True, color = 'green') plt.title('Sepal Length Distribution for virginica') plt.xlabel('Sepal Length (cm)') # 그래프 보여주기 plt.show()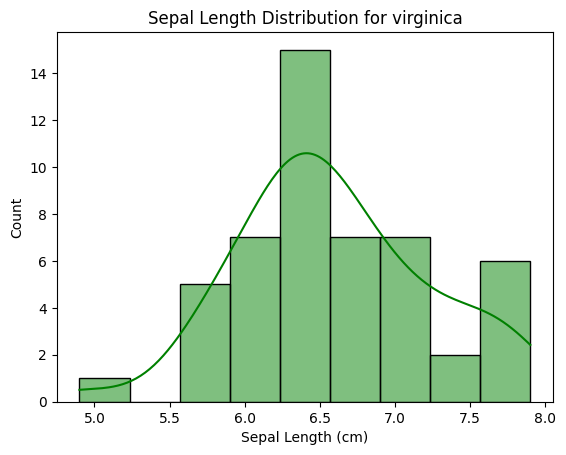
# 전부 합쳐서 그리기 hist = sns.FacetGrid(df, hue="target", height=5) hist.map(sns.histplot, "sepal length (cm)", kde=True) # 그래프 그리기 plt.title('Sepal Length Distribution by Target') plt.xlabel('Sepal Length (cm)') plt.legend(title='Target') plt.show()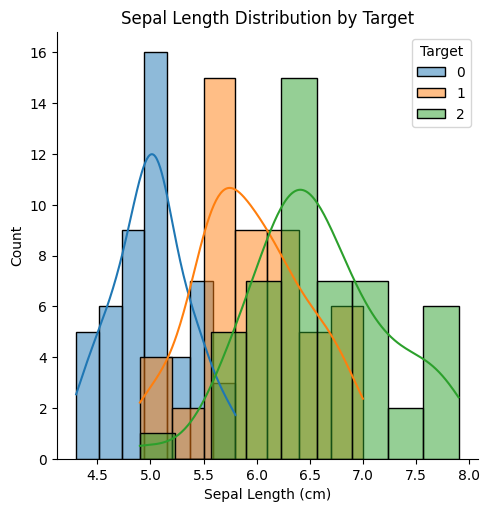
박스플롯 그리기
-
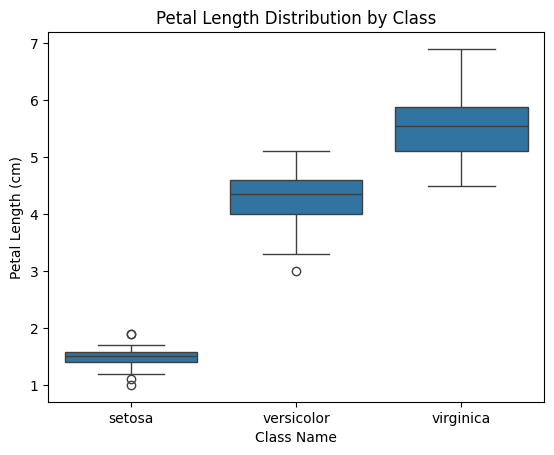
각 품종별로 'petal Length'의 분포를 나타내는 박스플롯 그리기
# 박스플롯 그리기 sns.boxplot(x='class_name', y='petal length (cm)', data=df) plt.title('Petal Length Distribution by Class') plt.xlabel('Class Name') plt.ylabel('Petal Length (cm)') plt.show()