Prometheus
프로메테우스는 시계열 데이터를 처리하는 것이 주 목적인 Time-Series DB이다.
프로메테우스는 주로 CPU, 메모리 사용량과 같은 Metrics 데이터에 대한 APM 구축을 목적으로 해서 MSA 형태의 컨테이너 서비스, 대규모 서버 클라스터 모니터링에 사용하는 것이 일반적이다.
프로메테우스의 장점은 쿠버네티스같은 프로젝트들은 대부분의 데이터 백엔드로 프로메테우스를 지원하고 있어서 큰 노력 없이 쉽게 모니터링 시스템을 구축할 수 있다.
-> 프로젝트의 백엔드로 프로메테우스를 사용.
쿠버네티스나 도커와 같은 컨테이너는 내보내는 Endpoint인 /metrics를 자체적으로 내장해 프로메테우스와 연동하면 소스 코드를 단 한줄 작성 없이 모니터링 시스템을 구축할 수 있다.
Prometheus 아키텍처
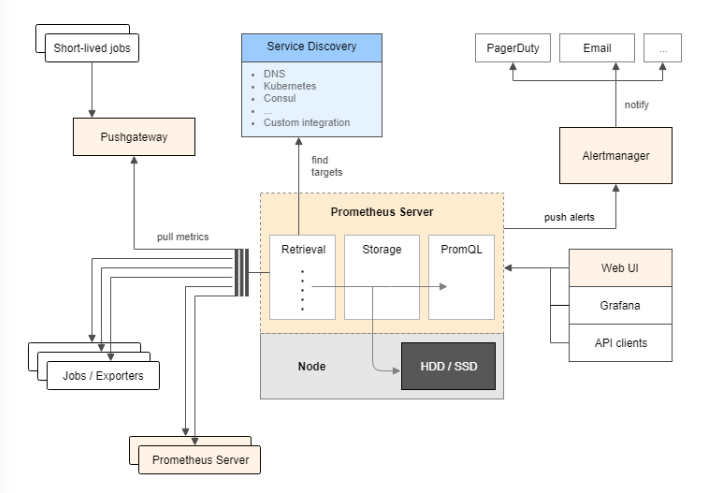
-
Pushgateway : Proxy Forwarding을 하여 접근할 수 없는 곳에 데이터가 존재하는 경우에 사용할 수 있는 대안이다.
-
Prometheus server : 프로메테우스의 메인 서버로 메트릭 데이터를 수집하고 저장한다. Prometheus server 내부에는 Retrieval, TSDB, HTTP server 모듈이 있다.
-
TSDB(Time-series Database) : 수집된 메트릭은 Prometheus server 내의 메모리와 (default) 로컬 디스크에 저장된다.
-
HTTP Server : 프로메테우스에 저장된 데이터를 조회하기 위해서 필요한 서버이다. 프로메테우스는 데이터를 가져가기 위한 프로토콜로 HTTP REST API를 제공하고, 직접 API를 통해 데이터를 가져가든지, Web UI 대시보드에서 데이터를 조회하는 방법으로 그라파나를 통해 데이터를 시각화할 수 있다.
-
Alertmanager : 프로메테우스에서 문제가 발생했다고 생각되는 시점에 slack, mail, hipchat 등을 통해 알람을 보내준다. 알람을 거는 기준은 Rule을 작성해서 load 시키는 방식으로 정할 수 있다.
Prometheus 장점
-
다차원 데이터 모델 가능 ( Metrics 이름과 key-value를 활용 )
-
다차원 데이터 모델을 활용할 수 있는 유연한 쿼리 언어 ( PromQL )
-
분산 스토리지에 대해서 어떠한 의존성도 없음.
-
모든 데이터는 HTTP( REST )Pull 기반으로 가져온다.
-
모니터링 타겟은 프로메테우스의 YAML 설정값을 통해 Discovery
-
Vertical - Horizontal Federation 가능 (상위-하위 구조를 통한 Aggregation 가능)
Prometheus 단점
-
클러스터링이 불가능하다.
-
모든 매트릭을 수집하지 않기 때문에 APM( Application Performance Monitoring )과 같이 모든 로그를 추적하기에는 적합하지 않다.
-
싱글 호스트 아키텍처이기 때문에 저장용량이 부족하면 디스크 용량을 늘리는 방법밖에 없다.
-
프로메테우스 서버가 다운되거나 설정 변경 등을 위해 재시작하면 매트릭이 일정 시간동안 유실된다.
