연관 내용
[버튼 눌러서 검색하기]
[debouncing ]
백엔드에서 검색 API를 구현하는 방법
1. 테이블 풀스캔 = 풀 테이블 스캔
-
Board.find({title: '%점심%'})등의 방법을 통해서 DB를 위에서부터 하나 하나 전체를 스캔해서 해당하는 값을 찾는다. -
시간이 오래 걸린다.
2. 역색인 = 역인덱스 = invertedIndex

-
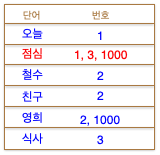
검색용 테이블을 하나 더 만들어서,
원래 들어있던 문장을 단어로 쪼개서 각 단어(token)에 해당하는 번호를 함께 저장해놓고, 검색할 경우 이 테이블에서 조회한다. -
더 빠르게 조회할 수 있다.
-
토크나이징: 문장을 토큰으로 쪼개는 과정
Elastic Search
-
검색용 테이블을 직접 만들어도 되지만,
이런 기능을 목적으로 만든 DB인 Elastic Search를 이용하면 더 편리하게 이용할 수 있다. -
ES는 디스크 기반 DB이다.
저장하고 조회할 때 DISK Input/Output이 일어난다. (줄여서 Disk I/O라고 부른다.) -
DISK I/O가 발생하기 때문에 비교적 속도가 느리다.
-
속도가 느린 반면에 컴퓨터를 껐다 켜도 데이터가 살아있다는 장점이 있다.
Redis

-
Redis DB는 메모리 기반 DB여서 속도는 빠르지만, 컴퓨터를 껐다 키면 데이터는 사라진다.
-
Redis에는 토큰에 대한 결과까지 key-value 형태로 함께 저장한다.
-
모든 검색 결과를 전부 저장하는 것은 아니고, 자주 검색되는 것을 저장하는데, 이를 검색 로그 캐싱이라고 한다. 👇🏻
검색 로그 캐싱
사용자가 늘어나면 검색 로그(데이터)를 통해 알아낼 수 있는 자주 검색되는 검색어는
굳이 디스크에서 뽑아올 필요가 없으므로 메모리 기반 DB에 저장해놓고 (검색 로그 캐싱: 임시 저장) 더 빠르게 검색할 수 있게 하는 방식이다.
- 자주 검색되는 것은 Redis에 저장해서 빠르게 조회하고, 외의 것들은 ES에서 검색한다.
- 한번 이상 검색된 것들을 Redis에 보관해서 다음 검색부터는 빠르게 결과를 조회할 수 있게 할 수 있다.
데이터를 저장하는 위치에 따른 DB 구분
1. 디스크 기반 DB
- 영구적으로 저장된다.
- 메모리 기반 DB에 비해서 속도가 느리다.
- Elastic Search
2. 메모리 기반 DB
- 램에 저장한다. (영구 저장❌)
- 속도가 훨씬 빠르다.
- Redis, Memcached
