퀵 정렬(quick sort)은 기준값(pivot)을 선정해 해당 값보다 작은 데이터와 큰 데이터로 분류하는 것을 반복해 정렬하는 알고리즘이다. 시준값이 어떻게 선정되는지가 시간 복잡도에 많은 영향을 미친다. 평균적인 시간 복잡도는 O(nlogn)이다.
퀵 정렬의 핵심 이론
pivot을 중심으로 계속 데이터를 2개의 집합으로 나누면서 정렬하는 것이 퀵 정렬의 핵심이다.
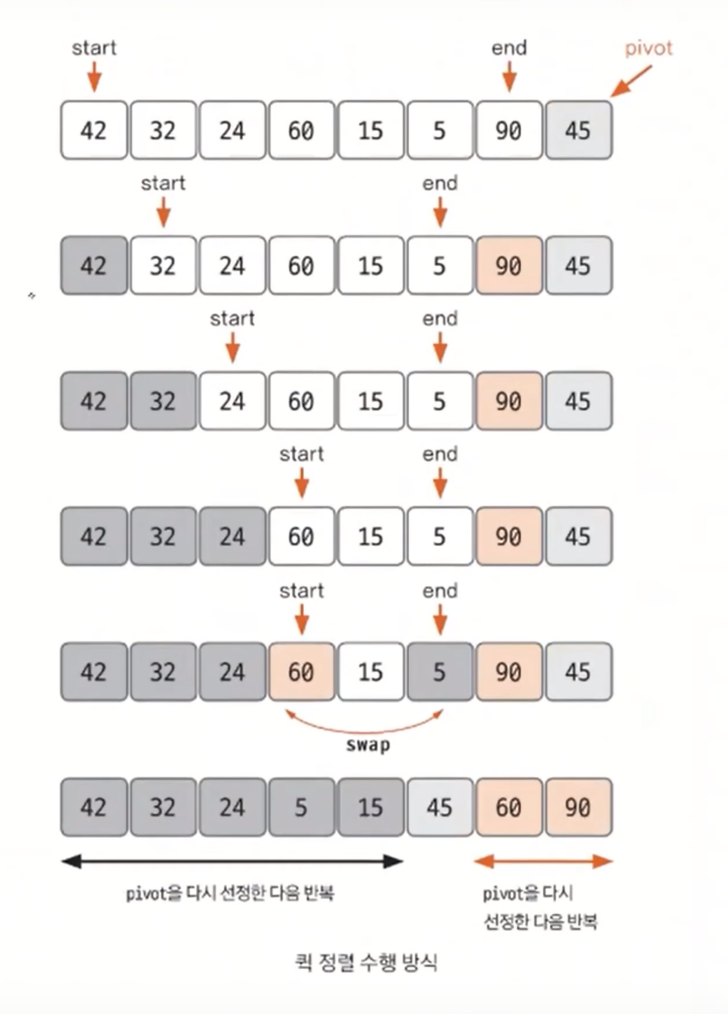
퀵 정렬 과정
- 데이터를 분할하는 pivot을 선정한다(위 그림의 경우 가장 오른쪽 끝을 pivot으로 설정).
- pivot을 기준으로 다음 a~e 과정을 거쳐 데이터를 2개의 집합으로 분리한다
2-a. start가 가리키는 데이터가 pivot이 가리키는 데이터보다 작으면 오른쪽으로 한칸 이동한다
2-b. end가 가리키는 데이터가 pivot이 가리키는 데이터보다 크면 왼쪽으로 한칸 이동한다
2-c. start가 가리키는 데이터가 pivot이 가리키는 데이터보다 크고, end가 가리키는 데이터가 pivot이 가리키는 데이터보다 작으면 start, end가 가리키는 데이터를 swap하고 start는 오른쪽, end는 왼쪽으로 한칸씩 이동한다.
2-d. start와 end가 만날 때까지 2-a ~ 2-c를 반복한다.
2-e. start와 end가 만나면 만난 지점에서 가리키는 데이터와 pivot이 가리키는 데이터를 비교해 pivot이 가리키는 데이터가 크면 만난 지점의 오른쪽에, 작으면 왼쪽에 pivot이 가리키는 데이터를 삽입한다. - 분리 집함에서 각각 다시 pivot을 선정한다
- 분리 집합이 1개 이하가 될 때까지 과정 1~3을 반복한다.
퀵 정렬의 시간 복잡도는 비교적 준수하므로 코딩 테스트에서도 종종 이용한다.
- Do it! 알고리즘 코딩테스트 자바 편
