📊 SQL 고급 집계 정리: CTE, 윈도우 함수, ROLLUP, PIVOT
1. ✅ WITH CTE (Common Table Expression)
🔍 개념
CTE는 서브쿼리를 재사용 가능하고 가독성 좋게 만든 문법입니다.
복잡한 쿼리를 계층적으로 구성할 수 있습니다.
🛠 사용법
WITH cte_name AS (
SELECT ...
)
SELECT ...
FROM cte_name;📌 예시
WITH HighSalaryEmp AS (
SELECT *
FROM Emp
WHERE salary > 3000
)
SELECT ename, dept
FROM HighSalaryEmp;2. 🔁 윈도우 함수 (Window Functions)
🔍 개념
윈도우 함수는 집계함수처럼 동작하지만 그룹핑하지 않고도 각 행에 대해 누적합, 순위 등을 계산할 수 있습니다.
🛠 사용법
SELECT ename, salary,
SUM(salary) OVER (PARTITION BY dept) AS dept_total
FROM Emp;📌 자주 쓰는 함수
ROW_NUMBER(): 전체 결과에서 파티션 기준 출력되는 행 번호(순번)RANK(): 값의 랭킹(순위), 공동 랭킹은 동일값을 보이며 다음 랭킹은 공동 랭킹을 건너뛰어 표시DENSE_RANK(): RANK() 함수와 동일한 기능이지만 공동 랭킹을 건너뛰지 않는다.SUM() OVER(...)AVG() OVER(...)LAG(n): 현재 행 기준 앞(이전) n 번째 값LEAD(n): 현재 행 기준 뒤(다음) n 번째 값
📌 예시
SELECT ename, dept, salary,
RANK() OVER (PARTITION BY dept ORDER BY salary DESC) AS dept_rank
FROM Emp;3. 📈 GROUP BY WITH ROLLUP
🔍 개념
ROLLUP은 그룹핑된 컬럼을 기반으로 소계, 총계를 자동 계산합니다.
🛠 사용법
SELECT dept, job, SUM(salary)
FROM Emp
GROUP BY dept, job WITH ROLLUP;📌 예시
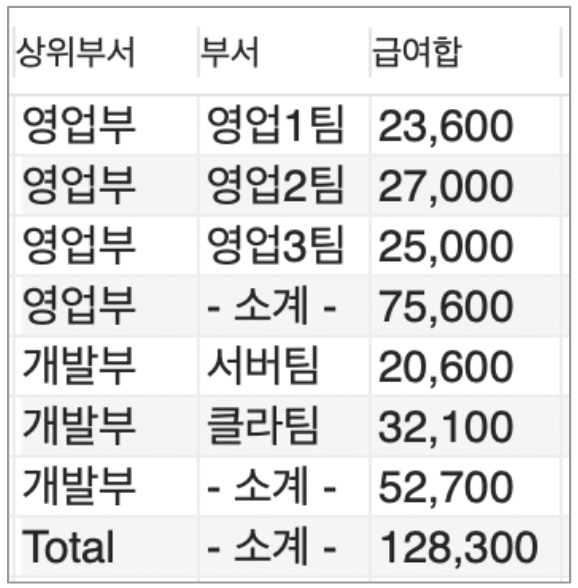
SELECT p.id pid, d.id did,
(CASE WHEN p.id IS NOT NULL THEN MAX(p.dname) ELSE '--총계--' END) AS '상위부서',
(CASE WHEN d.id IS NOT NULL THEN MAX(d.dname) ELSE '--소계--' END) AS '하위부서',
FORMAT(SUM(e.salary), 0) AS '급여합'
FROM Dept p
INNER JOIN Dept d ON p.id = d.pid
INNER JOIN Emp e ON e.dept = d.id
GROUP BY p.id, d.id
WITH ROLLUP;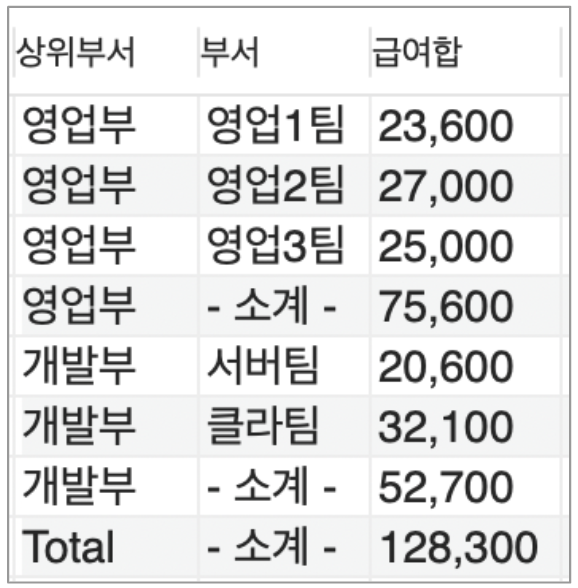
4. 🔄 PIVOT
🔍 개념
행 → 열로 전환해 집계 데이터를 보기 좋게 가공하는 방식입니다.
MySQL에는 직접적인 PIVOT 구문은 없지만, CASE WHEN + GROUP BY로 구현합니다.
🛠 사용법
SELECT dept,
SUM(CASE WHEN job = 'Manager' THEN salary ELSE 0 END) AS Manager,
SUM(CASE WHEN job = 'Clerk' THEN salary ELSE 0 END) AS Clerk,
SUM(CASE WHEN job = 'Sales' THEN salary ELSE 0 END) AS Sales
FROM Emp
GROUP BY dept;🧠 정리 요약
| 기술 | 목적 | 핵심 특징 |
|---|---|---|
WITH CTE | 복잡 쿼리 가독성 향상 | 서브쿼리 대체, 재사용 가능 |
| 윈도우 함수 | 누적, 순위 등 개별 행 통계 계산 | OVER() 사용, 그룹 유지됨 |
ROLLUP | 소계, 총계 자동 계산 | GROUP BY ... WITH ROLLUP 사용 |
| PIVOT | 행 → 열 전환, 가독성 향상 | CASE WHEN + GROUP BY 방식 |

Hi~