학습 동기
개발 과정에서, 백엔드 API 요청 시 응답이 때때로 느려지는 문제에 직면했다. 일반적으로 응답 시간은 100ms 이내였고, 데이터 요청이 많을 경우에도 200ms ~ 300ms 범위 내에 있었다. 그러나 가끔 (예상보다 더 자주) 700ms 이상의 응답 시간이 소요되곤 했다. 이 문제를 해결하기 위해 동료가 Nginx 설정을 통해 HTTP/2를 적용하는 것을 제안했고, 이를 시도한 결과 응답 시간 문제가 대부분 해결되었다. 그러나 HTTP/2가 왜 더 안정적인 응답을 제공하는지에 대한 명확한 이해가 부족하여, 이번 기회에 HTTP에 대해 공부하기로 결심했다.
버전별 HTTP를 이해하기 위해 알아야 할 내용
HTTP
HyperText Transfer Protocol의 약자로 Web 상에서 데이터 송 수신을 위한 프로토콜이다. HTTP는 이론상으로든 어떤 전송 계층(TCP, UDP)를 사용해도 문제가 없지만 주로 TCP 프로토콜을 사용한다.
TCP
TCP 에서는 신뢰있는 데이터 송 수신을 위해서 연결에는 3 way handshake, 연결을 끊을때는 4 way handshake 방식을 사용한다.
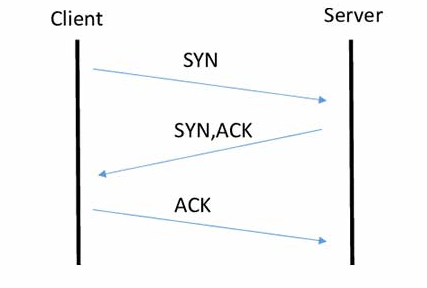
위 그림은 3 way handshake를 간략히 그려놓은 그림으로 설명하면 다음과 같다.
-
클라이언트가 서버에 연결을 요청. 이를 "SYN" 패킷이라 부르고 클라이언트가 선택한 임의의 숫자인 초기 순서 번호(ISN, Initial Sequence Number)를 포함해서 전송한다.
-
서버는 클라이언트의 요청을 받았다는 확인 신호로 "SYN-ACK" 패킷을 보낸다. 이 패킷은 서버가 자신의 ISN과 클라이언트가 보낸 ISN을 기반으로한 확인 응답이다.
-
클라이언트는 마지막 단계로, 서버에게 "ACK" (Acknowledgment) 패킷을 보냅니다. 이 패킷에는 서버의 ISN과 서버로부터 받은 확인 응답 번호가 포함되어 있습니다.
이와 같은 3단계 과정을 통해 클라이언트와 서버는 서로에 대한 초기 연결을 설정하게 된다.
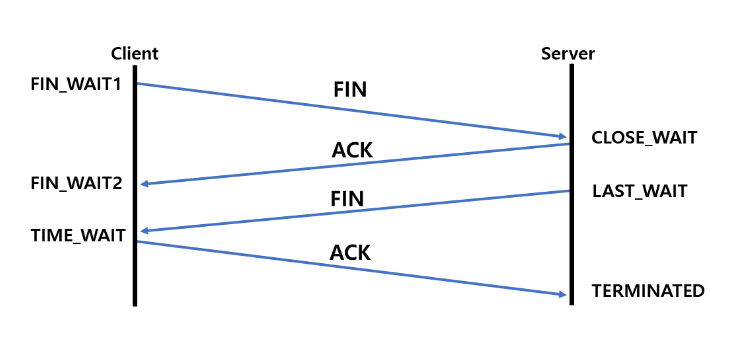
-
클라이언트에서 서버와의 연결 종료를 위해 서버에 FIN 패킷을 보내고 FIN_WAIT1 상태가 된다.
-
서버는 클라이언트로부터 FIN을 받고 응답 패킷 ACK을 보낸다. 상태는 CLOSE_WAIT가 된다.
-
서버가 통신이 끝나면, 즉 연결을 종료할 준비가 되면 클라이언트에게 FIN패킷을 보내고 LAST_WAIT 상태가 된다.
-
클라이언트는 확인 패킷 ACK을 보내고 TIME_WAIT 상태가 된다.
위 과정을 통해 서버와 클라이언트는 안전하게 세션을 종료하게 된다. handshake는 통신의 신뢰성을 높이지만 RTT가 증가하는 문제점이 있다.
RTT(Round Trip Time): 패킷이 목적지에 도달하고 나서 다시 출발지로 돌아오기까지 걸리는 시간이려 패킷 왕복 시간이다.
패킷: pack + buecket를 합친 단어로 컴퓨터 네트워크에서 데이터를 전송하는 단위다. 데이터를 작은 조각으로 나누어 전송하고, 각 조각을 패킷이라고 부른다. 패킷은 기본적으로 헤더와 페이로드로 구성되어 있음
헤더: 패킷의 제어 정보를 포함하며, 송신자와 수신자의 주소, 패킷 순서, 오류 검출 및 복구를 위한 체크섬 등이 포함된다. 헤더 정보를 통해 패킷이 어디로 가야 하는지, 어떻게 처리되어야 하는지 등의 정보를 확인
payload: 전송되는 데이터를 의미한다. 페이로드(payload)라는 단어는 운송업에서 비롯하였는데, 지급(pay)해야 하는 적화물(load)을 의미한다. 예를 들어, 유조선 트럭이 30톤의 기름을 운반한다면 기름 이외에 운송시 들어가는 무게가 있다. 하지만 고객입장에서는 오직 기름의 무게만을 지급(pay)하면 된다. IT에서는 패킷에 실제 data 외에도 부가 정보가 많다. 이 중 데이터만을 payload로 이해하면 된다.
UDP

TCP와는 다르게 handshake 과정이 없이 데이터를 주고 받기 때문에 굉장히 빠르다. 그러나 이 때문에 요청에 대해 응답 받는다는 보장이 없기 때문에 신뢰성이 떨어진다.
TCP vs UDP
| TCP | UDP | |
|---|---|---|
| 연결 방식 | 연결형 서비스 | 비연결형 서비스 |
| 패킷 교환 | 회선 교환 가상회선 | 데이터그램 가상회선 |
| 전송 순서 보장 | 보장함 | 보장하지 않음 |
| 신뢰도 | 높음 | 낮음 |
| 전송 속도 | 느림 | 빠름 |
회선 교환 방식: 데이터 전송을 위해 논리적인 회선을 미리 확립하고 유지한 후, 데이터를 전송하며, 데이터의 순서를 보장하고 손실된 패킷을 다시 전송하는 등의 기능을 제공하여 안정적이고 신뢰성 있는 통신을 지원한다.
데이터 그램 교환 방식: 논리적인 회선을 미리 확립하지 않고, 데이터 패킷마다 경로가 독립적으로 설정됩니다. 패킷은 목적지까지 도달할 때까지 각각 다른 경로를 따를 수 있다. 이 방식은 인터넷의 IP 기반 네트워크에서 주로 사용되며, 회선을 예약하지 않기 때문에 자원의 효율성이 높은 특징이 있음.
버전별 HTTP
HTTP/0.9
[request]
GET /mypage.html
[response]
<HTML>
A very simple HTML pagge
</HTML>굉장히 심플한 구조로 이루어져 있다. 요청은 단일 라인이고 GET 메소드가 유일하다. 응답 또한 파일 내용 자체로만 구성되며 헤더가 없고 HTML 파일만 전송 가능하다.
상태와 오류 코드도 없기 때문에 문제가 발생한 경우 HTML 파일이 사람이 처리할 수 있도록, 해당 파일 내부에 문제에 대한 설명과 함께 되돌려 보냈다.
HTTP/1.0
[request]
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
[response]
200 OK
Date: Tue, 15 Nov 1997 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
A page with an image
<IMG SRC="/myimage.gif">
</HTML>content-type이 생기면서 html 외에도 여러 타입의 데이터를 전송할 수 있게 되었다. 응답 상태가 추가됨에 따라 서버의 응답이 어떤지 알 수 있게 되었고, 기본적으로 우리가 사용하는 HTTP의 형태를 갖췄다고 보면 된다.
HTTP/1.0의 문제점
http/1.0의 큰 문제점은 매번 Connection 할 때 마다 handshake를 한다는 점이다. 신뢰성을 높이는 좋은 방법이긴 하지만 매번 요청 응답마다 connection을 생성하는 것은 비효율적이다.
HTTTP/1.1
HTTP/1.1은 1.0의 매 요청마다 발생하는 Connection시 handshake 문제를 해결하기 위해 나왔다.
Persistant Connection
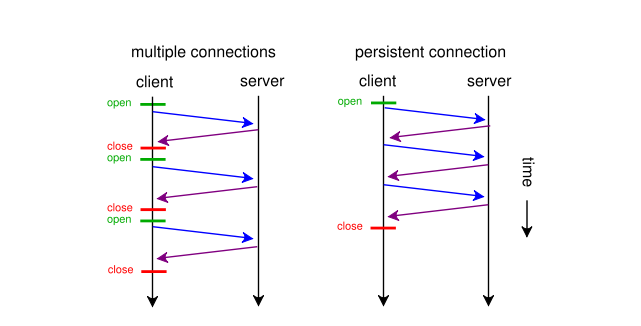
multiple connection은 http/1.1 이전의 동작 방식으로 매번 open/close 마다 connection을 생성하지만 persistent connection 방식은 connection을 계속 유지하고 여러 요청과 응답을 수행한다.(http 1.0에 keep-alive가 있지만 1.1에 와서 표준화 됨) 그리고 하나의 connection에서 복수의 응답을 처리하고 제공하기 위해 pipelining 기법이 사용된다.
pipelining: 하나의 커넥션에서 응답을 기다리지 않고 순차적인 여러 요청을 한번에 처리함으로써 시간 지연을 줄일 수 있음.
HTTP/1.x의 문제점
1.1버전에서 성능상 발생할 수 있는 문제점에 대해 알아보자...
Head of Line Blocking
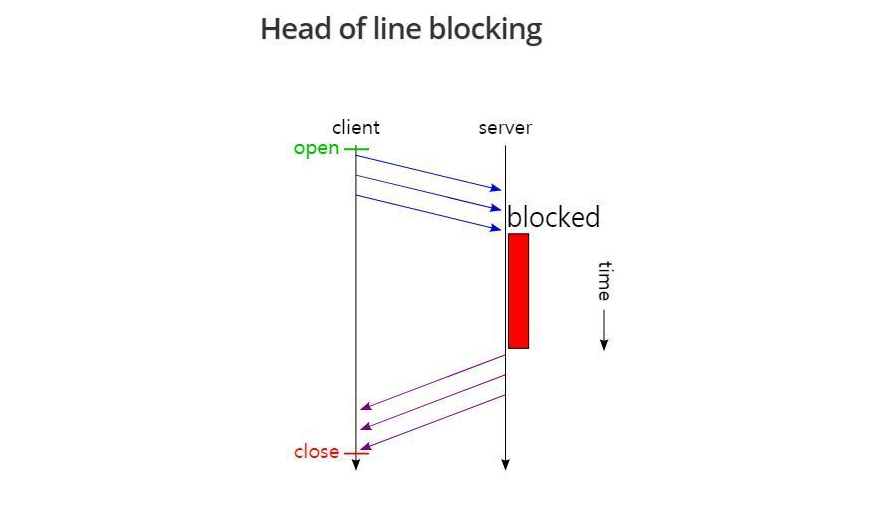
pipelining 방식은 여러 요청을 한번에 보내서 커낵션 비용을 줄일 수 있지만 문제점은 결국 서버에서는 패킷을 순차적으로 처리하기 때문에 하나의 요청 처리가 오래걸리게 되면 전체적으로 응답이 늦어지는 문제점이 발생한다.
이것만으로는 크게 가슴에 와닿지 않는다. 다음과 같은 상황의 예시를 들어서 이해해보자.

우리가 서버로 부터 image.jpg와 style.css, data.xml등을 받아야 한다고 가정해보자. 같은 큐에 3개의 패킷이 들어갈 것이다. 그러나 이를 서버에서 받아오기 위해 Connection을 여러번이 아닌 한번만 하더라도 첫번째 패킷이 오랫동안 지연되면 나머지 패킷 응답은 짧더라도 결국 RTT가 증가하게 된다.
헤더 구조의 중복
| :method | GET |
| :scheme | https |
| :host | example.com |
| :path | /resource |
| accept | image/jpeg |
| user-agent | Mozilla/5.0 |
위 헤더 구조에서 path가 /resource -> /new_resource로 바뀌면 나머지 테이블 중복되고 path 하나만 다른 테이블이 생성된다. 하나의 속성만 달라졌는데 똑같은 크기의 헤더를 생성하니 의도치 않게 중복되는 헤더가 많아지고 이는 전송 속도에 영향을 주게 된다.
HTTP/2.0
HTTP 2.0은 새로운 기능이 추가된 것이 아니라 HTTP/1.x 버전의 문제점을 개선하고 성능을 향상시켜서 나온 버전이다.
1.x의 문제점을 개선하기 위해 한 작업을 살펴보자.
분할된 바이너리 프레임 방식 사용
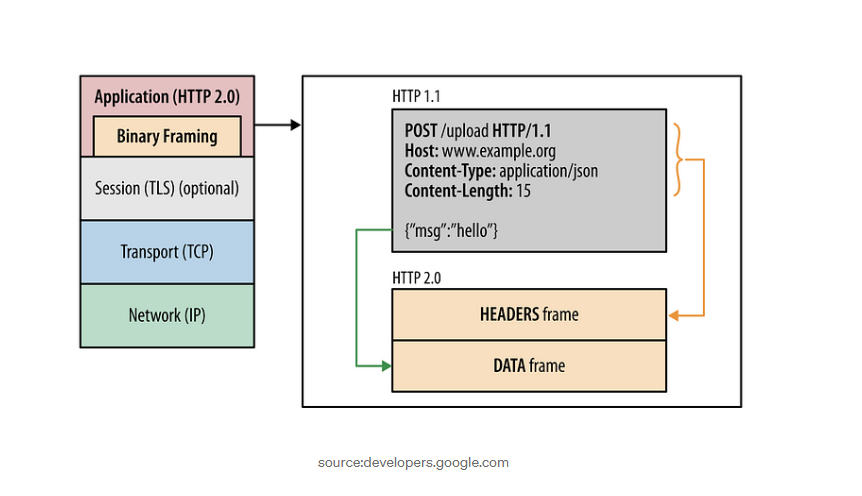
기존에는 단순히 모든 정보가 Text Message 형태로 존재했다. 그러나 HTTP 2.0에서는 Header와 Data 2개의 binary frame으로 분할해서 전송한다. 일반 텍스트 방식에 비해 바이너리가 가지는 이점은 바이너리는 순수 0 또는 1로 이루어져 있기 때문에 Ascii 방식의 문자열보다 데이터 크기가 작다. 뿐만 아니라 컴퓨터는 바이너리를 직접 처리하는데 최적화되어 있다. 이 때문에 바이너리를 사용하면 전송 속도가 올라가고 빠르게 처리가 가능해진다.
프레임 구조

- Frame: HTTP/2에서 통신의 최소 단위이며, Header 혹은 Data
- Message: HTTP/1.1과 마찬가지로 요청 혹은 응답의 단위이며 다수의 Frame으로 이루어진 배열 라인
- Stream: 연결된 Connection 내에서 양방향으로 Message를 주고 받는 하나의 흐름
요청 및 응답 다중화
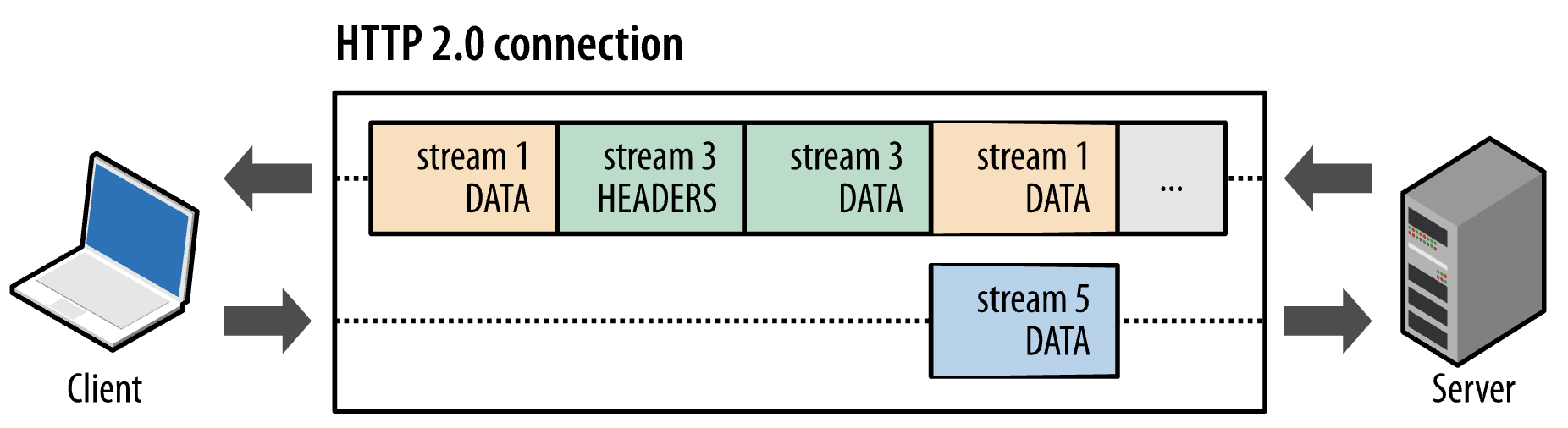
Stream 방식을 사용하면서 병렬적으로 요청하고 서버는 이를 병렬적으로 처리할 수 있게 되었다. 그리고 따로 기다릴 필요 없이 클라이언트는 서버로부터 받은 프레임들을 조립해서 수신받게 된다. 이를 통해 HOL Blocking 문제를 해결할 수 있게 된다.
Stream Prioritization
문서 내에 CSS 파일 1개와 이미지 파일 2개가 존재하고 이를 클라이언트가 요청하는 상황에서, 이미지 파일보다 CSS 파일의 수신이 늦어진다면 브라우저 렌더링에 문제가 생긴다. 이를 리소스 간의 의존관계에 따른 우선순위를 설정하여 리소스 로드 문제를 해결할 수 있다.
서버 푸쉬
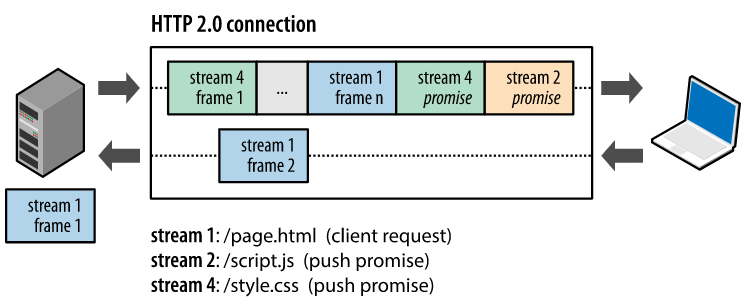
서버 푸쉬는 클라이언트가 하나만 요청해도 서버가 알아서 필요한 리소스를 클라이언트에 전송하는 기능이다. 서버는 요청하지도 않은 리소스를 미리 보내 특정 개체가 필요할 때 바로 사용 가능하도록 하여 성능을 향상시킬 수 있다.
참고
https://www.youtube.com/watch?v=xcrjamphIp4
https://brunch.co.kr/@sangjinkang/4
https://lovejaco.github.io/posts/head-of-line-blocking/
https://medium.com/@shaved786/introduction-to-http-2-8aa8c565d008
https://www.bottlehs.com/springboot/http-1-http2-%EA%B8%B0%EB%B3%B8-%EA%B0%9C%EB%85%90/
https://enlqn1010.tistory.com/9
https://www.youtube.com/watch?v=DDlOQYuE1i4
https://inpa.tistory.com/entry/WEB-%F0%9F%8C%90-HTTP-20-%ED%86%B5%EC%8B%A0-%EA%B8%B0%EC%88%A0-%EC%9D%B4%EC%A0%9C%EB%8A%94-%ED%99%95%EC%8B%A4%ED%9E%88-%EC%9D%B4%ED%95%B4%ED%95%98%EC%9E%90

좋은 정보 감사합니다