
Index
Index는 원하는 데이터를 빠르게 찾기 위한 도구이다.
- 데이터 조회를 빠르게 하기 위해 사용된다.
- 데이터 INSERT, UPDATE, DELETE 쿼리 사용 시, 오히려 느려진다.
- SQL Server에서 Heap은 다음과 같은 의미를 가진다.
:Heap = 클러스터형 인덱스(Clustered Index)가 없는 테이블의 데이터 저장 구조
Index에 사용하는 자료구조
B-Tree
정렬된 데이터를 효율적으로 저장하고 검색할 수 있도록 설계된 트리 구조
특징
- 일반적으로 데이터베이스 인덱스 OR 파일 시스템에서 사용된다.
- 조회, 삽입, 삭제 연산 -> (O(log n))
- MySQL(InnoDB)에서 사용하는 인덱스 --> B+Tree
Hash
key를 Hash 함수에 넣어 나온 Hash value를 이용하여 배열 인덱스에 데이터를 저장한다.
특징
- 조회, 삽입, 삭제 연산 -> O(1)
- HashMap, Python의 dict, MySQL MEMORY 엔진의 Hash Index
B-Tree를 Index에 사용하는 이유
B-Tree
- 컬럼의 값을 변형하지 않고, 원래의 값을 이용하여 인덱싱한다.
Hash
- 컬럼의 값으로 해시 값을 계산해서 인덱싱하여 값을 변형하게 된다.
- 특정 문자로 시작하는 값으로 검색을 하는 등 전방 일치와 같이 값의 일부만으로 검색하고자 할 때, Hash index를 사용할 수 없다. (ex - LIKE, IN)
==> SELECT 절의 조건에 부등호 연산(>, <)이 포함될 경우 문제가 발생한다. HashTable은 동등 연산(=)에 특화되어있어 데이터베이스의 자료구조에 적합하지 않다.
Index 종류
Unique key
특징
-
값 중복을 허용하지 않는다.
-
primary key와 다르게, null 값을 허용한다.
-
primary key와 다르게, 테이블에서 한 개만 생성 가능하다.
-
2개 이상의 컬럼을 Unique index로 생성할 시, 앞 선 컬럼이 항상 더 중복성이 낮은(카디널러티가 높은)것으로 골라야 성능이 좋다.
Clustered Index
Def: 데이터베이스의 테이블의 레코드 순서를 Index의 키 값 순서대로 정렬하는 것을 의미한다.
ex ) Primary key (InnoDB 스토리지 엔진 기준)
특징
- 한 테이블 당 하나만 존재해야 한다.
- 가장 빠르게 처리한다.
- 조회는 빠르나 삽입 시 재정렬이 필요해 성능이 떨어질 수 있다. -> 재정렬이 일어나지 않고 순차적으로 쌓이는 컬럼에 설정해야 한다. (ex - id)
Non-Clustered Index
Def: 테이블에 저장된 물리적 순서에 따라 데이터를 정렬하지 않는다.
특징
- leaf node에는 데이터 페이지에 대한 포인터가 있어 이를 통해 데이터 페이지를 조회할 수 있는 형태
- 한 테이블에 여러 인덱스를 생성할 수 있다.
- 데이터 조회 시, leaf level에서 data 페이지에 접근하는 추가적인 step이 필요하기 때문에, clustered index 보다는 속도가 느리다.
- 데이터 입력 시, 약 10% 정도의 별도 공간에 인덱스를 생성해야 하기 때문에 추가 작업이 요구된다.
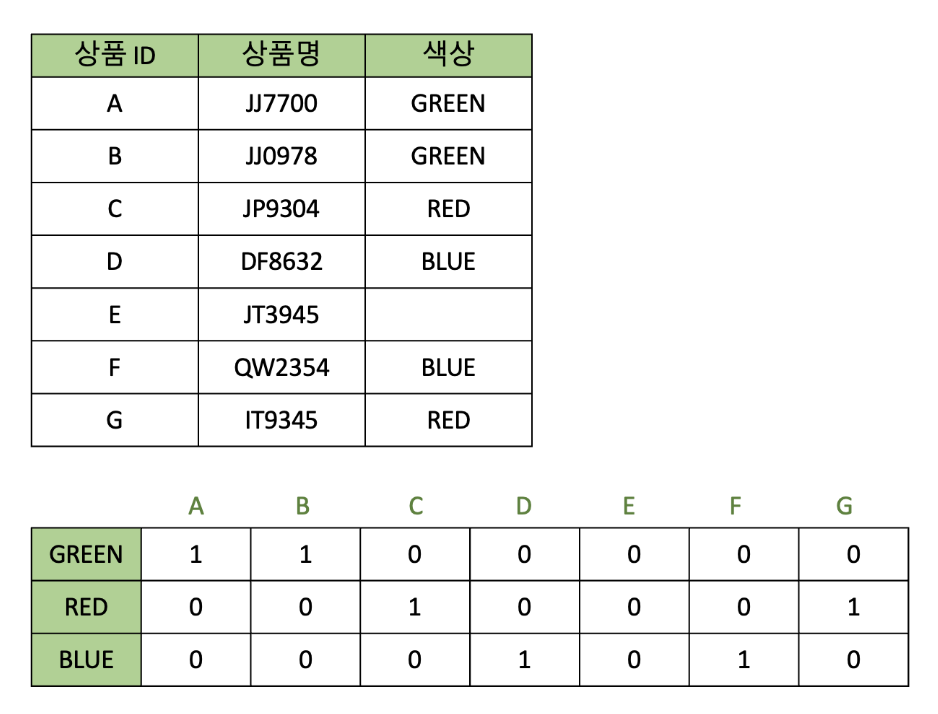
Bitmap Index
Def: 인덱스 컬럼의 데이터를 Bit 값인 0 또는 1로 변환하여 Index key로 사용하는 방법
특징
- 키 값을 포함하는 행의 주소를 제공한다는 목적을 제공한다.
- B-Tree 인덱스와 달리, 카디널리티(: 중복된 수치)가 낮은 경우(중복된 경우가 많은 경우)에 사용하기 좋다.
ex) 성별 테이블...?(이런 테이블을 만들 일이 있나...) - 효율적인 논리 연산이 가능하고 저장공간이 작다.
- 동일한 값이 반복되는 경우가 많기에 압출 효율이 좋다.
Secondary key
Def: 클러스터드 인덱스와 별개로 따로 만든 인덱스 = 필요한 컬럼만 저장 + Primary Key 값을 같이 저장
특징
- Primary key와 항상 같이 다녀야 한다.
- 인덱스에 테이블 일부 정보만 있다.
- 인덱스를 보고 테이블로 다시 찾아가야 한다.
- 읽는 I/O 수가 많다.
- 쿼리속도가 Clustered Index에 비해 느리다.
CREATE TABLE employees ( emp_id INT PRIMARY KEY, name VARCHAR(100), department_id INT, hire_date DATE, INDEX idx_name (name) );
- emp_id는 Primary Key → Clustered Index
- name은 Secondary Index (보조 인덱스)
그 외 : Fulltext Index, Composite Index
참조

Hi~