Stream
자바 8 에서 추가된 스트림은 람다를 활용할 수 있는 기술 중 하나이다.
자바 8 이전에서는 배열 또는 컬렉션 인스턴스를 다루는 방법은 for 또는 for ~ each 문을 돌면서 요소 하나씩을 꺼내서 다루는 방법을 사용했었다.
간단한 경우 상관없었지만, 로직이 복잡해질수록 코드의 양이 상당히 많아져 로직이 복잡해지고, 메소드를 나눌 때 루프를 여러 번 도는 경우가 빈번했다.
Stream 이란
스트림은 '데이터의 흐름'이다. 배열 또는 여러 개를 조합해서 원하는 결과를 필터링하고 가공된 결과를 얻을 수 있다.
-
장점 1 : 스트림은 람다를 활용할 수 있는 기술임에 람다를 사용하여 코드의 양을 줄이고 간결하게 표현할 수 있다.
-
장점 2 : 간단하게 병렬처리( Multi-Threading )가 가능하다. 결과적으로 둘 이상의 작업을 작게 나누어서 많은 요소를 빠르게 처리할 수 있다.
Stream 사용법
- 생성하기 : 스트림 인스턴스 생성.
- 가공하기 : 필터링( filtering ) 및 매핑( mapping ) 등 원하는 결과를 만들어가는 중간 작업( intermediate operations ).
- 결과 만들기 : 최종적으로 결과를 만들어내는 작업( terminal operations )
배열과 컬렉션 등 다양한 방향으로 스트림을 만들 수 있다.
배열 스트림 생성하기
public class Stream {
public static void main(String[] args) {
String[] arr = new String[]{"a","b","c"};
java.util.stream.Stream<String> stream = Arrays.stream(arr);
java.util.stream.Stream<String> streamOfArrayPart = Arrays.stream(arr, 1, 3);
}
}
Array.Stream() 메소드에 배열의 시작, 종료 인덱스( 1 & 3 )을 주어서 배열의 일부를 순회하는 스트림 객체를 만들 수 있다.
컬렉션 스트림
interface Collection<E> extends Iterable<E> {
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
}
public class Example022 {
public static void main(String[] args) {
List<String> list = Arrays.asList("A","B","C");
Stream<String> stream = list.stream();
Stream<String> parallelStream = list.parallelStream(); // 병렬처리 스트림
}
}컬렉션 타입( Collection, List, Set )의 경우 인터페이스에 추가된 디폴트 메소드인 stream을 이용해서 스트림을 만들 수 있다.
비어 있는 스트림
public Stream<String> streamOf(List<String> list) {
return list == null || list.isEmpty()
? Stream.empty()
: list.stream();
}비어있는 스트림은 요소가 없을 때, null 대신 사용할 수 있다.
스트림 주요 메서드 활용
Stream.builder()
빌더( builder )를 사용하면 스트림에 직접 원하는 값을 할당할 수 있다.
마지막에 build 메소드로 스트림을 리턴한다.
public class Example022 {
Stream<String> builderStream =
Stream.<String>builder()
.add("add1").add("add2").add("add3")
.build();
}Stream.generate()
generate 메서드를 이용하면 Supplier<'T'> 에 해당하는 람다로 값을 넣을 수 있다.
Supplier는 인자는 없고 리턴값만 있는 함수형 인터페이스로 람다에서 리턴하는 값이 들어간다.
public static<T> Stream<T> generate(Supplier<T> supplier) {
Stream<String> generatedStream = Stream.generate(() -> "generate").limit(5);
return (Stream<T>) generatedStream;
}Stream.iterate()
iterate 메서드를 이용하면 초기값과 해당 값을 다루는 람다를 이용해서 스트림에 들어갈 요소를 만들 수 있다.
이 메서드도 스트림의 사이즈가 무한하기 떄문에 특정 사이즈로 제한해야 한다.
public class Example022 {
Stream<Integer> integerStream = Stream.iterate(30, n-> n+2).limit(5); // 30, 32, 34, 36, 38
}
IntStream
스트링을 이용해서 스트림을 생성할 수 있다. 예제를 보면 char는 문자이지만 본질적으로는 숫자인 이유로 가능하다.
public class Example022 {
IntStream stringStream = "Stream".chars(); // 83, 116, 114, 101, 97, 109
}
정규표현식( RegEx )을 이용해 문자열 자르기
정규표현식을 이용해서 문자열 자르기
public class Example022 {
Stream<String> stringStream = Pattern.compile(", ").splitAsStream("ABC, DEF, GHI"); // ABC DEF GHI
}
파일 스트림
public class Example022 {
Stream<String> lineStream;
{
try {
lineStream = Files.lines(Paths.get("file.txt"),
Charset.forName("UTF-8"));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}Files 클래스의 lines 메소드는 해당 파일의 각 라인을 스트링 타입의 스트림으로 만들어준다.
스트림 연결하기
public class Example022 {
Stream<String> stream1 = Stream.of("a","b","c");
Stream<String> stream2 = Stream.of("A","B","C");
Stream<String> concat = Stream.concat(stream1, stream2)
}
Stream.concat 메서드를 사용해서 두 개의 스트림을 연결해 새로운 스트림을 만들어낼 수 있다.
병렬 스트림
public class Example022 {
public static void main(String[] args) {
List<String> list = Arrays.asList("a","b","c");
Stream<String> parallelStream = list.parallelStream();
parallelStream.forEach(Example022 -> System.out.println(Example022));
}
}stream 을 생성할 때, stream 대신 parallelStream 메서드를 사용해서 병렬 스트림을 생성할 수 있다.
병렬처리 주의사항
-
박싱은 성능을 크게 저하시킬 수 있는 요소로 이를 방지하기 위해 기본형 특화 스트림( IntStream, LongStream, DoubleStream )을 잘 활용하자.
-
limit이나 findFirtst처럼 요소의 순서에 의존하는 연산의 경우 비싼 비용을 요구한다.
-
순서 연산에 유의하자. 순서가 상관없는 findAny 같은 경우 병렬 처리가 빠르다.
-
소량의 데이터에서는 병렬 처리가 도움이 되지 않는다.
-
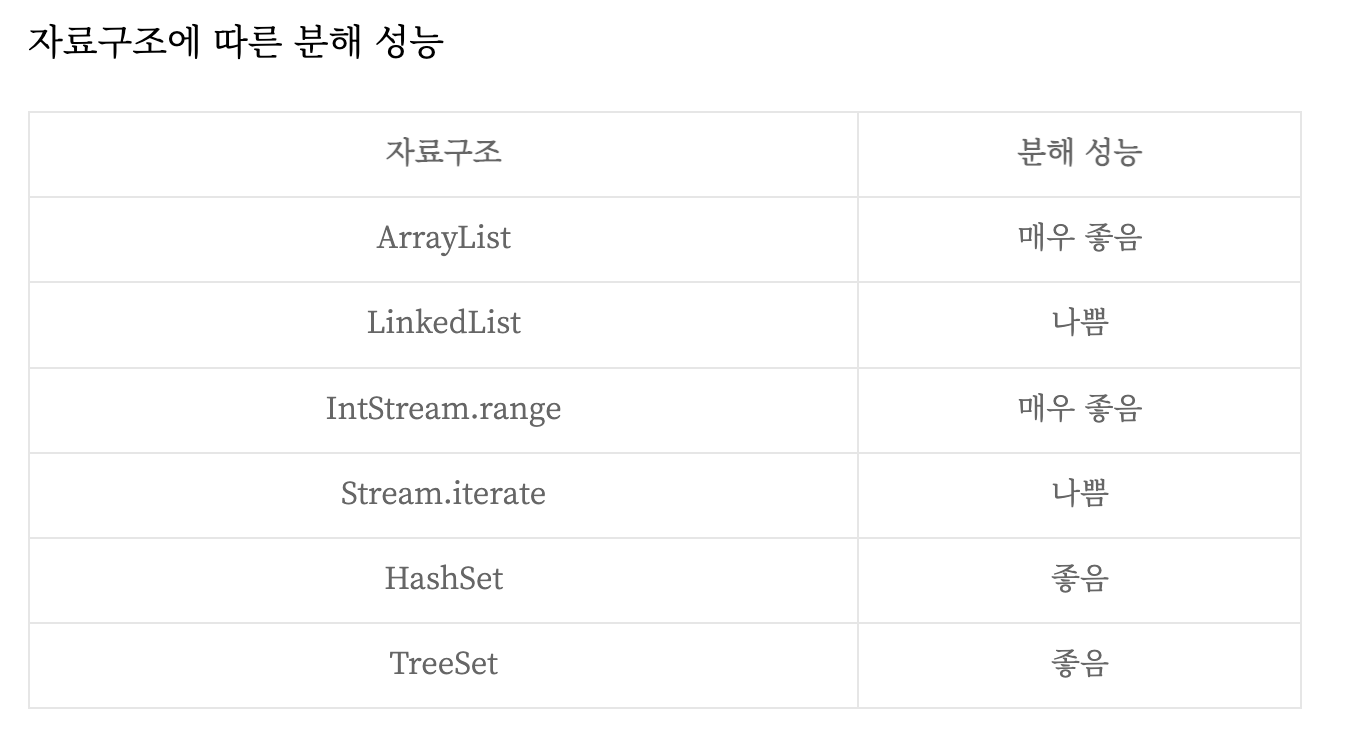
자료구조가 적절한지 확인하자.
-
LinkedList는 분할 하기 위해서 모든 요소를 탐색해야 하지만, ArrayList는 탐색하지 않아도 분해할 수 있다. 커스텀 Spliterator를 구현해 분해를 제어할 수 있다.
parallelStream 예제
public long parallelSum(long n) {
return Stream.iterate(1L, i -> i+1)
.limit(n)
.parallel()
.reduce(0L, Long::sum);
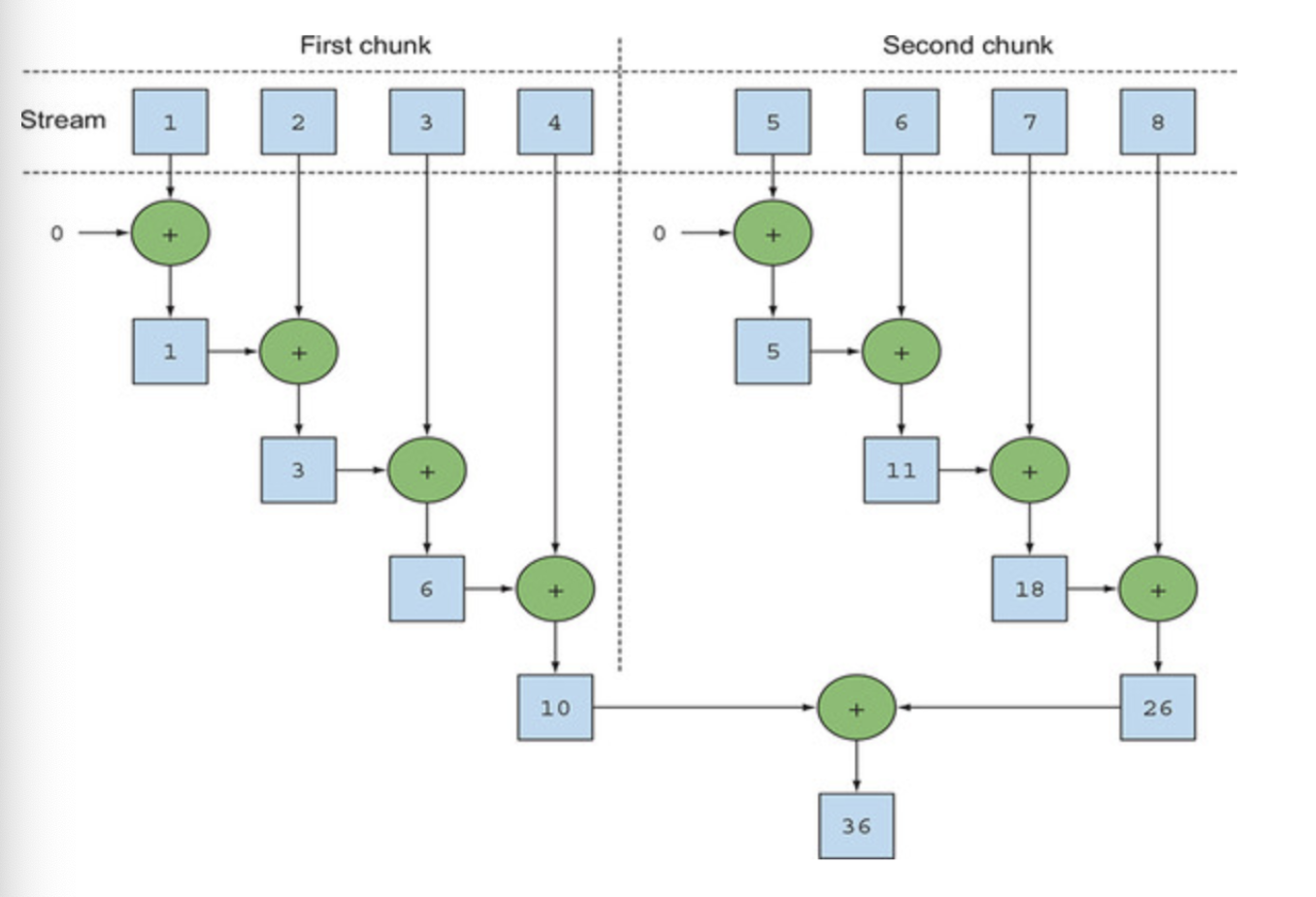
}위에서 봤던 것처럼 parallel 을 추가함으로써 병렬처리가 끝난다.
병렬화를 이용하기 위해서는 스트림을 재귀적으로 분할해야하고, 각 보조 스트림을 서로 다른 스레드의 연산으로 할당한 뒤 결과를 하나의 값으로 만들어야한다.
또한, 내부적으로 공유된 가변 상태를 가지지 않아야하는 이유로 람다 스트림을 사용하는 것이다. 람다 스트림을 사용하면 불변이 보장되기 때문이다.
Stream VS for - Loop
스트림은 함수형 프로그래밍 언어에서 이야기하는 sequence와 동일한 용어이다.
학교를 가기위한 순서를 정해서 이야기해보자.
1. 학교를 가기위해 정해진 곳으로 간다.
2. 정해진 곳에서 버스를 탄다.
3. 버스를 타고 학교에서 내린다.
만약 학교를 가기위해 정해진 장소로 가지도 않았는데( 1번 ) 학교에서 내린다거나( 3번 ) 정해진 곳에서 버스를 타는 것( 2번 )은 말도 안되는 소리이다.
이처럼 정해진 일을 순서대로 처리하는 것은 중요한 일이다.
우리는 이 정해진 순서대로 일을 처리하라고 함수를 파라미터로 넘기는 행위를 Sequential Programming( 객체지향 프로그래밍 : Internal Iterator Pattern )이라고 한다.
GOF 디자인 패턴 책에서는 컬렉션 내부에서 요소들을 반복시키고 개발자는 요소 당 처리해야할 코드만 제공하는 코드 패턴이라고 한다.
다시 말해서 GOF 패턴은 처리해야 할 함수를 제공하면 Collection을 순회하는 것을 외부에서 하는 것이 아니라 스트림을 내부에서 만들어 순회하는 것이다.
반환

-
스트림은 .build를 통해 stream을 반환하는데, 스트림을 반환한다는 것은 연산의 파이프라인( pipeline )을 반환한다는 의미이다.
-
스트림은 매번 중간 연산마다 조건을 실행하지 않는다. 대신, 중간 연산마다 연산의 파이프라인을 리턴한다.
-
Stream은 자료구조를 어떻게 다루는지를 논한다.
for-loop vs sequence stream
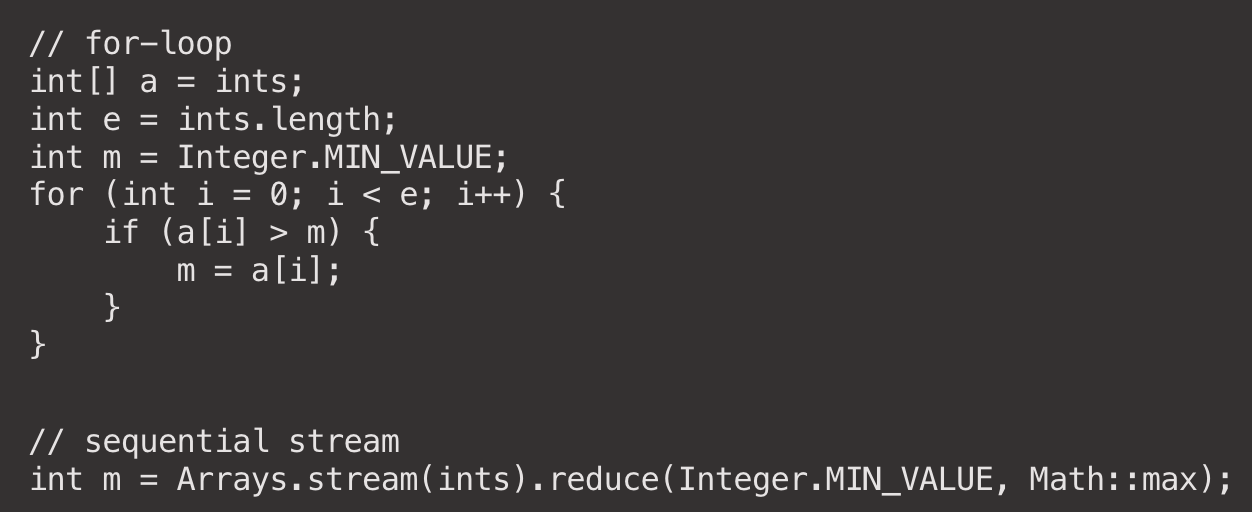

위 코드를 실행시켜 결과를 확인해보면 for - loop가 약 15배정도 훨씬 빠르다.
스트림이 느린 이유는 JIT Compiler가 for - loop를 40년 이상 다뤄와서 내부 최적화가 이미 너무 잘 되어 있다고 한다.
sequence stream 을 원시타입이 아니라 래퍼 타입으로 한다면?
ArrayList에 500000개의 Integer 타입을 저장하고 비교

원시 타입에서 래퍼 타입으로 변경했을 때는 차이가 눈에 띄게 줄었다. 원래는 약 15배였지만, 래퍼 타입으로 변경 시에는 1.27배 밖에 차이가 나지 않았다.
물론 그 이유 중에서는 박싱 언박싱의 이야기가 나올 것이지만, ArrayList를 순회하는 비용 자체가 크다는 것도 그 이유가 될 것이다.
- wrapper type : heap 메모리 영역에 저장
- primitive type : stack 영역에 저장
아주 비싼 계산 비용이 소모되는 아파치 라이브러리의 slowSin() 활용
위에서 해봤던 것에 비교해 더욱 헤비한 slowSin()을 가지고 비교를 해보면 확실히 차이가 난다고 한다.
아래의 그림은 int 타입에 대한 array에 10000개의 원소를 순회하면서 계산하는 코드이다.

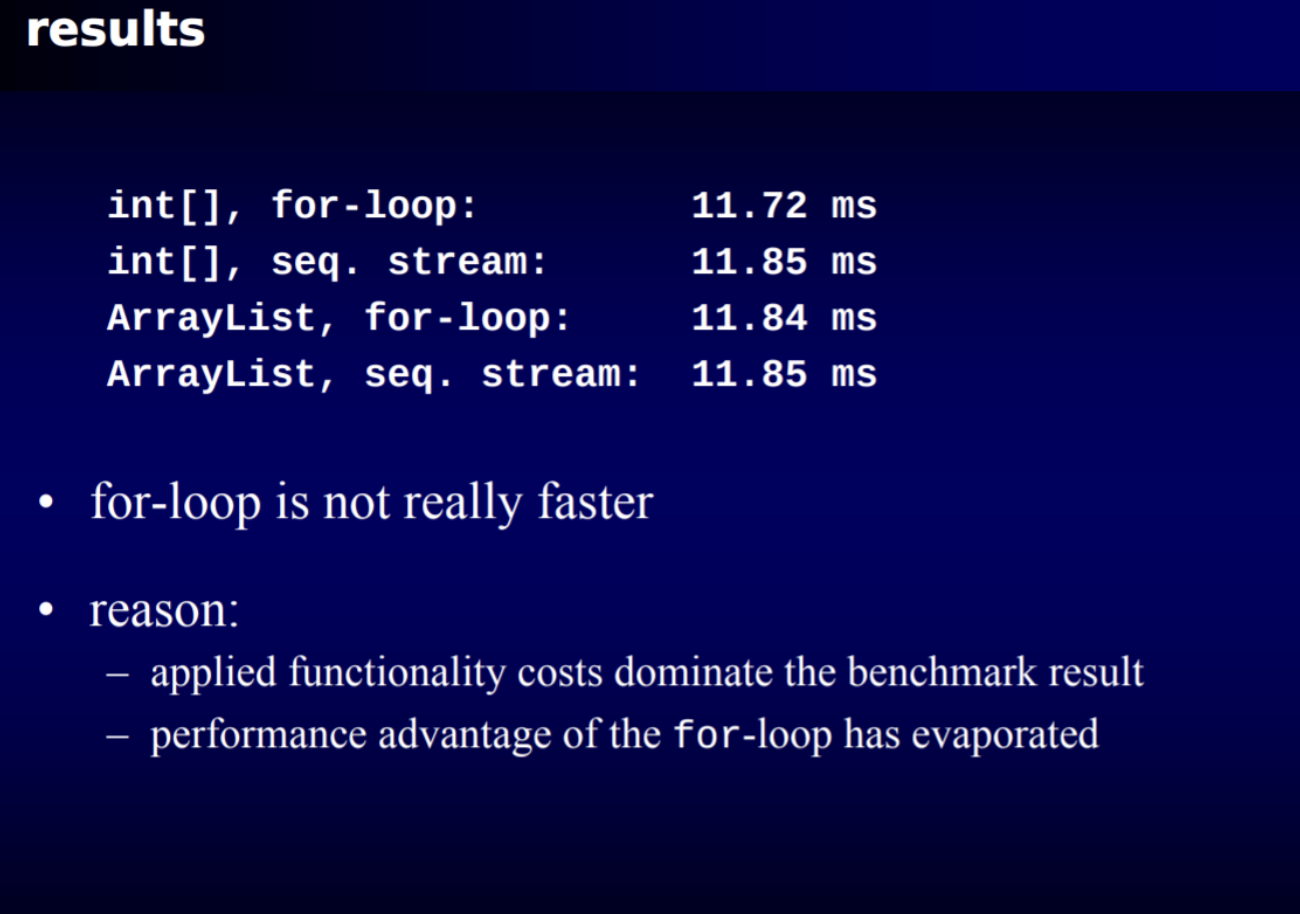
위 두 그림을 비교하면 더 이상 for-loop가 빠르지 않은 것을 확인할 수 있다.
결과적으로 우리는 함수 내부의 시간 복잡도가 크다면 stream을 사용하는 것이 for-loop에 대비하여 속도 손실이 없어진다.
추가할 내용
- 파일 스트림
- Filtering, Mapping, Sorting, Iterating 등..
- 순차 스트림 vs 병렬 스트림
- Stateless Functionality vs Stateful Functionality
참고
