
본 포스팅은 뉴립스에 2024년 제출된 논문을 살펴보고, 기반한 논리와 배경 지식을 정리하는 글입니다.
Integrating Suboptimal Human Knowledge with Hierarchical Reinforcement Learning for Large-Scale Multiagent Systems. Dingbang Liu et al. 2024. https://nips.cc/virtual/2024/poster/95455
Information
본 연구의 주제는 최적이 아닌 인간의 지식을 퍼지 논리(Fuzzy Logic)를 이용해 수치화하고, 새로운 다중 에이전트 강화학습(MARL) 프레임워크인 hhk-MARL을 제안하는 것이다.
그래프 기반의 그룹 제어기를 활용하여 동적으로 에이전트를 연결하고 제어하였으며, 기존의 IQL, QMIx, Qatten의 세 가지 알고리즘을 결합하여 성능이 뛰어난 방법임을 증명하였다.
이 연구의 Core Contribution은 완벽하지 않은 인간의 지식이라도 적절히 활용하면 학습 속도와 성능을 모두 향상시킬 수 있다는 점에 있다.
Introduction
연구의 배경은 다음과 같다.
먼저, 다중 에이전트 시스템에서는 샘플 비효율성과 차원의 저주로 인해 처음부터 에이전트를 학습시키는 것이 어렵다. 인간이 중간에 개입하여 직관적이고 일반적인 정보를 제공하며 시범을 보이는 방법인 Human On The Loop 방식은 단계별로 시범을 제공해야 하는 부담으로 이어지기 때문에, 인간이 지속적으로 시도하기에는 어렵다.
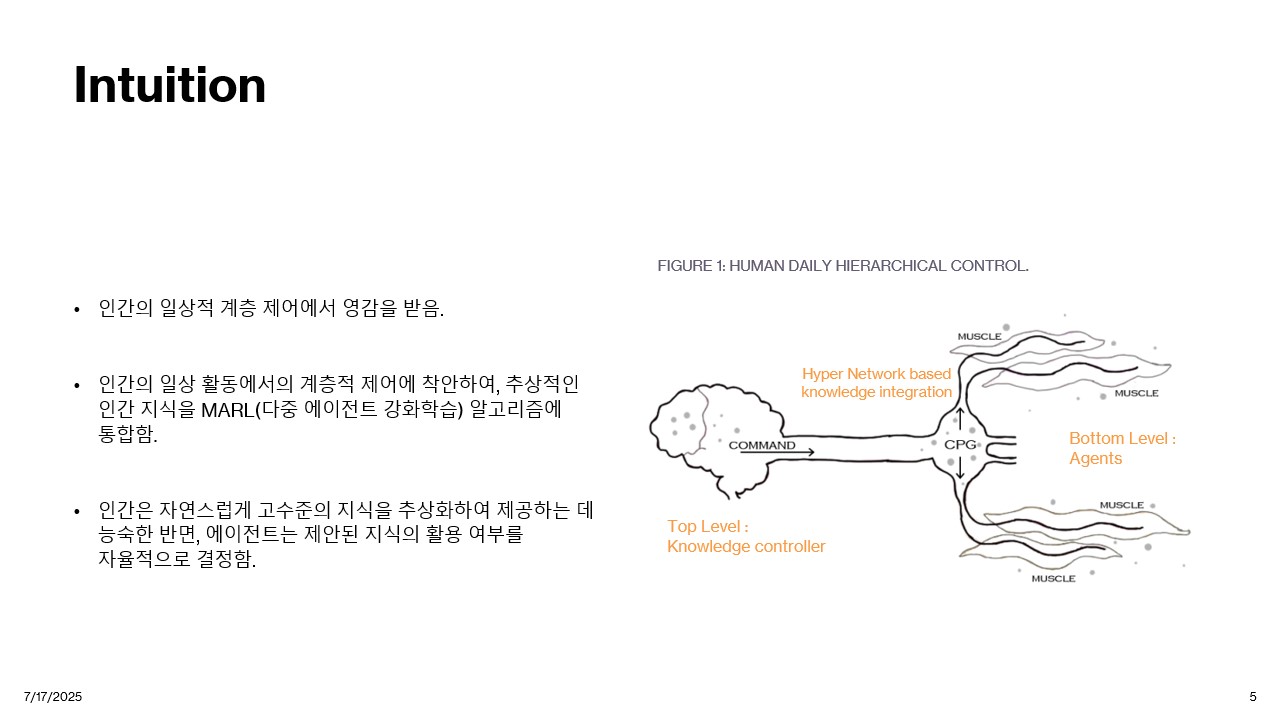
따라서, 본 연구는 인간의 일상적 계층 제어에서 영감을 받아 추상적인 인간의 지식을 MARL 알고리즘에 통합한 방법론을 제안한다.
인간은 자연스럽게 고수준의 지식을 추상화하여 제공하는 데 능숙한 반면, 에이전트는 제안된 지식의 활용 여부를 자율적으로 결정하는 데 있어서 어려움을 겪고 있었다. 이를 퍼지 논리와 계층적 강화학습 그리고 그래프 기반 지식 통합을 통해 해결하고자 한 것이다.
Terminology
계층적 강화학습(HRL)
계층적 강화학습(Hierarchical Reinforcement Learning)이란, 복잡한 문제를 여러 단계(계층)으로 나누어, 각 계층이 서로 다른 수준의 제어 또는 의사결정을 담당하는 방식이다.
상위 계층은 추상적 목표("물체를 집어 올려라")를 설정하고, 하위 계층은 구체적이고 세부적인 제어 명령("팔을 30도 회전", "그리퍼를 닫아라")를 수행한다.
본 논문에서는 상위 계층을 인간의 추상적인(완전하지 않은) 지식으로 두었고, 하위 계층을 에이전트의 로컬 관측에 기반한 행동 값으로 설정하였다. 또한 둘을 적절히 통합하는 통합 계층(Knowledge Integration)을 기반으로 최종 행동과 보상을 업데이트 할 수 있는 계층을 두었다.
What is Fuzzy Logic?
퍼지 논리는 명확하게 정의될 수 없는 지식(이진화를 할 수 없는 지식)을 표현하는 방법이다.
퍼지 집합의 개념은 각 대상이 어떤 모임에 속한다 또는 속하지 않는다는 이진법 논리로부터 벗어나, 각 대상이 그 모임에 속하는 정도를 멤버십 함수(Membership function)로 나타내고 그 멤버십 함수를 대응되는 대상과 함께 표기하는 집합이다.
퍼지 측도(fuzzy measure)는 일반집합 A에서 위치가 애매한 원소 a가 A의 부분집합 P에 속한다는 말의 애매한 정도를 나타냄으로써 a와 A의 관계를 a가 A에 수학적으로 연속적인 소속성을 갖도록 표현한다.
최적이 아닌 지식(Suboptimal Knowledge)
최적이 아닌 지식이란 문제를 해결하는 데 있어서 가장 좋은 방법은 아니지만, 여전히 어느 정도는 쓸모가 있는 지식을 의미한다. 사람이 문제를 해결할 때 실수하거나 완벽하지 않은 방법을 사용해도, 그 경험이나 지식이 AI에게는 도움이 될 수 있다. AI는 이러한 최적이 아닌 인간 지식도 참고하여 더 나은(최적에 가까운) 정책을 스스로 학습할 수 있게 된다.
Preliminaries

1. 부분 관측 마르코프 게임(Dec-POMDP)
해당 논문에서는 게임 모델을 Dec-POMDP로 설정하였다.
Dec-POMDP 는 분산화된 부분 관측 마르코프 결정 과정의 명칭이다. MDP, POMDP와는 달리 다중 에이전트로 구성되어 있으며, 다중 에이전트의 부분 관측에 기반하여 공동 보상을 공유한다.
이 모델의 목적은 부분 관측과 공동 보상을 통해 모든 에이전트가 가장 좋은 행동을 학습하는 것이다.
각 에이전트 는 자신의 관측 에 따라 확률적으로 행동 를 선택한다.
전체 에이전트의 행동에 따라 환경이 다음 상태로 전이되고, 모든 에이전트가 동일한 보상을 공유하게 된다.
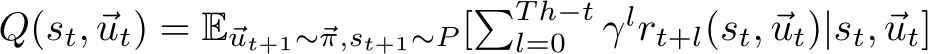
2. 퍼지 논리(Fuzzy Logic) 수식
인간의 지식은 추상적이고 불확실하므로, 퍼지논리로 표현한다.
퍼지논리는 일반적으로 아래와 같은 형식이다.
“IF X is A and Y is B THEN Z is C”
각 퍼지 집합은 멤버십 함수 μ로 정의된다.
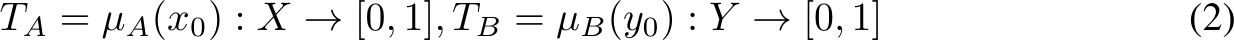
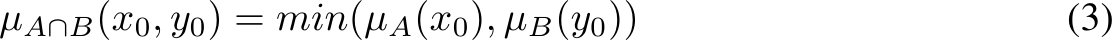
여기서 min을 쓰는 이유는, max를 쓰게 되면 규칙이 너무 후해지기 때문이다.
예를 들어서, "차간 거리가 넓고, 일정 시간 동안 직진하는 구간일 때 속도를 높여라."라는 퍼지 논리가 있다고 해보자.
"차간 거리가 넓다" = 0.3 , "일정 시간동안 직진하는 구간이다" = 0.9 일 때,
min을 쓰게 되면 0.3 만큼 적용이 되어 두가지 조건을 모두 만족하는 정도만큼을 에이전트에 입력할 수 있게 된다고 이해하면 된다.
위의 두 전제 조건이 모두 만족될 때 규칙의 강도(만족도) ω는 다음과 같이 계산한다.
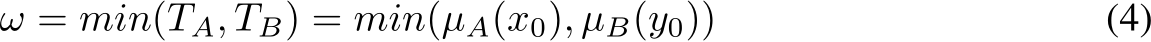
결국, 퍼지 규칙은 관측값을 입력받아 해당 행동을 취할 “가능성”을 출력한다.
Membership Function의 이해
스터디원들이 질문을 많이 했던 개념이 멤버십 함수였는데,
직관적으로 소속의 정도가 어떻게 할당되는지가 와닿지 않기 때문이었다.
아래는 삼성 SDI에서 설명한 퍼지 이론에 대한 내용을 일부 발췌한 글이다.
"어떤 나이가 제시되었을 때, 그 나이를 젊다고 판단할 수 있는 가능성을 나타낸다. 17살의 고등학생이 과연 젊은 집합에 포함될 수 있느냐는 질문에 부정적인 답변을 할 수 있는 사람은 아마 거의 없을 것이다. 따라서 17세의 소속 함수는 1이 된다. 하지만 29살은 어떨까? 젊다고 생각하는 사람이 백 명 중에 70명 정도이고, 나머지 30명은 결코 젊다는 판단을 내릴 수 없다고 한다면 소속 함수는 0.7이라고 할 수 있다. 같은 맥락으로, 82세 어르신에 대한 소속 함수는 0이 된다. 즉, 일반적인 컴퓨터가 판단하는 과정이 0과 1이라는 두 개의 숫자만으로 이루어져 있다면, 퍼지 이론은 가능성에 대한 수치를 0부터 1까지의 실수로 표현한다. 빛과 그림자, 단 두 가지의 선택지만 있던 논리의 어둠 속에서, 이제 우리는 무한한 무지갯빛 스펙트럼을 만날 수 있다."
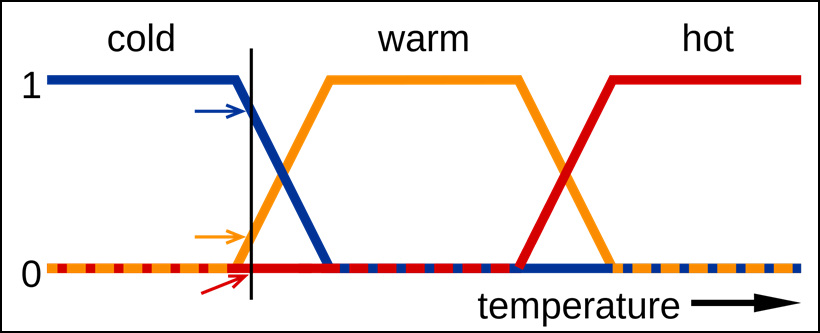
출처 : 삼성 SDI , 퍼지논리 https://news.samsungdisplay.com/24757
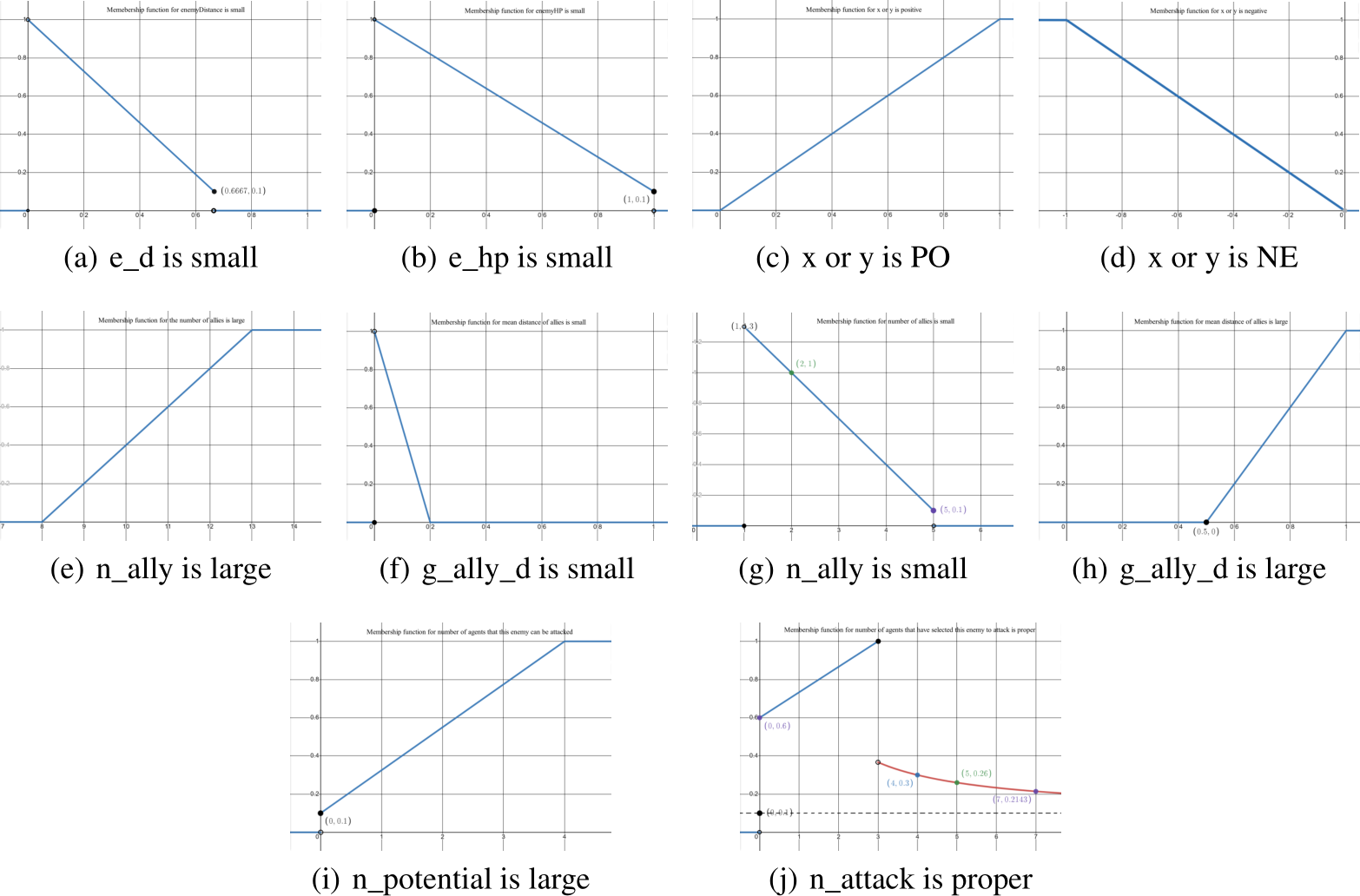
본 논문에서는 SMAC에서 사용한 10개의 멤버십 함수를 부록에 첨부해두었다.
재밌는 점은 선형함수가 아니라는 점이다.
Figure 8: Membership functions used in SMAC.
지식 표현 및 통합
인간의 퍼지 규칙 기반 지식은 완벽하지 않기에 에이전트가 지식을 맹목적으로 따르지 않고, 스스로 판단해서 언제 활용할지 결정해야 한다. 최종 결정은 에이전트가 내리는 것이라고 생각하면 된다.
“IF O is high, THEN action is read” 라는 퍼지 논리가 있을 때, 이 논문에서의 멤버십 함수 는 출력값의 제한을 두기 위해 클리핑 함수의 형태로 활용된다. 0.05o 는 입력값, 0은 출력 최소값, 1은 출력 최대값이다.
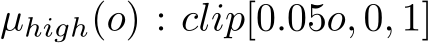
지식 통합 층을 기반으로 에이전트는 mentor(인간)의 조언을 참고하되, 상황에 따라 스스로 판단하게 된다.
Methodology
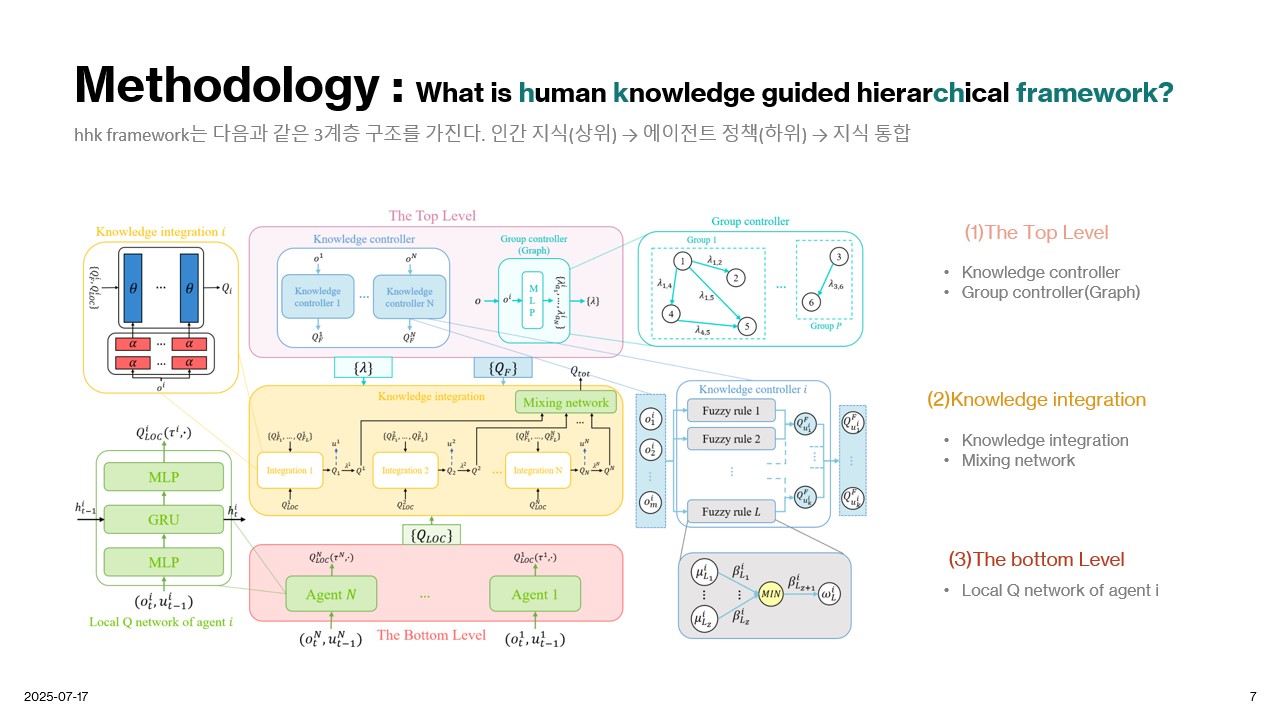
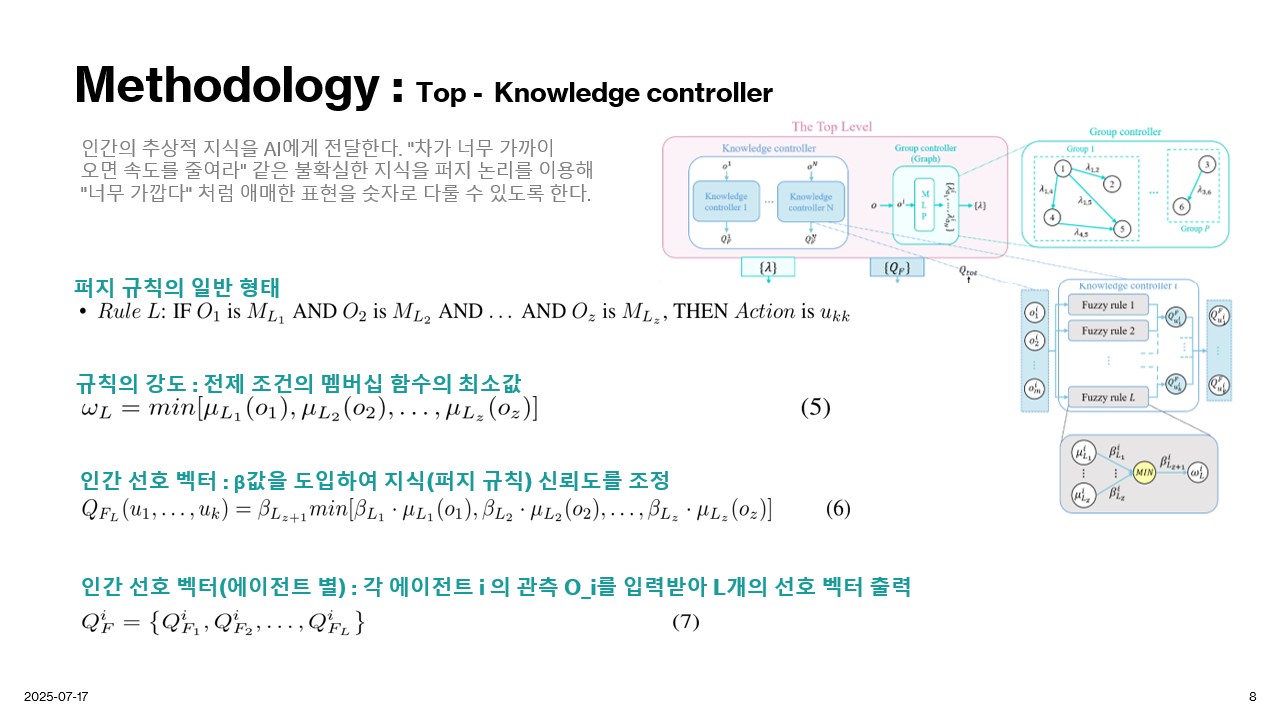

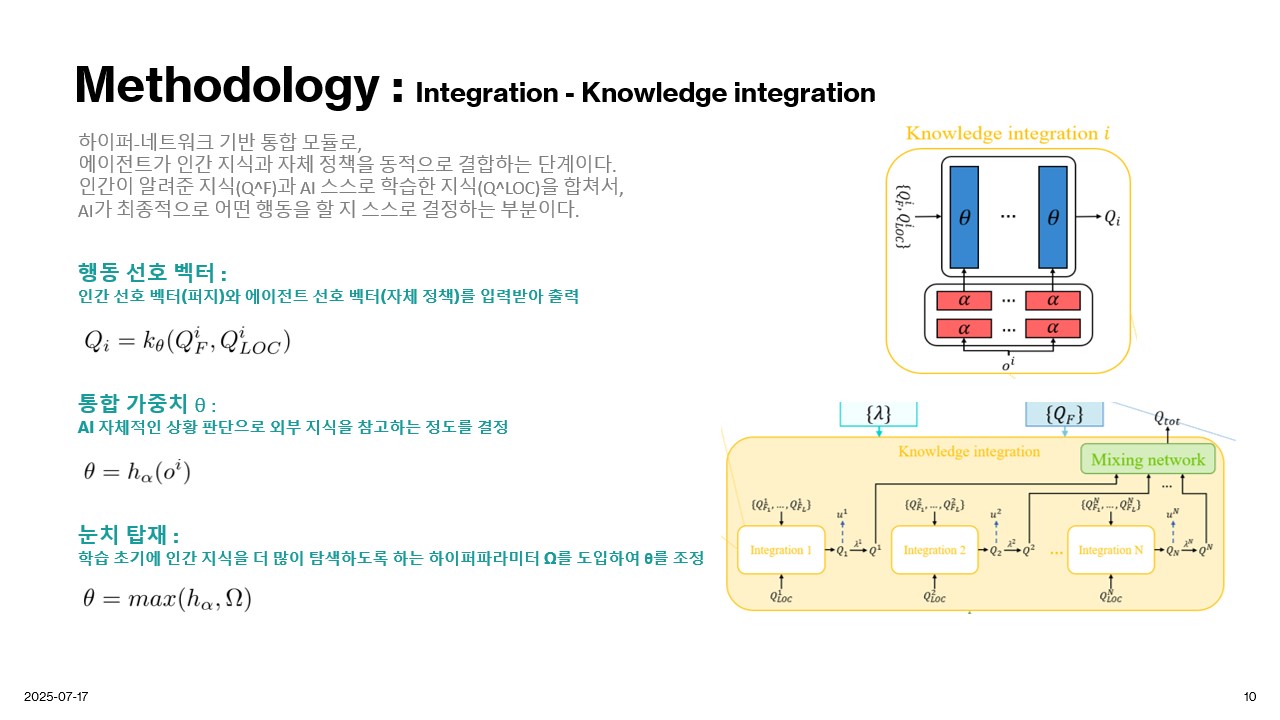
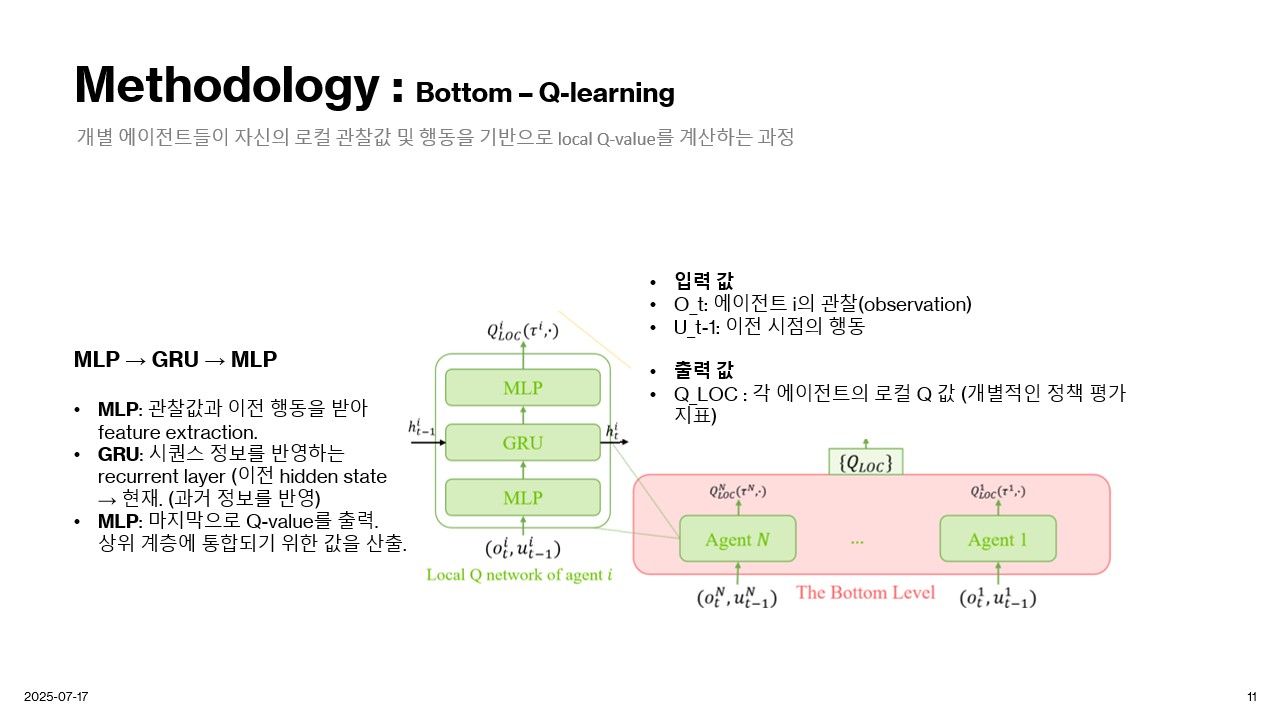


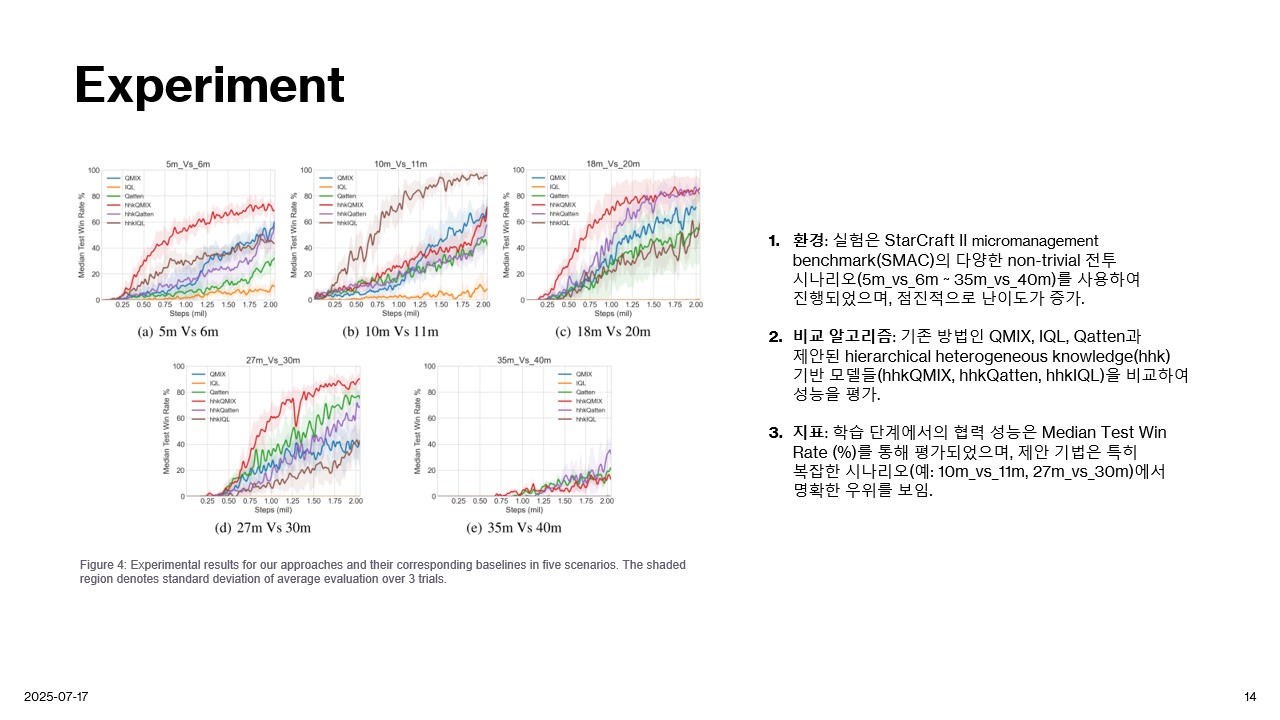
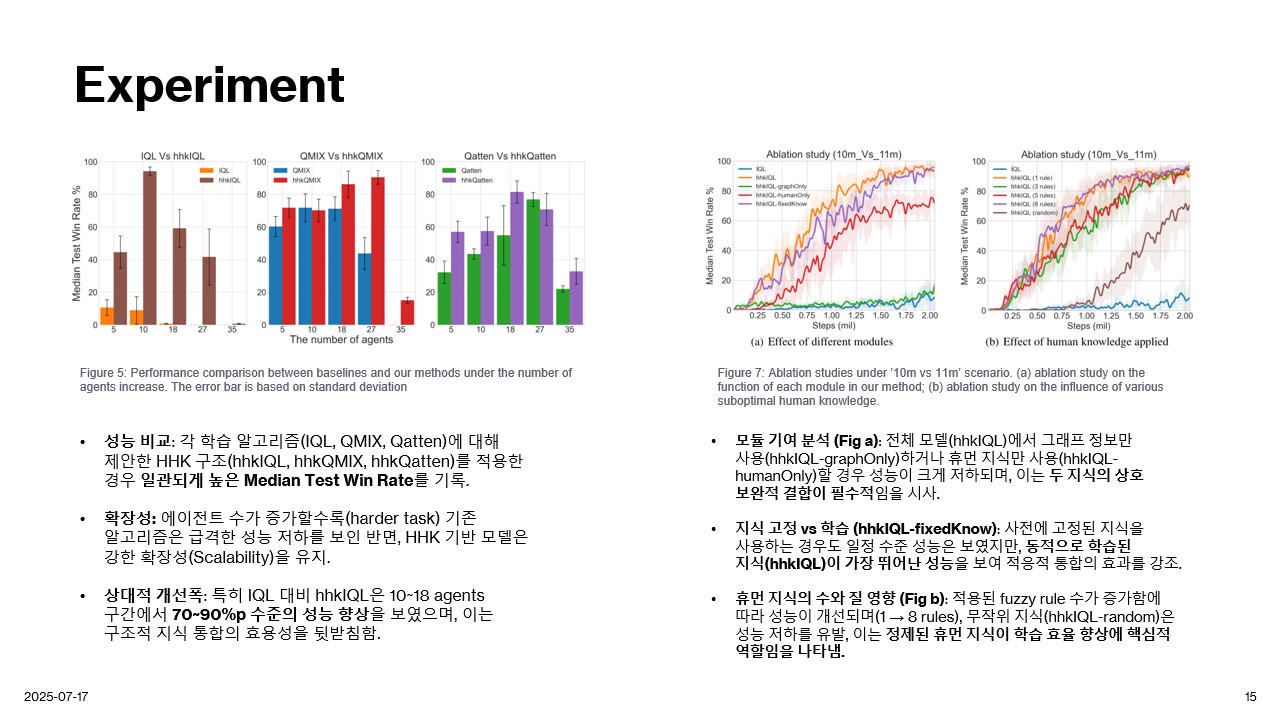
Experiment
Conclusion

Limitations & Application Ideas


Appendix & Reference


