저자: Haoyu Han et al. (Michigan State Univ. 외)
분야: Retrieval-Augmented Generation (RAG), Graph Learning, LLM
링크: https://arxiv.org/abs/2501.00309
서론
연구 배경
기존 RAG의 한계(개별 문서 중심 검색)를 극복하기 위해 그래프 구조의 관계형 정보 통합
문제 정의
도메인별 그래프 데이터의 이질성(형식/관계 다양성)으로 인한 GraphRAG 설계 표준화의 어려움
연구 목적
그래프 데이터의 구조적 특성을 반영하여 다양한 분야(사회 네트워크, 지식 그래프 등)에 적용 가능한 GraphRAG 프레임워크 제안
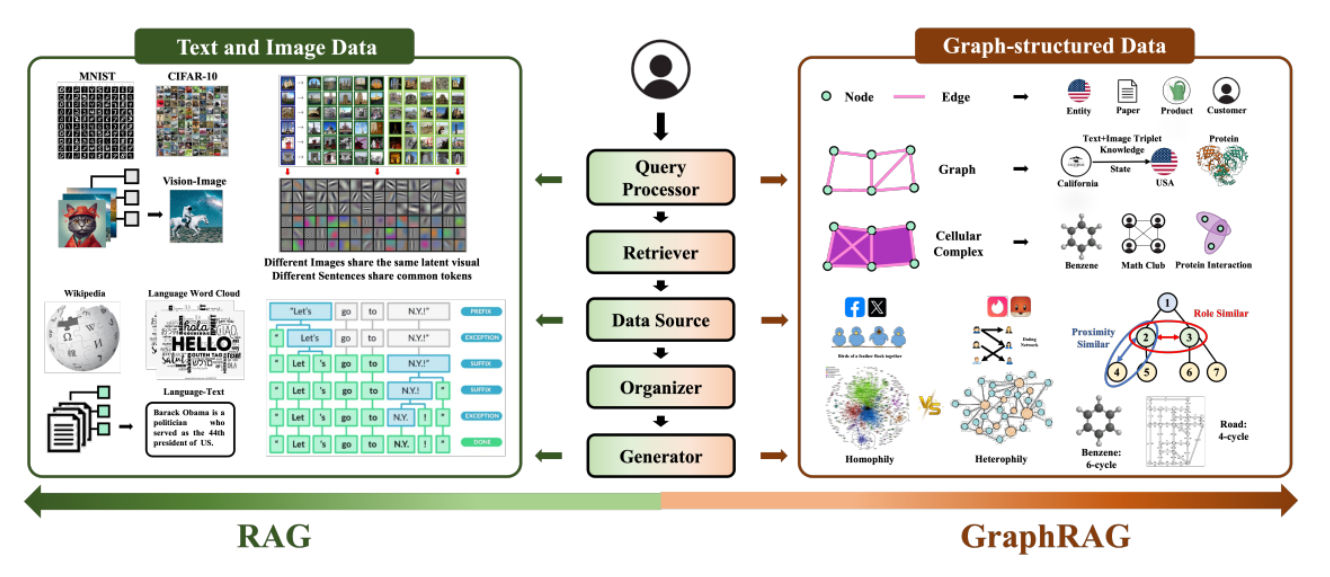
본론
1. GraphRAG 프레임워크
(1) 쿼리 전처리(Query Processor): 그래프 패턴 인식
(2) 검색기(Retriever): 신경망-기호 결합 검색 전략
- 1단계: 그래프에서 정보 탐색(기호 탐색, 규칙 기반)
- 2단계: GNN을 이용한 임베딩 매칭(신경망)
(3) 조직기(Organizer): 탐색된 정보를 구조적으로 정제
- 다단계 검색 과정에서 그래프 의존성(인과/시간 관계) 명시적 모델링
- e.g.) Luo et al.(2023)의 k-hop 이웃 탐색 기법
(4) 생성기(Generator): 생성기
(5) 데이터 소스: 입력 그래프
2. 비정형 그래프 정의 및 처리 방법
이 논문에서 그래프 데이터는 텍스트/이미지와 달리 다음과 같은 3가지 큰 차이점을 지닌다.
-
다양한 형식(Diverse-Formatted): Knowledge Graph, 문서 그래프, 멀티모달 그래프 등
-
상호의존성(Interdependent): 노드 간 관계를 통해 다중 reasoning 가능
-
도메인 특화성(Domain-Specificity): 분야마다 관계 유형과 구조가 다름 (ex. 논문 인용 vs. 항공망 중심성)
3. Retriever 설계 구조
GraphRAG의 핵심은 Retriever의 설계라고 할 수 있다.
🗝️기본 수식🗝️
🍯쿼리 전처리 단계를 거친 과 그래프(G)를
Retriever에 입력하면 (Organizer 단계의 필요 요소)가 나온다.
🗝️임베딩 기반 검색 수식🗝️
🍯코사인 유사도나 내적을 이용해서 쿼리와 데이터를
임베딩 한 함수를 top-k 유사 정보로 탐색한다.
-
F_q, F_S: 쿼리 및 데이터의 임베딩 함수 -
ϕ: 유사도 함수 (Cosine, Dot Product 등) -
S*: top-k 유사 정보
🗝️그래프 신경망을 활용한 Deep Embedding 수식🗝️
🍯노드, 엣지, 서브그래프의 표현을 임베딩하여 검색에 활용한다.
▲ GNN 기반의 그래프 컨볼루션 정의
-
γ, ϕ: 이웃 노드와 엣지를 조합하는 함수 -
⊕: concat 또는 add 연산 -
x_i^l: l-layer에서의 노드 임베딩
4. GraphRAG의 성능 검증 기준
GraphRAG의 효율성을 입증하기 위한 검증 기준은 다음과 같다.
(1)검색 성능 향상과 (2)생성 정확도 개선이다.
아래는 (1)과 (2)를 위해 논문에서 활용한 기술적 방법론이다.
-
Graph Traversal 기반 구조: query에 따라 BFS, DFS, A*로 확장 경로 검색
-
Semantic/Structure 기반 Pruning: 불필요한 정보 제거 → 성능 향상
-
GNN + Reranking: LLM이 잘 다루도록 재정렬 (노이즈 제거 및 관심 정보 우선 정렬)
예를 들어, 논문에서 각기 다른 케이스로 연구한 QA-GNN, GNN-RAG 등은 retrieval quality 향상을 위해 query-aware attention 또는 shortest-path 기반 context 추출 기법을 사용하는 것이다.
5. 실험 방법론
(1) 실험 범주
GraphRAG은 도메인 별로 다음 세 가지 기준으로 성능을 평가한다.
-
Component-Level Evaluation: 각 모듈(그래프 구축, 검색기, 조직자, 생성기)의 독립 성능
-
End-to-End Benchmark: 전체 시스템을 통합했을 때 성능
-
Task & Domain-Specific Evaluation: 다양한 도메인에 대한 적용 가능성과 성능
(2) 대표 도메인
✅ 과학 분야 (분자 생성 / 예측)
-
Task: Molecular Property Prediction, Scientific Molecule Generation
-
평가 포인트: 기능성 그룹 (functional groups)을 그래프로 인코딩 → 특정 molecular property 예측
-
GraphRAG 효과: subgraph 기반 reasoning으로 예측 정확도 향상
-
비교 기준: 기존 텍스트 기반 RAG vs 구조 기반 GraphRAG
-
결과: GraphRAG이 더 적은 hallucination을 발생시킴, 기능성 서브그래프 기반 설명 제공 → 설명력 증가
✅ 바이오의료 QA
-
Task: Biomedical QA with hypothesis graph (HYKGE, Ram-EHR 등 활용)
-
도전 과제: 개별 knowledge snippet 간 관계 고려가 중요
-
성능 향상 요인: Graph-guided subgraph traversal이 유의미한 evidence chain 구성에 효과적
✅ 멀티홉 질의응답 (Multi-hop QA)
-
Task: Reasoning path 필요
-
효과: reasoning chain을 그래프로 구성하여 intermediate step을 논리적으로 정리 가능
-
결과: 정확도 향상, 사용자가 reasoning path를 시각적으로 확인 가능 → 설명력 + 신뢰도 증가
✅ 테이블 기반 QA / 문서 요약
- Task: Table QA, Document QA
- 도전 과제: 단순 passage retrieval로는 테이블 간 관계를 포착하기 어려움
- 결과: 테이블 셀 간의 관계를 노드/엣지로 모델링 → 복잡한 질의에도 견고, RecBole, TabPrompt 등의 benchmark로 검증됨
6. 실험 결과
결론
해당 논문은 비정형 그래프 데이터를 RAG에 통합하기 위한 구조적 정의 및 수식적 구현을 다룬다.
특히 그래프의 다양한 특성 (형식, 상호의존성, 도메인 특화성)을 정의하고 이를 기반으로 GNN 기반 임베딩 및 탐색 전략을 통해 그래프 지식을 정량적으로 처리하는 방법론을 제안한다.
이론적 수식(임베딩 기반 검색, GNN 계산)을 기반으로 다양한 도메인에 적용할 수 있는 범용성과 실용성을 확보하는 데 의의가 있는 논문이다.
질문
Q1. 비정형 그래프 구조가 효과적으로 처리되려면?
단순히 그래프를 텍스트로 수직/수평화 하는 것은 기하 구조와 계층성 표현에 한계가 있다.
멀쩡히 있던 공간 정보를 굳이 텍스트로 바꾸면 이해가 어려워진다는 뜻이다.
논문에서는 이를 보완하기 위해 Graph Encoder를 사용하여 구조 정보를 유지한다.
Molecule Graph, Scene Graph, Document Tree 등은 각각 다른 인코딩 전략이 필요하다. 다양한 그래프 구조를 처리하는 도구를 만들어 버린 것이다.
실습
