Transformer
Transformer는 Google에서 발표한 기존에 기계번역에 사용하던 RNN을 버리고, 내부에는 Attention으로만 구현한 모델이다.
RNN과 CNN을 사용하지 않고 대신, Positional Encoding을 사용하였고,
Encoder와 Decoder로 구조를 설계하고 Attention 과정을 여러 레이어에서 반복하였다.
참고로, GPT는 Transformer의 Decoder 아키텍쳐를 활용하였고, BERT는 Transformer의 Encoder 아키텍쳐를 활용하였다.
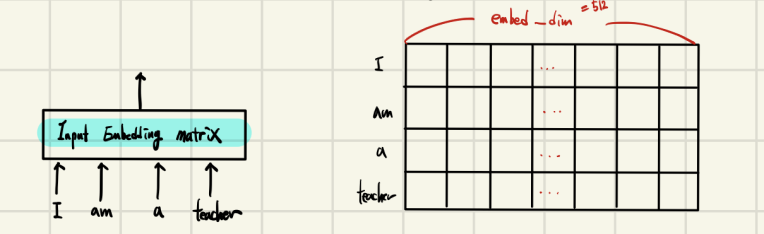
Conventional Embedding
전통적인 임베딩(Embedding)은 embedding matrix를 사용하고 이를 RNN에 이용한다.
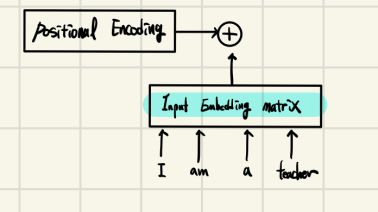
Transformer의 Embedding
하지만 Transformer의 RNN을 사용하지 않는다.
대신, Positional Encoding을 이용하여 위치정보를 포함하고 있는 임베딩(Embedding)을 사용한다.
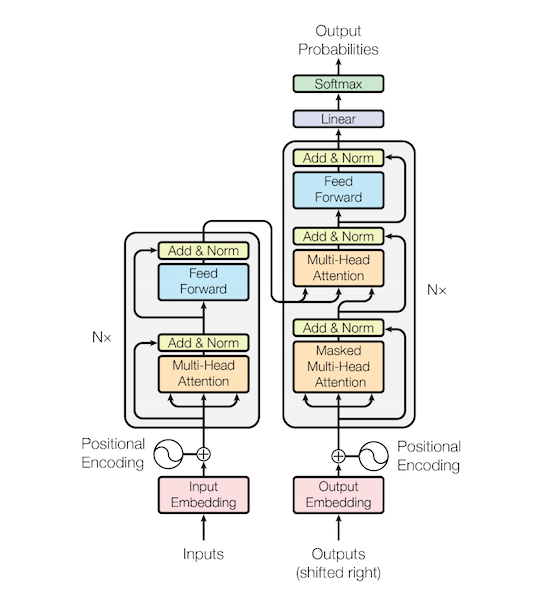
Transformer의 인코더(Encoder)와 디코더(Decoder)
임베딩(Embedding)이 끝난 후에 어텐션(Attention)을 진행, 성능 향상을 위해 Residual Learning을 사용한다. 이후, 어텐션(Attention)과 정규화(Normalization) 과정을 반복한다.
각 레이어는 서로 다른 Parameter를 가진다.
1.Transformer의 인코더(Encoder)
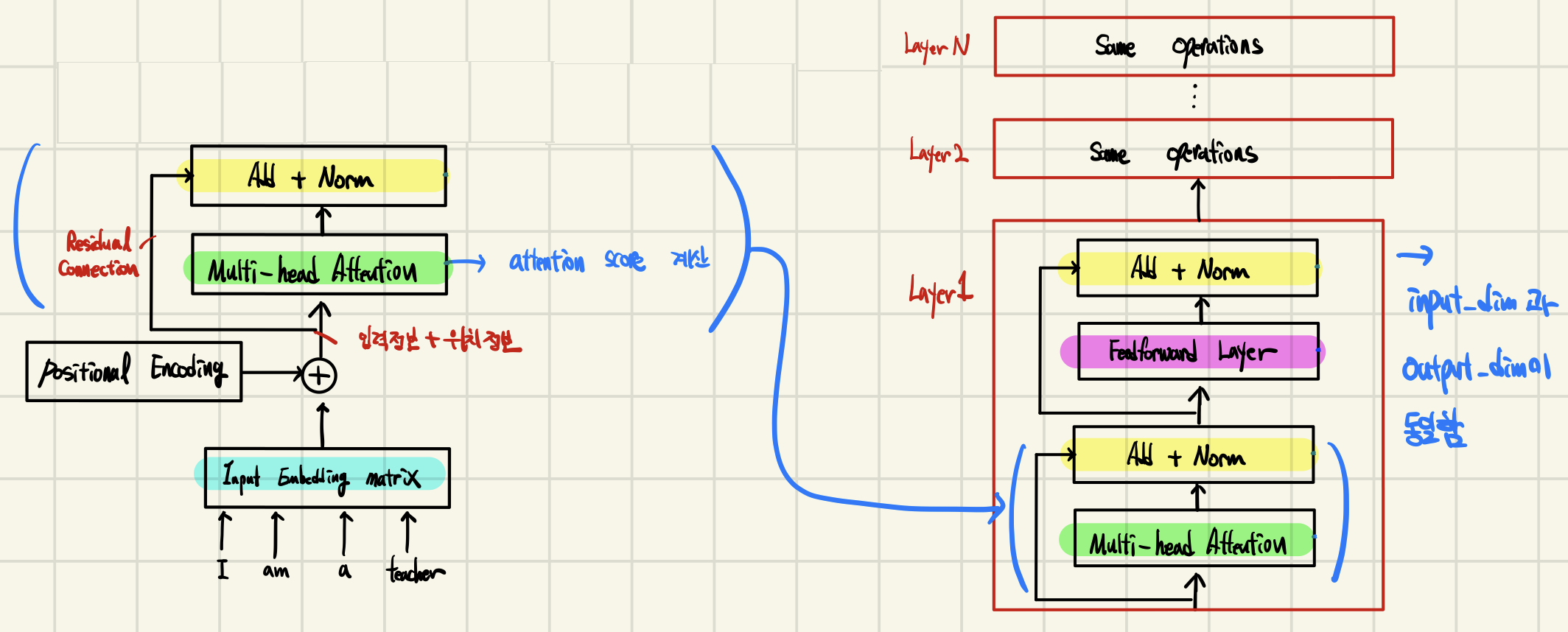
2.Transformer의 인코더(Encoder)와 디코더(Decoder)
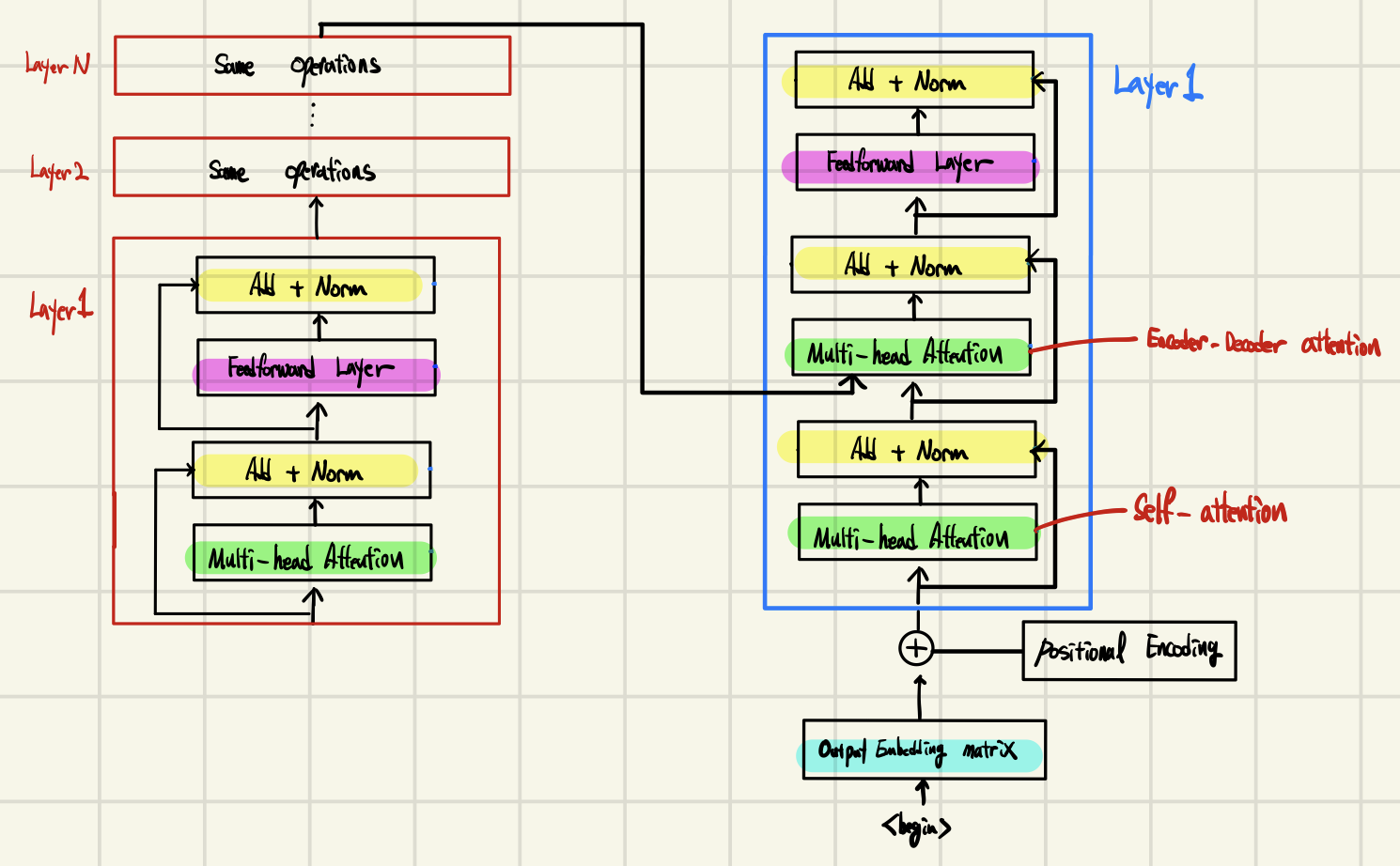
Transformer에서는 마지막 인코더 레이어의 출력이 모든 디코더 레이어의 입력에 들어간다.
아래는 n_layers = 4일때의 예시이다.
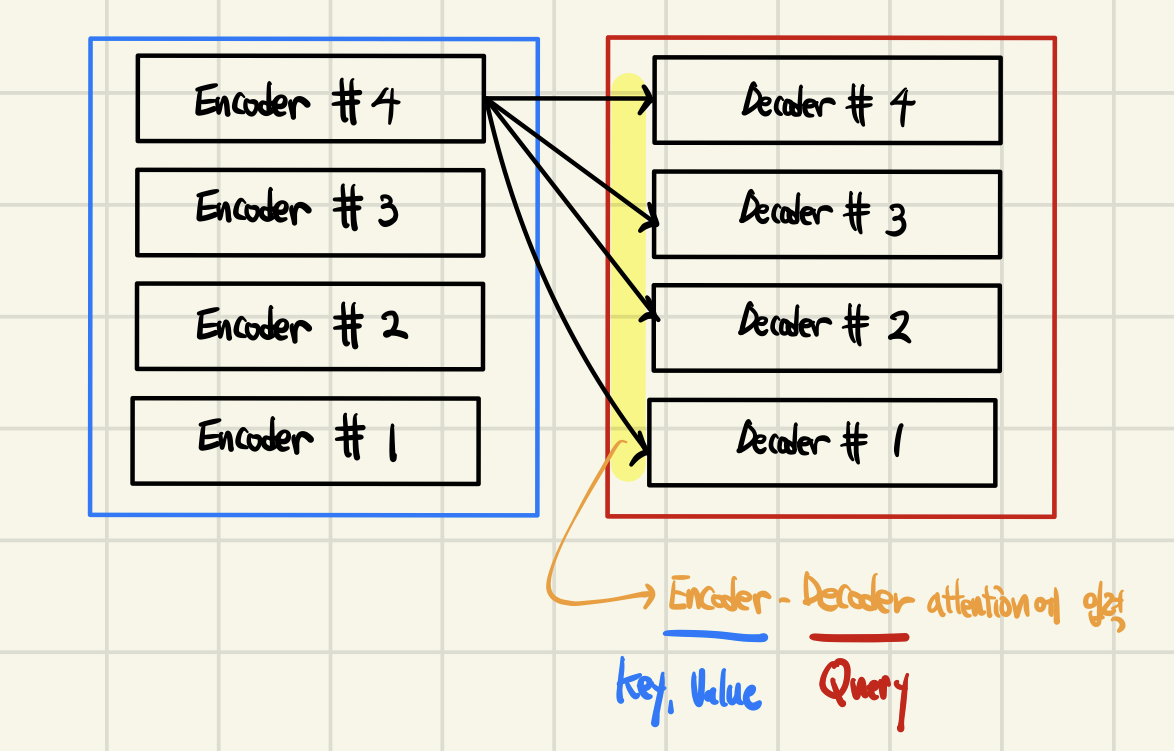
RNN을 사용하지 않는 대신에 인코더와 디코더를 다수 사용한다는 점이 특징이다.
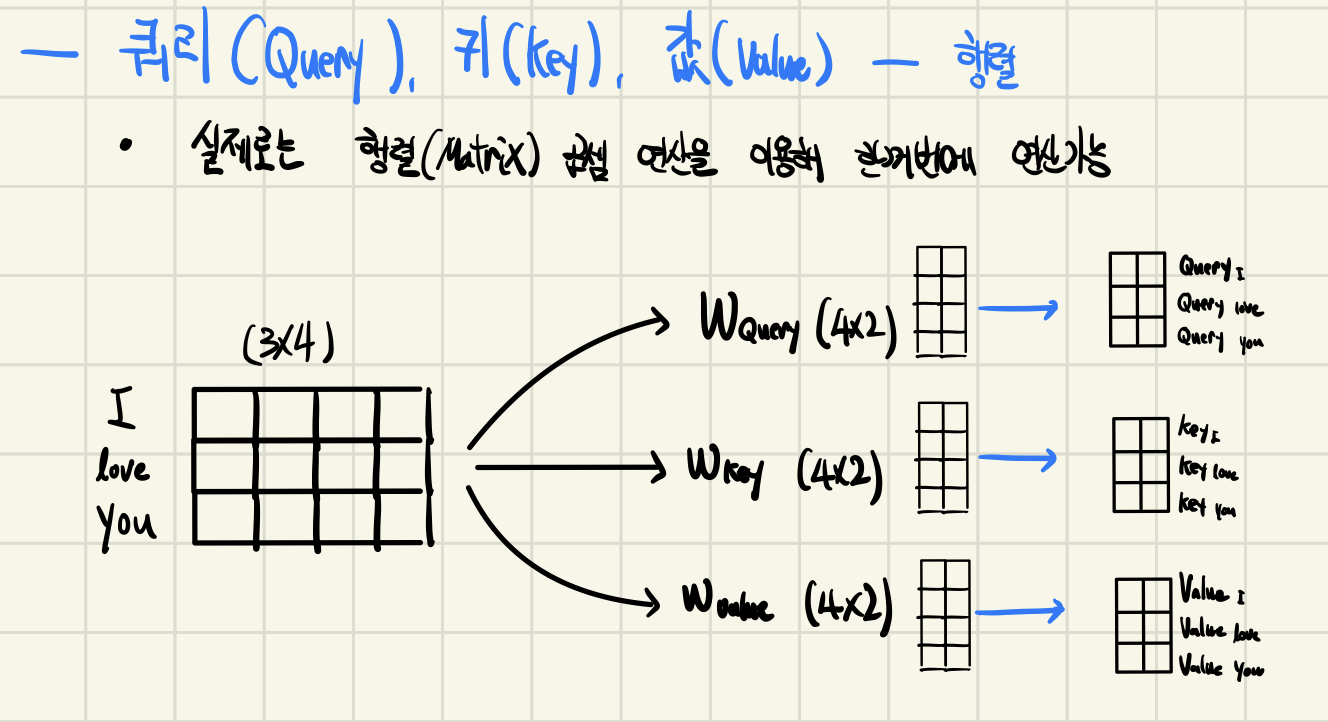
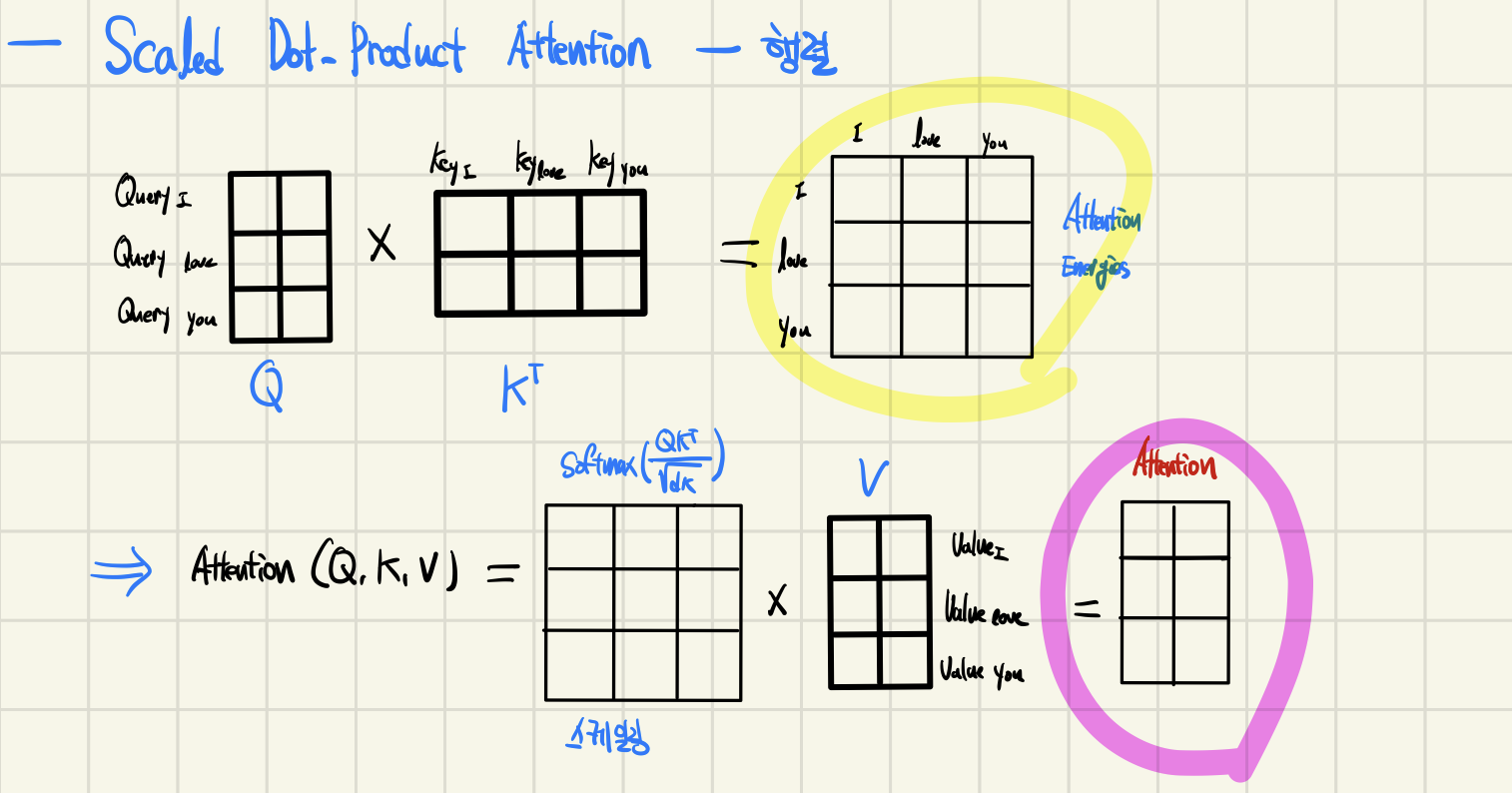
Query, Key, Value
- 어텐션(Attention)을 위해 Query, Key, Value가 필요하다.
- 각 단어의 임베딩(embedding)을 이용하여 생성 할 수 있다.
- 임베딩 차원() → Query, Key, Value 차원 ()
-
한개의 단어
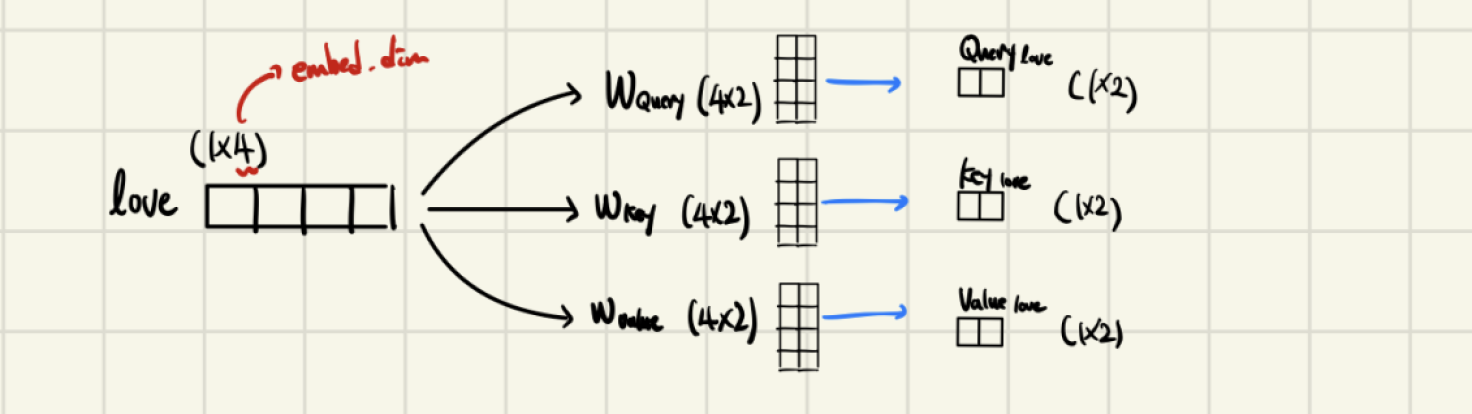
-
행렬 연산
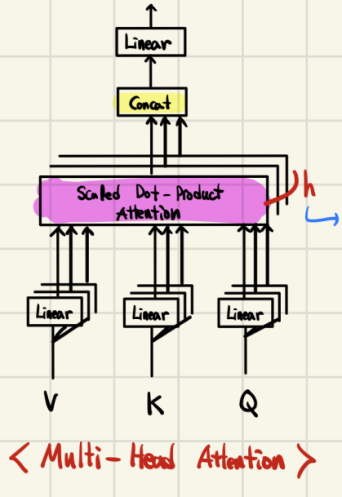
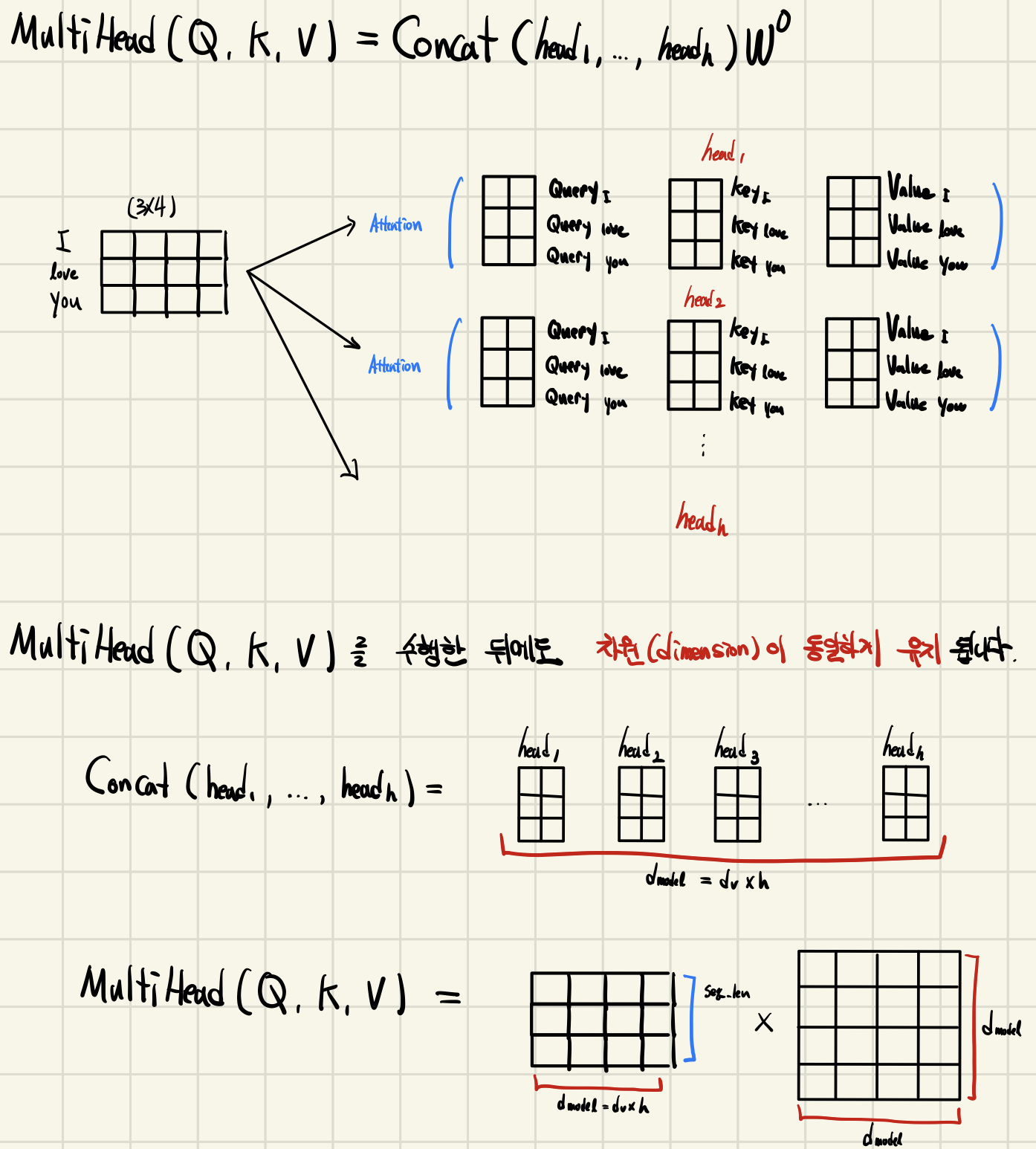
Multi-Head Attention
Transformer의 인코더와 디코더는 Multi-Head Attention 레이어를 사용한다
-
attention을 위한 세가지 요소
Query - Decoder의 Multi-Head attention
Key, Value - Encoder의 출력 -
입력값과 출력값의 demension이 같도록 만든다.
( Query에 대한 에너지 값, : key dimension)- : 개의 서로 다른 concept을 계산
(; head의 개수, output matrix)
softmax입력을 (Scaling factor)로 나누어 주는 이유는 Gradient Vanishing을 회피하기 위해서이다.
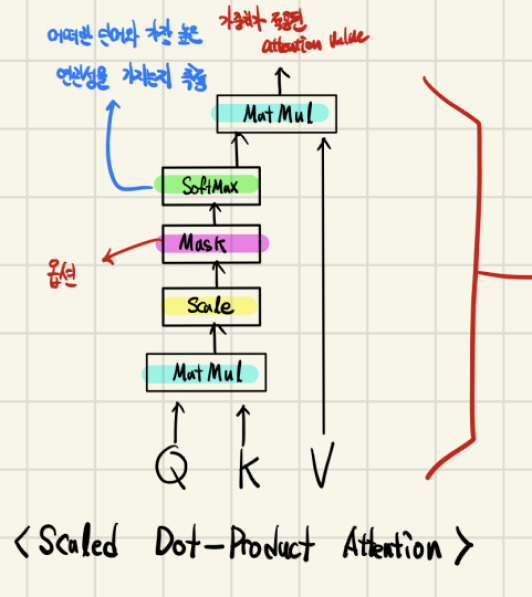
1.Scaled Dot-Product Attention
-
한개의 단어
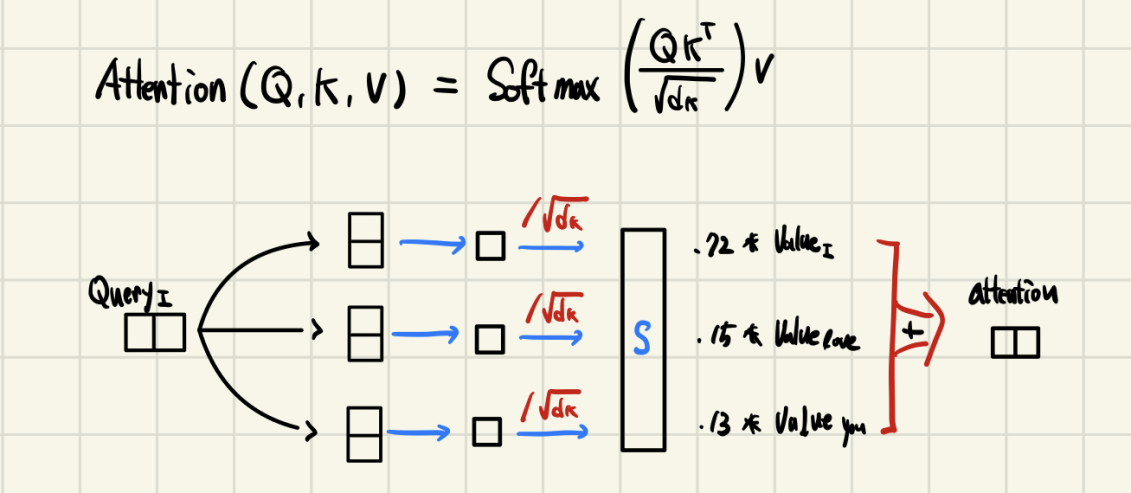
-
행렬 연산
2.Multi-Head Attention
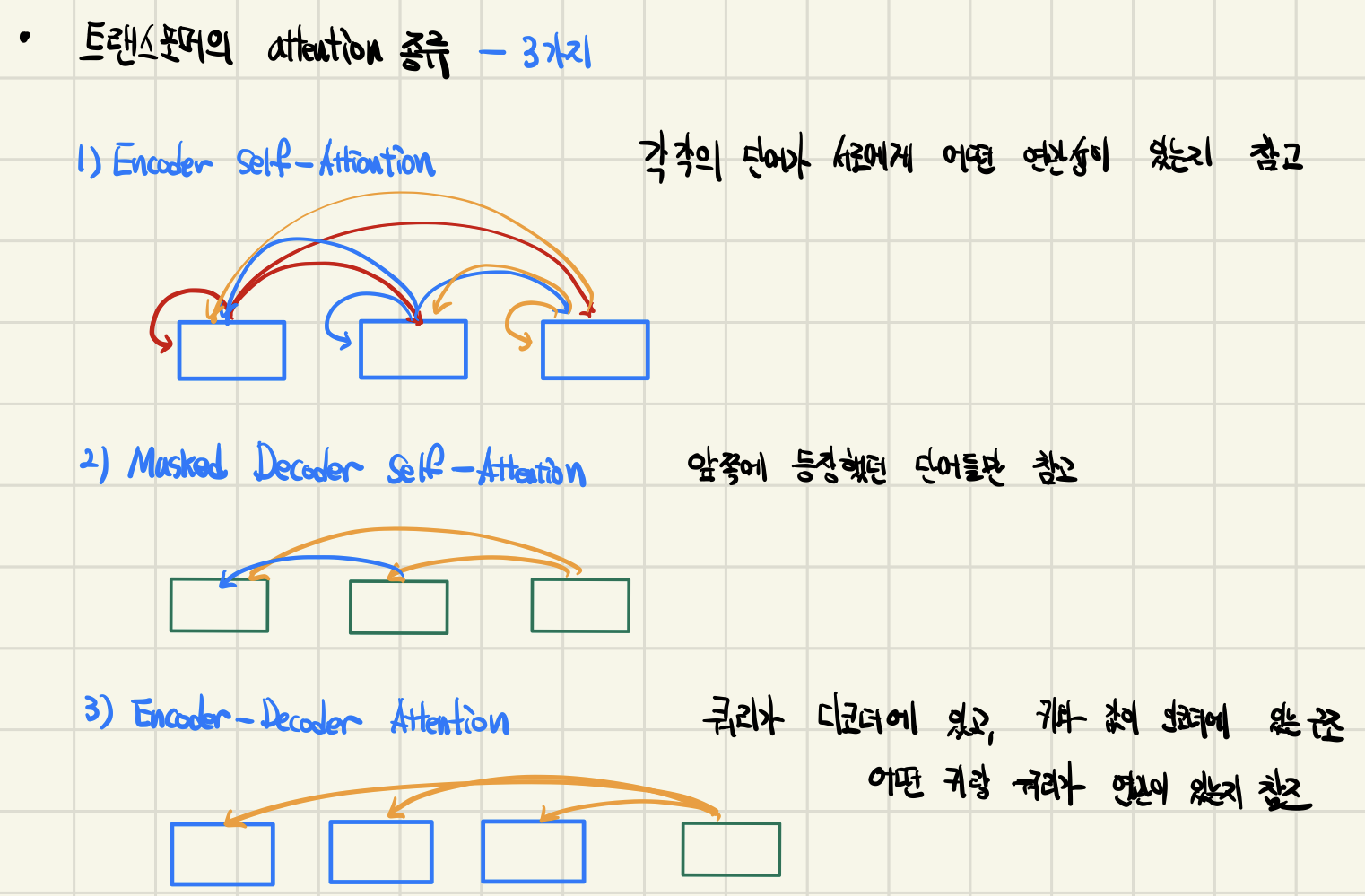
Transformer의 Attention 종류