
Stream, Iterable 반환 타입의 문제점
java8에서 새로 생긴 Stream은 Iterable과 호환되지 않는다. Stream은 Stream 연산만 지원하면 for 구문 사용시 호환되지 않고 Iterable 역시 Stream을 사용할 수 없다.
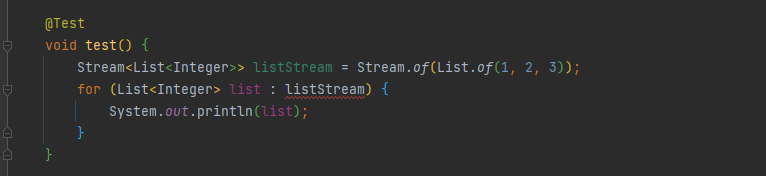
다음과 같은 코드를 보면 List를 포함하는 Stream을 만들고 이에 for문을 호출하면 다음과 같은 컴파일 에러를 볼 수 있다.

Iterable 타입 역시 마찬가지다. Iterable 인터페이스를 정의하면 for loop를 사용할 수는 있지만 Stream과 호환되지 않는다.
Stream과 Iterable간의 어댑터 메서드 제공해서 문제 해결하기
개발자들마다 선호하는 방식이있다. 어떤 분은 Stream을 선호할 것이고 어떤 분은 Iterable를 선호할 수 있다. 이 때 Iterable과 Stream을 서로 변환하게 해주는 헬퍼 메서드를 만들어 주면 된다.
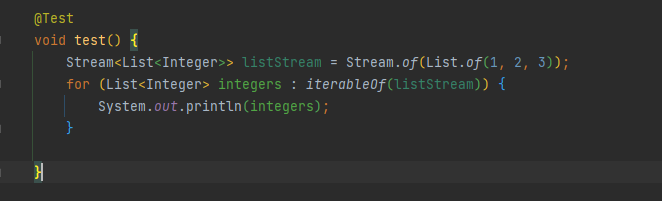
// stream -> Iterable
private static <E> Iterable<E> iterableOf(Stream<E> stream) {
return stream::iterator;
}
// Iterable -> stream
private static <E> Stream<E> streamOf(Iterable<E> iterable) {
return StreamSupport.stream(iterable.spliterator(), false);
}어댑터를 통해 문제를 해결할 수는 있지만 공개 API 사용시 다른 개발자들이 사용하기 조금은 불편할 것이다.
Collection 활용하기
Collection은 Stream과 Iterator 모두 지원
Collection는 Stream과 Iterator를 모두 지원한다. 그렇기에 책에서는 되도록 Collection을 반환하는 것을 추천한다.
Collection이 둘 모두를 호환하는 이유는 Collection은 Iterable의 하위 타입이며 stream 인터페이스를 지원하는 메서드 모두 존재하기 때문이다.
Collection의 한계
Collection이 둘 모두 호환이 가능하기에 되도록 Collection을 반환하는 것은 좋은 방법이다. 그러나 Collection은 시퀀스의 크기가 메모리에 올려도 안전할 때 사용해야 한다. 만약 Collection에 담아야할 메모리가 너무 크다면 표준 Collection보다는 상황에 따라 효율적으로 저장할 수 있는 Custom Collection 타입을 구현하는 것이 더 좋을 수 있다.
커스텀 Collection 활용하기
예를 들어 멱집합을 Collection에 저장해야 한다고 가정하자.
멱집합: 한 집합의 부분집합을 원소로 하는 집합 -> {a,b} => {{}, {a}, {b}, {a,b}}
만약 원소의 갯수가 n개라면 2^n 만큼 크기의 데이터를 저장해야 한다. 이런 경우 원소 크기에 따라 저장해야하는 데이터가 엄청나게 빠른속도로 늘어나고 메모리가 터질 가능성이 있다.
이럴 때 java Collection에서 제공하는 템플릿인 AbstractList를 활용하면 전용 컬렉션을 쉽게 구현할 수 있다.
public class PowerSet {
public static <E> Collection<Set<E>> of(Set<E> s) {
List<E> src = new ArrayList<>(s);
if (src.size() > 30) {
throw new IllegalArgumentException("Set too big " + s);
}
return new AbstractList<Set<E>>() {
@Override
public int size() {
return 1 << src.size();
}
@Override
public boolean contains(Object o) {
return o instanceof Set && src.containsAll((Set) o);
}
@Override
public Set<E> get(int index) {
Set<E> result = new HashSet<>();
for (int i = 0; i != index; index >>= 1) {
if ((index & 1) == 1) {
result.add(src.get(i));
}
}
return result;
}
};
}
}예제에서는 PowerSet을 헬퍼 메서드를 이용해 정적 팩토리 메서드를 구현했지만 상황에 따라서 직접 Collection의 하위 타입으로 선언해서 멱집합으로 활용할 수도 있다.
위의 코드의 단점은 다음과 같다.
AbstractList를 이용해 간이 Collection 클래스를 리턴하면 공개 API로 add, remove 등을 제공하지만 모두 구현하지 않았으므로 UnSupportedOperationException이 뜬다는 점(컴파일 단계에서는 알수 없으므로 실수할 여지가 있다) Collection의 size는 int를 기반으로 동작하기 때문에 여전히 용량에는 한계가 있다는 것이다.
책에는 없는 내용이지만 AbstractList의 부작용을 해결하기 위해 일급 컬렉션을 활용하는 방법도 있다. 일급 컬렉션은 List를 컴포넌트로 사용해 공개 API를 원하는 로직에 맞게 재설계한다. 이 방법은 상속보다 훨씬 안전한 방법이다. 그러나 직접 Iterable를 구현해야 할 수 있고 시퀀스 자체로 사용하기에는 조금 아쉬운 부분이 있다.
다시 stream으로 돌아와서
Stream 리턴이 꼭 안좋은 것만을 아니다. Collection을 사용하는 것을 우선하지만 Collection을 사용하기 힘든 경우 Stream은 좋은 대안이 될 수 있다.
for (int start = 0; start <src.size(); start++) {
for (int end = start + 1; end.size(); end++) {
System.out.println(src.subList(start, end));
}
}만약 위의 코드의 결과를 새로운 데이터에 담아서 저장해야 한다면 src 좀만 커져도 MPE가 뜰 가능성이 높다. 이런 경우 Stream을 리턴하는 것이 용이할 수 있다.
public static <E> Stream<List<E>> of(List<E> list) {
return IntStream.range(0, list.size())
.mapToObj(start -> IntStream.rangeClosed(start + 1, list.size())
.mapToObj(end -> list.subList(start, end)))
.flatMap(x -> x);
}아래 코드는 위의 코드와 동일하다. 2개의 IntStream을 활용해 이중 for문을 흉내낼 수 있다. 그리고 이렇게 내부적으로 생성된 Object에는 중첩된 stream이 존재하는데 이를 flatMap을 이용해 평평하게 만들어준다. 쉽게 타입으로 설명하자면
Stream<Stream<List<E>>> -------> Stream<List<E>>로 바꿔주는 작업이라 생각하면 된다.
이를 활용하면 큰 수라도 무리 없이 리턴으로 처리할 수 있다. 그 이유는 최종 연산이 아니면 stream은 동작하지 않고 동작만 정의하기 때문이다.
flatMap: 차원을 낮추는데 사용한다. 내부적으로 stream인 경우 그대로 x -> x 와 같은 형태로 사용하며 stream이 아닌경우는 stream으로 감싸서 인자로 넘겨줘야한다.
public class Solution {
public static void main(String[] args) {
Stream<List<Integer>> of = of(
IntStream.rangeClosed(1, 1000000).boxed().collect(Collectors.toList()));
}
public static <E> Stream<List<E>> of(List<E> list) {
return IntStream.range(0, list.size())
.mapToObj(start -> IntStream.rangeClosed(start + 1, list.size())
.mapToObj(end -> list.subList(start, end)))
.flatMap(x -> x);
}
}
결론
Stream, Iterable 모두 처리 가능한 Collection 타입을 리턴하도록 하자. 만약 적절한 Collection 타입이 없다면 상속으로 활용해 Collection 하위 타입을 구현하고, 이도 마땅치 않다면 최종적으로 Stream 타입 리턴을 고려할 수 있다.
