
자바의 경우 메모리를 자동으로 가비지 컬렉터가 관리해주기 떄문에 C, C++ 보다 메모리 관리하기가 편하다. 그러나 자칫 메모리를 관리할 필요 없다고 생각할 수도 있는데, 그것은 사실이 아니다.
배열과 메모리 누수
java 라이브러리의 스택을 살펴보자
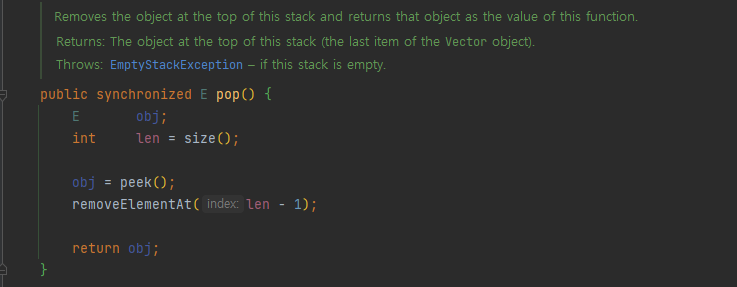
스택은 Vector를 상속받는데 Vector에 다음과 같은 메서드가 있다.
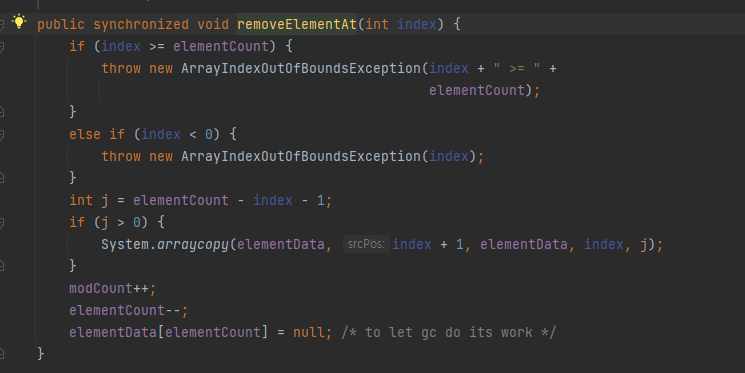
여기서 특이한 점은 elementCount-- 이후에 elementData[elementCount] = null 로 지정했다는 것이다. 이렇게 지정한 이유는 무엇일까?
우리가 pop을 하고 해당 element를 null로 처리하지 않으면 해당 클래스의 사이즈는 줄어있다고 생각하지만 실제 배열에는 해당 객체를 참조하고 있다. 그래서 이들은 실제로 사용하지는 않더라도 가비지 컬렉터가 객체를 삭제하지 못한다.
이런 실수를 예방하는 방법은 2가지다.
null을 활용한다.
위에 사진을 살펴보면 null을 이용해 배열에 할당된 객체를 해제했다. 이 경우 그 공간으로 접근하는 경우 NPE를 발생시킬수 있는 이점이 있고, 메모리 누수를 예방할 수 있다. (컬렉션 리스트의 경우 내부에 배열을 사용하는데 null처리가 기본적으로 되어있다.)
Collection을 사용한다.
가끔 자바 코드를 짤 때 코드를 클린하게 사용하기 위해서 배열보다 Collection을 적극적으로 활용하라고 한다. 성능은 배열보다 떨어질 수 있으나 안전하고, 배열을 통한 메모리 누수 실수를 예방할 수 있다.
내부 배열 저장소 풀 => 메모리 누수에 취약
stack, ArrayList와 같은 클래스들은 객체 스스로 내부에 메모리를 직접 관리한다. 그러나 이런 내부 메모리의 값이 더 이상 참조하지 않는다면 반드시 null처리를 해주어야한다.
캐시와 메모리 누수
자바의 HashMap을 살펴보자. 우리가 보통 HashMap을 쓰는 이유는 key - value를 활용한 캐싱이다. 그러나 간과하기 쉬운 실수는 객체를 사용하지 않는데도 계속해서 캐싱하는 경우이다. 이런 경우 사용하지 않는데 객체가 그대로 캐싱되어 있어서 메모리 누수가 생긴다. 이를 해결하는 방법은 다음과 같다.
Scope를 활용한다.
가장 안전하고 편한 방법이다. 이 방법은 위에 배열을 저장소 풀로 가지는 클래스도 해당되는 내용이다. 그러나 HashMap 캐싱이 다른 클래스 간에 사용하고 캐싱 객체를 길게 유지해야 하는 경우는 Scope 방식이 힘들 수 있다.
WeakHashMap 활용
WeakHashMap을 사용하는 경우 외부의 키를 참조해서 캐싱한다. 그 이후 외부 키가 더이상 사용되지 않으면 사용된 엔트리는 즉시 자동으로 제거된다. 다만 이 경우에만 한정되게 사용할 수 있다.
LinkedHashMap 활용
LinkedHashMap를 상속받아 removeEldeestEntry를 오버라이딩하면 캐싱 생존 전략을 본인이 커스터마이징 할 수 있다.
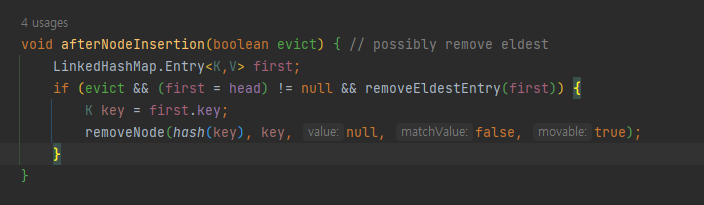
HashMap의 putVal에서 이 afterNodeInsertion을 사용하는데 상속받은 LinkedHashMap은 afterNodeInsertion은 위의 코드와 같이 오버라이딩함으로써, removeEldestEntry 조건에 따라 map에 데이터를 넣을시 removeEldestEntry와 일치하는 데이터를 제거한다.
이를 이용해 우리가 원하는 캐싱전략을 구사할 수 있다. 그 예는 LRUCache이다.
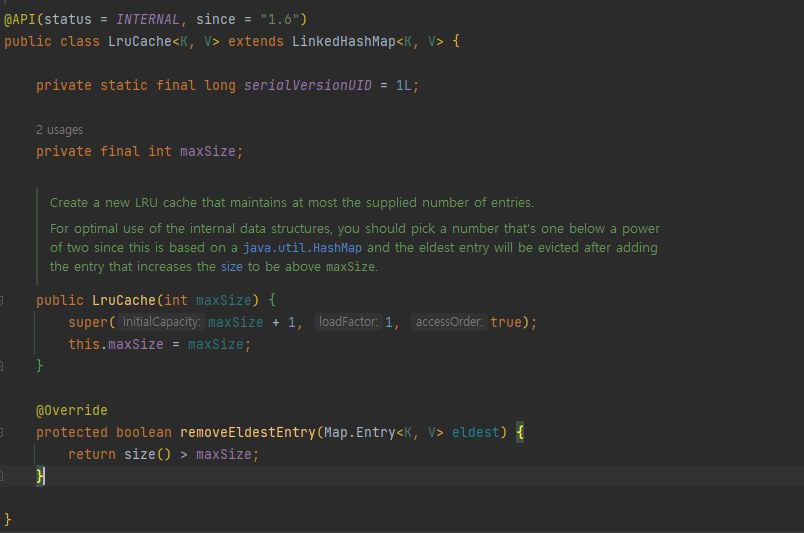
위의 삽입시 삭제 전략은 삽입후 현재 size가 LruCache 클래스의 maxSize보다 커지는 경우 가장 오래된 entry를 삭제한다. 이와 같은 전략을 이용해 간단하게 caching을 구사할 수 있다.
이와 같은 방식을 활용할 수 있는 이유는 LinkedHashMap은 삽입한 시점의 순서를 보장하며 오래된 데이터를 판단할 수 있기 때문이다.
ex)
만약 return size() > 6 이렇게 해둔다면 사이즈가 6을 초과하면 가장 오래된 데이터를 제거하고 새로운 데이터를 채워 넣는다.
