딕셔너리에 적용되는 메서드
(1) keys()/ values() (2) get() (3) items()
(1) keys() /values()
keys() : Returns a list containing the dictionary's keys
values() : Returns a list of all the values in the dictionary
🍟 딕셔너리의 key값, value값만을 보여준다.
Example
a = {'jisoo': 'apple', 'minsu': 'banana', 'minhyuk': 'grape'}a.keys() #dict_keys(['jisoo', 'minsu', 'minhyuk']) a.values() #dict_values(['apple', 'banana', 'grape'])
- 반환 형태가
list같지만type()로 확인해보면 아님!- 딕셔너리 -> 리스트, 튜플 로 변환해 사용하는 경우 多
(2) get()
get() : Returns the value of the specified key
🍟 지정한 key의 value값을 반환한다.
Example
a = {'jisoo': 'apple', 'minsu': 'banana', 'minhyuk': 'grape'}a.get('minhyuk') #'grape'
- dict.get( keyname,
0) :value값이 없을 때0으로 설정
(3) items()
items() : Returns a list containing a tuple for each key value pair
🍟 key값과 value값을 tuple형식으로 반환한다.
Example
a = {'jisoo': 'apple', 'minsu': 'banana', 'minhyuk': 'grape'}a.items() #dict_items([('jisoo', 'apple'),('minsu', 'banana'), ('minhyuk', 'grape')])
dict_item()의 반환값을list안에 넣으면[('jisoo', 'apple'),('minsu', 'banana'), ('minhyuk', 'grape')]리스트 메서드 적용 가능 ~ 😎

🍩 연습
가장 많이 나오는 단어 찾기
미드 <friends> script
Monica: There's nothing to tell! He's just some guy I work with!
Joey: C'mon, you're going out with the guy! There's gotta be something wrong with him!
(중략..)1차 코드
f = open('script.txt', 'r') for line in f : word = line.split() for i in word : print(word)
결과
Monica:
There's
nothing
to
tell!
He's
just
some
(중략..)🍕 review
- 특수문자가 붙으면 다른 단어로 인식 -> 지금 단계에선 패스
- 딕셔너리 형태로 표현하기 {'단어' : '갯수'}
2차 코드
f = open('script.txt', 'r') for line in f : word = line.split() for i in word : diclst = {} diclst[i] = diclst.get(i, 0) + 1 print(diclst)
결과
{'End': 1}🍕 reivew
- 마지막 단어 하나만 등장 ..?
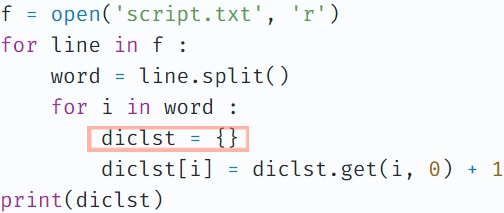
- 빈 딕셔너리 선언문의 위치 ->
for문 밖으로 빼기
계속 빈 딕셔너리로 초기화되니까 앞에 저장한 단어가 사라지고 마지막 단어만 남은거.. 😫
수정

결과
{'Monica:': 73, "There's": 5, 'nothing': 1,'to': 69, 'tell!': 1,
"He's": 1, 'just': 31, 'some': 8, 'guy': 6, 'I': 164, 'work': 3,
'with!': 1, 'Joey:': 41, "C'mon,": 4, "you're": 11, 'going': 7,
..생략
items()로 딕셔너리를 튜플형태로 변환 -> 숫자인value값을sort()를 사용해서 내림차순으로 정렬- 리스트안의 튜플을
sort하면 무엇을 기준으로 정렬되는지 확인.x = [('d', 2), ('a', 1), ('c', 342)] x.sort print(x) #[('a', 1), ('c', 342), ('d', 2)]
key값이었던 알파벳 순서로 정렬되는 것을 확인 ->
key값과value값을 반대로 정렬하는 게 선행되야함.
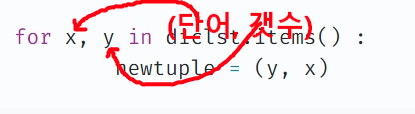
3차코드
f = open('script.txt', 'r') diclst = {} for line in f : word = line.split() for i in word : diclst[i] = diclst.get(i, 0) + 1 newlist = [] for x, y in diclst.items() : newlist.append((y, x) print(newlist[:5] newlist.sort(reverse=True) print(newlist[:5])
결과
(1)[(73, 'Monica:'), (5, "There's"), (1, 'nothing'),
(69, 'to'),(1, 'tell!')]
(2)[(164, 'I'), (98, 'a'), (93, 'and'), (89, 'you'),
(88, 'the')]
- (1) 튜플 내
key와value의 위치가 바뀜- (2)
value값을 기준으로 내림차순 정렬됐음
🍕 Review
for문을 이용해서 튜플 unpack 하기- 제일 많이 등장한 단어는
I!! 😁
후기
역대급 어려운 연습문제였ㄷㅏ .. 💦 딕셔너리는 자주 사용하지 않아서인지 메서드를 적용한 결과를 예상하는 데 시간이 꽤 걸렸다.
Make my day !