Perceptron
1.Single Layer Perceptron(SLP)
로젠블럿(Rosenblatt)이 제안한 초기형태의 인공신경망
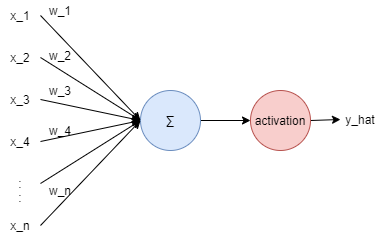
- : 입력값
- : 가중치
- : 예측값
들어오는 입력 에는 각각의 가중치(Weight) 가 존재하며, 가중치가 클 수록 해당 입력값이 중요하다는것을 의미함.
활성(Activation)함수는 모델의 비선형성을 높이기 위해 사용함.
어떤 입력 X에 선형변환 A, B를 적용하여도 결국, 이 선형변환은 또 다른 선형변환 C로 대응되므로 비선형함수인 활성함수를 적용하여야 함.
다만, 이 퍼셉트론으로는 XOR 문제를 해결할 수 없다는 문제점이 있다.
이 문제를 해결한 다층 퍼셉트론을 살펴보자.
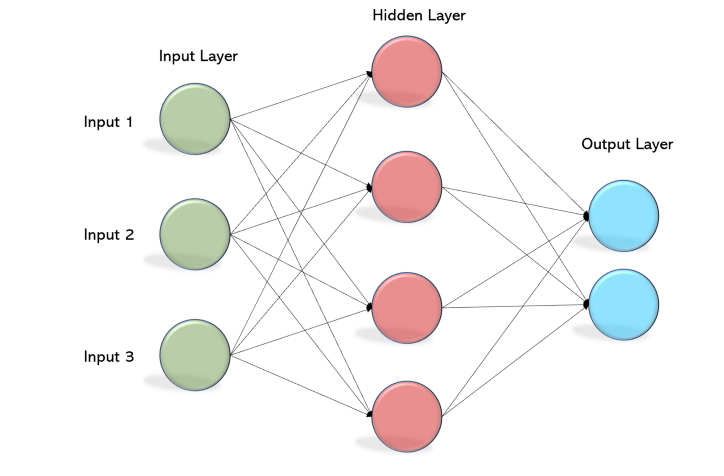
2.Multi Layer Perceptron(MLP)
다층 퍼셉트론은 단층 퍼셉트론의 층을 쌓아서 만들 수 있다.
차이점은 은닉층(Hidden Layer)의 유무이며, 은닉층이 2개 이상인 신경망을 심층 신경망(Deep Neural Network; DNN)이라고 부른다.
CNNs
Conventional CNN
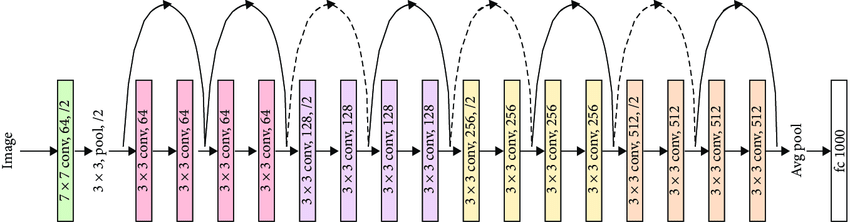
1.VGGNet
VGGNet은 널리 사용되는 CNN 모델 중의 하나로 옥스퍼드 대학교 VGG(Visual Geometry Group) 연구소의 Simonyan과 Zisserman이 제안하였다.
VGGNet의 컨셉은 작은 커널을 사용하여 깊은 네트워크를 만드는 것이다.
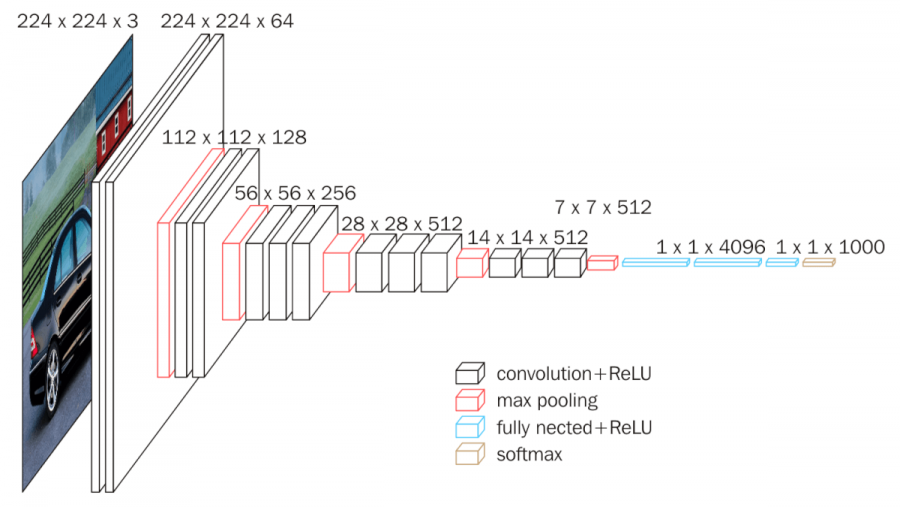
네트워크의 깊이를 깊게 만드는 것이 성능에 어떤 영향을 미치는지 확인하고자 많은 개수의 필터를 사용하되 3×3 필터만 사용하였다. 큰 커널을 한번 적용하는 연산보다 3×3 커널을 여러 번 연산하는 것이 비선형 연산을 더 많이 수행하므로 변별력 측면에서 더 우월하다는것을 확인하였다.
2.GoogLeNet(Inception)
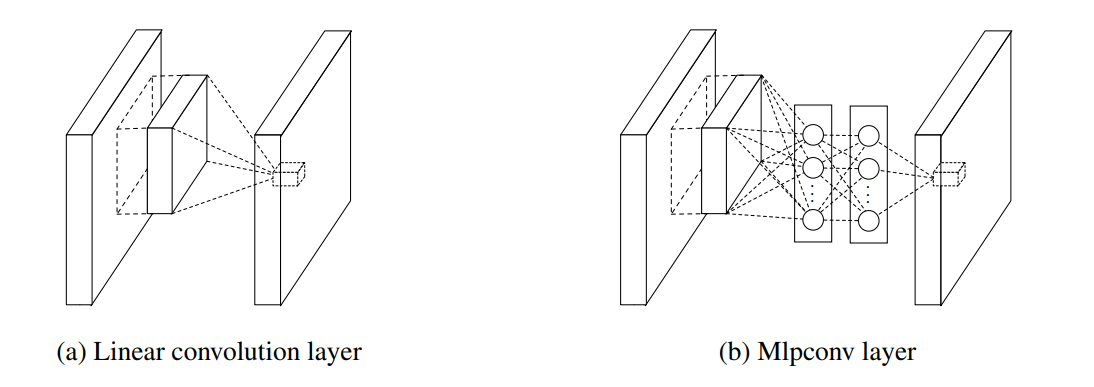
GoogLeNet은 Lin이 제안한 네트워크 속의 네트워크(NIN)의 영향을 받았다.
기존의 컨볼루션 레이어은 단순히 컨볼루션 연산을 수행하지만, NIN는 MLP의 순전파를 계산한다. MLPconv 레이어는 컨볼루션 연산처럼 커널을 옮겨가면서 계산을 하여 컨볼루션 처럼 Feature Map을 계산한다. (b)의 두 층 사이에 있는 네트워크를 마이크로 네트워크라고 한다.
NIN에서는 Global average pooling이라는 아이디어를 제시하였다.
기존의 AlexNet이나, VGGNet는 네트워크 뒷부분에 분류 목적으로 완전 연결층을 두었다. 여기서 문제점은 이 완전 연결층의 매개변수가 전체 VGGNet의 매개변수의 85%를 차지한다는 것이다.
이는 과잉적합의 원인이 되기 때문에 NIN에서는 MLPconv가 필요한 만큼의 클래스 수만큼 특징맵을 생성하고 이를 Global average pooling를 이용하여 매개변수를 줄여 과잉 적합을 줄인다.
GoogLeNet은 이 NIN를 확장한 신경망이다. 다만, MLPconv대신 Inception 모듈을 사용한다. GoogLeNet에서 이 Inception 모듈을 9개 결합하였고, 과적합을 정규화하고 방지하기 위해 보조 분류기를 추가하였다.
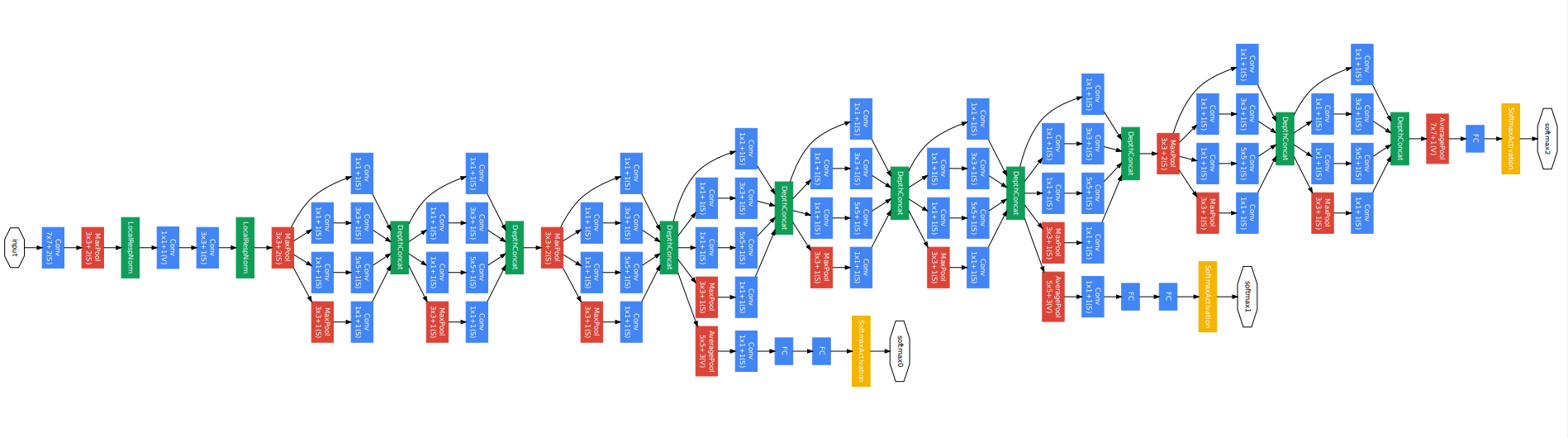
Inception 모듈은 마이크로 네트워크가 컨볼루션 연산만으로 구성되며, 네 종류의 컨볼루션을 수행하고 결과를 합하는 방식으로 이루어진다.
(아래의 사진은 아래쪽이 입력이고 위쪽이 출력이다.)
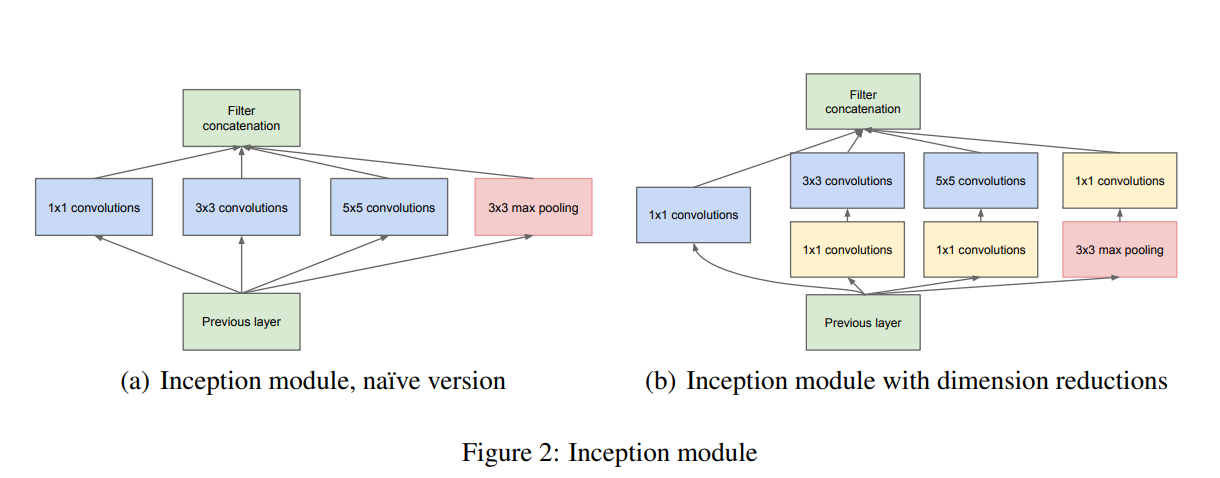
(b)의 사진은 매개변수를 더 줄이기 위한 트릭을 적용한 버전이다.
이 Inception 모듈은 28x28 192장의 Feature Map을 입력으로 받아 28x28의 Feature Map을 1x1 컨볼루션은 64장, 3x3은 128장, 5x5은 32장, 3x3 Maxpooling은 32장을 생성하여 총 256장을 출력한다. 즉, 28x28x256 텐서를 출력한다.
3.ResNet
ResNet은 Kaiming He이 제안하였다. 기존 신경망의 문제점은 층수가 늘어나면 성능이 향상되다가 포화상태에 이르고, 어느 지점을 지나면 성능이 급격하게 저하하는 현상이 나타난다.
ResNet은 네트워크에 shortcut들을 추가하여 Vanishing/Exploding Gradients 문제를 해결하였다.
ResNet에서는 Residual Block을 이용하여 이를 구현하였고 그 구조는 아래와 같다.
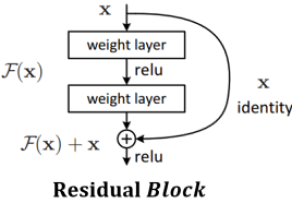
- : 활성함수
여기서 역전파는 아래와 같다.
- : 목적함수
- , : Residual Block 번호 (은 보다 더 깊은곳)
여기서 역전파 되는 항이 와 두개의 항으로 구성되어 있다.
그런데, 이 -1이 될 가능성이 없기 때문에 Gradient가 0이 되지 않는다.
그래서 Vanishing Gradient 문제가 발생하지 않는다.
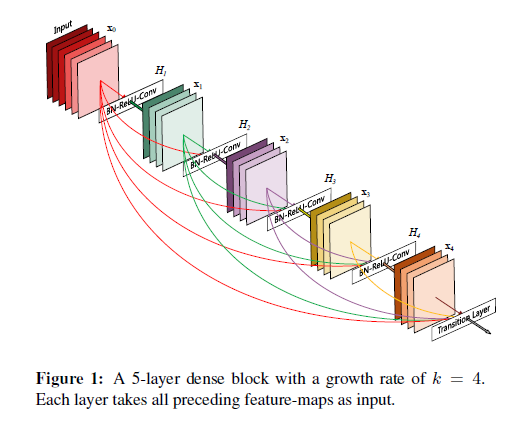
4.DenseNet
DenseNet은 Gao Huang이 제안하였다. 정보의 흐름을 최대로 보장하기 위해서, short connection방법을 바탕으로 모든 layer들을 연결한다.
즉, DenseNet은 번의 direct connection이 이루어진다.
이러한 Dense Connectivity Pattern으로 인해 DenseNet이라 부른다.
Object Detection
1.R-CNN(Region-based CNN)
R-CNN은 아래의 사진과 같은 구조로 객체의 위치를 탐색하고 객체의 class를 식별한다.
- 객체를 포함하고 있을것 같은 영역을 찾기 위해 영역 제안(region proposal) 알고리즘 적용
- 추천된 각 영역을 224*224 정규화 한 후 feature를 추출(변형 AlexNet 모델을 사용)
- 디스크에 캐싱
- multi-class SVM을 적용하여 학습을 진행
추가적으로 bounding box를 미세 조정하는 회귀모델도 학습을 진행
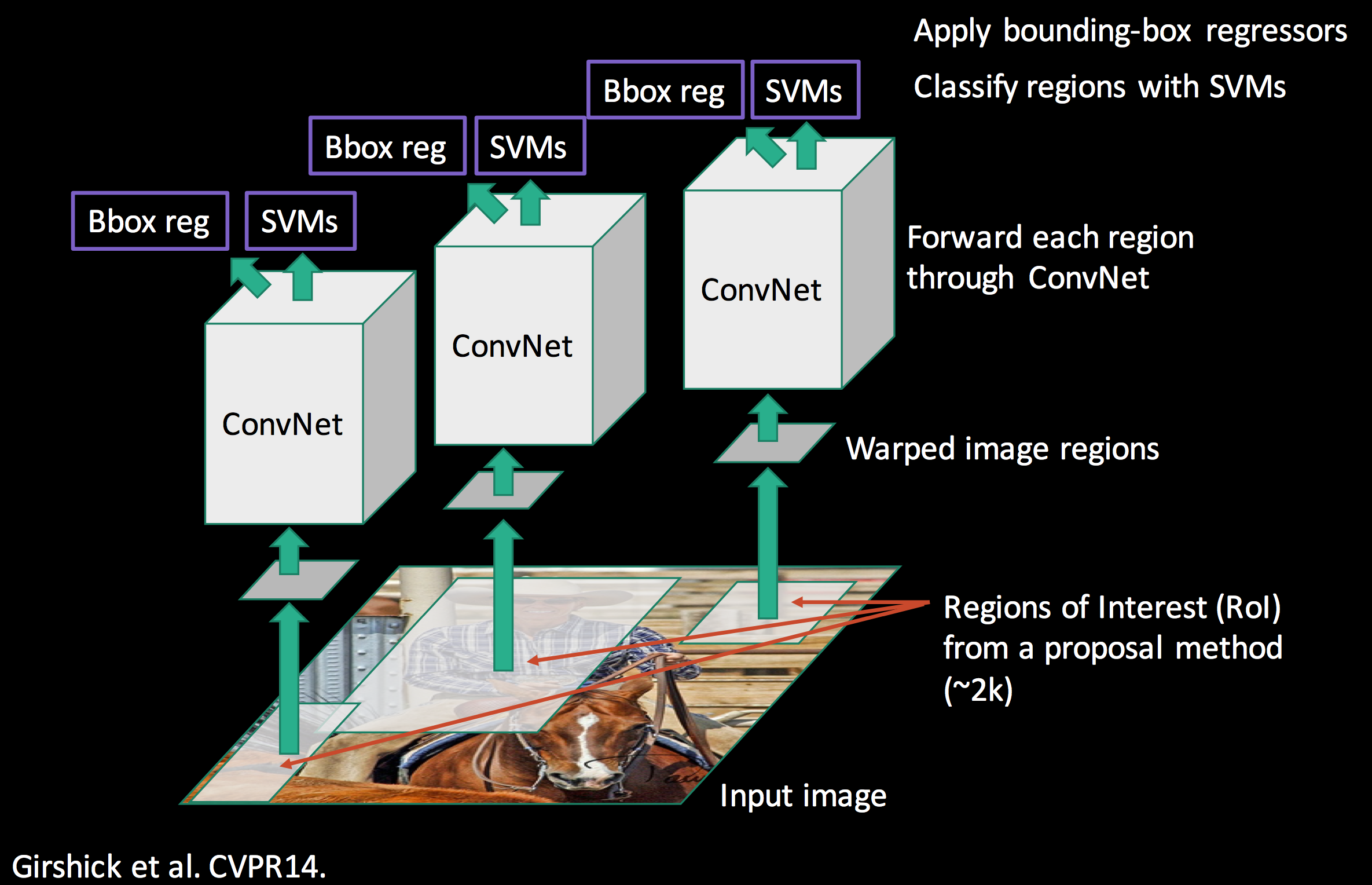
초창기 객체 탐지 알고리즘으로 관심을 얻었지만 아래와 같은 단점이 있다.
- 추천된 약 2,000개의 영역을 순차적으로 CNN모델에 적용해야하기 때문에 계산량이 많음
- CNN 정규화 과정을 거치기 때문에 클래스 예측 모델에서 성능저하 발생
- multi-class SVM과 Bbox regression 학습 알고리즘이 GPU 사용에 적합하지 않음
이러한 단점을 보완한 모델로 Fast R-CNN, Faster R-CNN 등이 있다.
2.YOLO(You Only Look Once)
YOLO 모델은 실시간으로 객체를 탐지하고 인식하는 방법이다.
- 영상을 448*448 크기로 조정
- 영상을 S*S 그리드로 나누기
- 각 그리드 셀에서 B개의 객체를 검출하고 class를 결정
(검출된 객체는 Bbox로 표시, 객체의 class는 확률값으로 제공)

- Bbox
Bbox에는 중심 위치와 폭, 높이로 표현한다.
객체에 대한 Bbox에는 신뢰도()가 부여됨
(, 는 전체 영상의 폭과 높이의 비로 표현)
객체의 class 수가 총 라면, 클래스 정보는 개의 확률값으로 표현하고
YOLO는 학습시 영상 하나에 대해 크기의 데이터를 출력한다.
YOLO는 R-CNN의 방법(물체 영역을 찾은 다음 그 영역의 객체를 인식)과는 다르게 물체 영역과 인식을 동시에 하는 회귀 문제로 해결한다.
3.SSD(Single Shot MultiBox Detector)
SSD는 YOLO보다 정확도와 처리시간이 개선된 방법으로 실시간으로 객체를 식별하고 인식하는 방법이다.
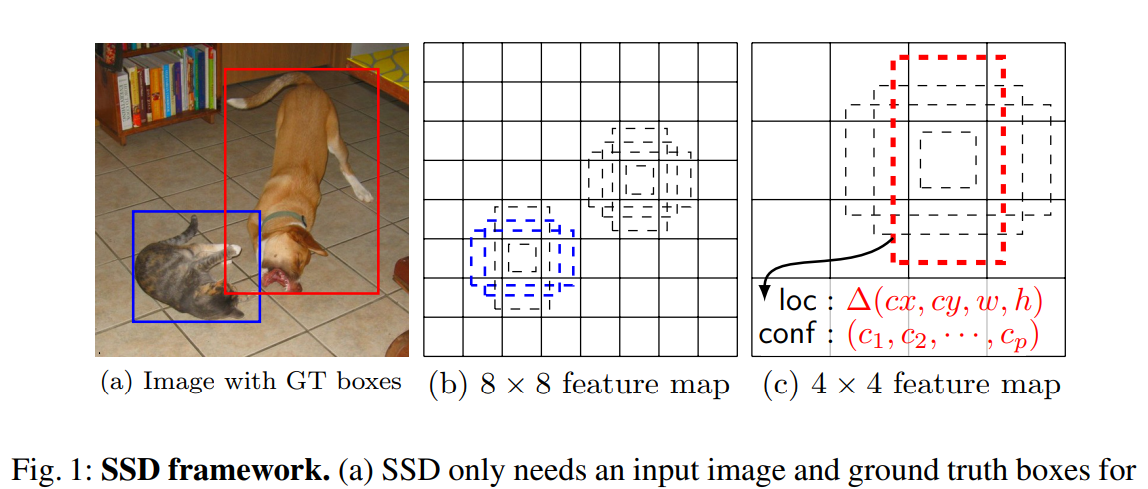
(a) : label된 Groud Truth Bbox
(b) : Feature map
(c) : Feature map
각 Feature map의 셀에 대해 aspect ratio가 다른 K개의 base Bbox를 정하고, 해당 부분에서의 객체의 유무를 확인한다.
Bbox의 정보
1. base Bbox의 중심 위치에 대한 offset과 너비와 높이 : (cx, cy, h, w)
2. class에 대한 신뢰도 :
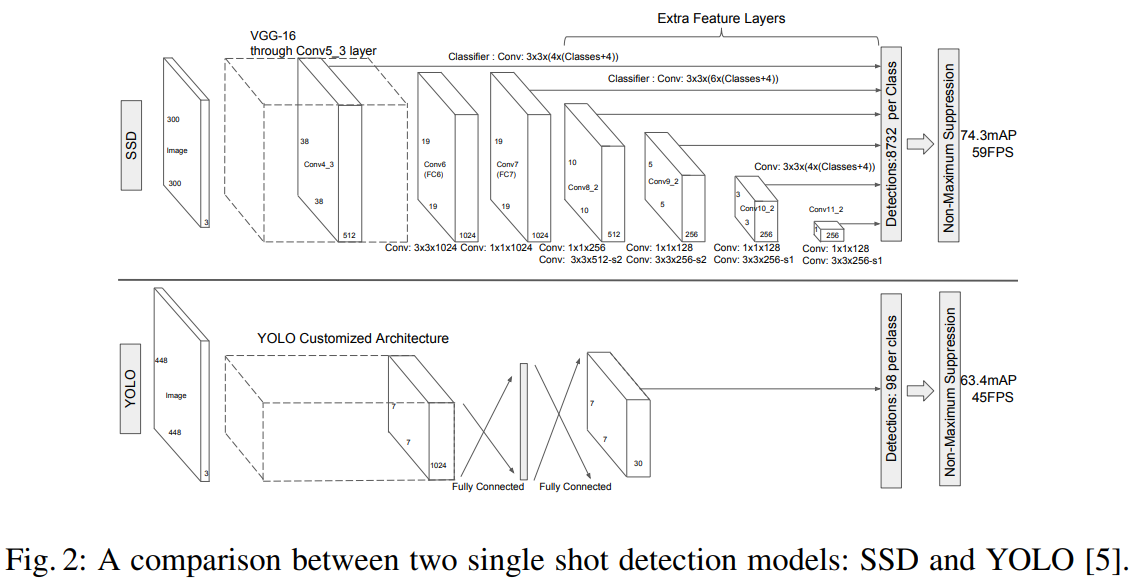
SSD모델은 위의 사진과 같이 기본망과 추가 feature layer로 구성된다.
Sementic Segmentation
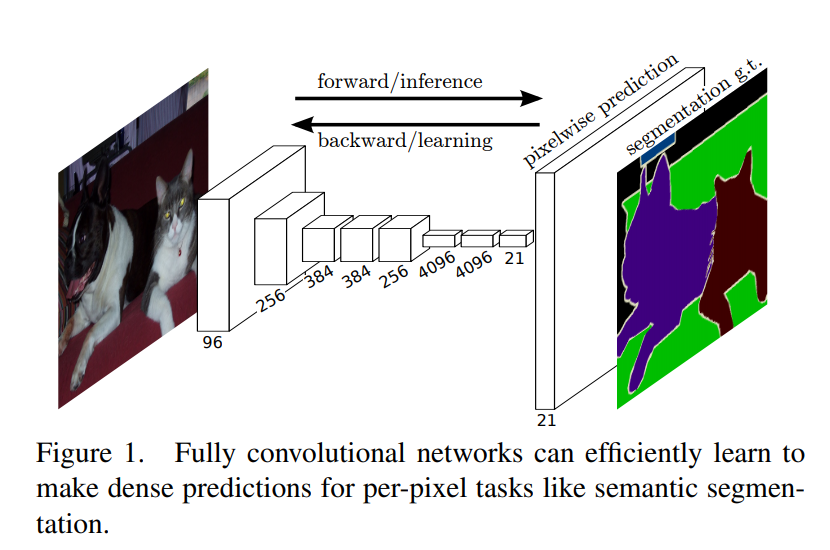
1.FCN(Fully convolutional Networks)
FCN는 Jonathan Long, Evan Shelhamer, Trevor Darrell이 제안하였다.
이 네트워크는 Sementic Segmentation 문제를 해결하기 위해 수정한 CNN이다.
FCN은 기존 CNN의 완전 연결층을 모두 1x1 컨볼루션 레이어로 변경하였고, 마지막 레이어에서 디컨볼루션 레이어를 추가하여 축소된 이미지를 원본 이미지 크기까지 확대한다.
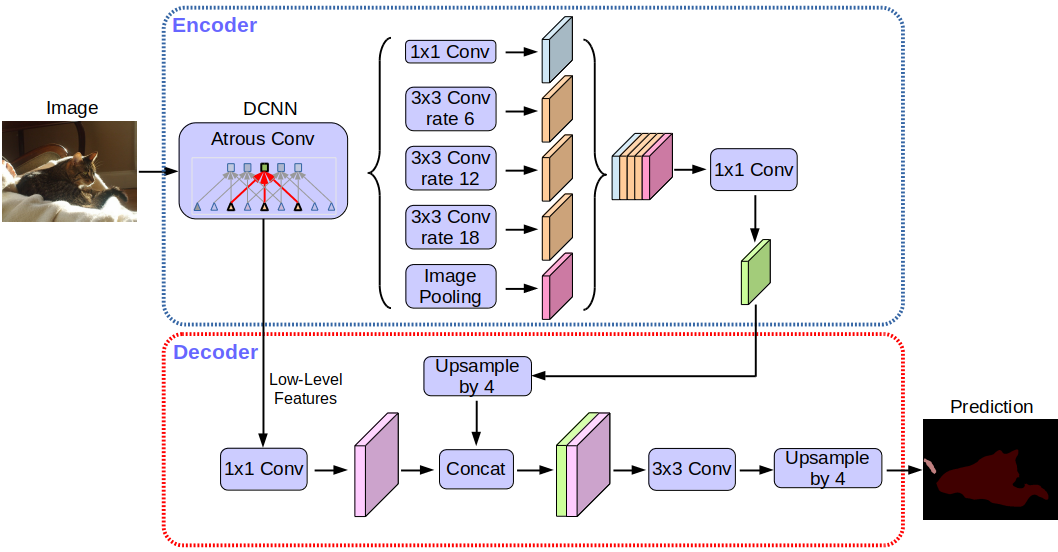
2.DeepLab
DeepLab은 Dilated Convolution(Atrous Convolution)을 이용한 Segmentation 모델이다.
Atrous Convolution의 장점은 파라미터의 개수를 늘리지 않고 recepticle field를 키울 수 있다.
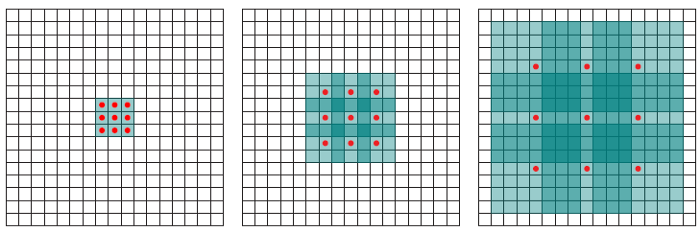
가운데(dilation=2) 그림을 보면, recepticle field가 인 것을 볼 수 있다. 이것을 normal convolution으로 구현을 한다면 파라미터의 수가 49개이지만, dilated convolution을 사용한다면 빨간점에 해당하는 부분만 연산한다. 즉, 필터를 적용하는 것과 같게되며 연산이 줄어든다.
DeepLab V3는 ImageNet으로 pre-trained된 ResNet을 Feature Extracter로 사용한다.
또한, 이전 버전에서 소개되었던 Atrous Spatial Pyramid Pooling (ASPP)을 사용한다.
3.U-Net
U-Net은 Olaf Ronneberger, PhilippFischer, Thomas Brox에 의해 제안되었으며, 이 네트워크는 biomedical 분야에서 주로 사용된다. 이 네트워크 이름은 아키텍쳐 구조가 U 모양이라 붙여진 이름이다.
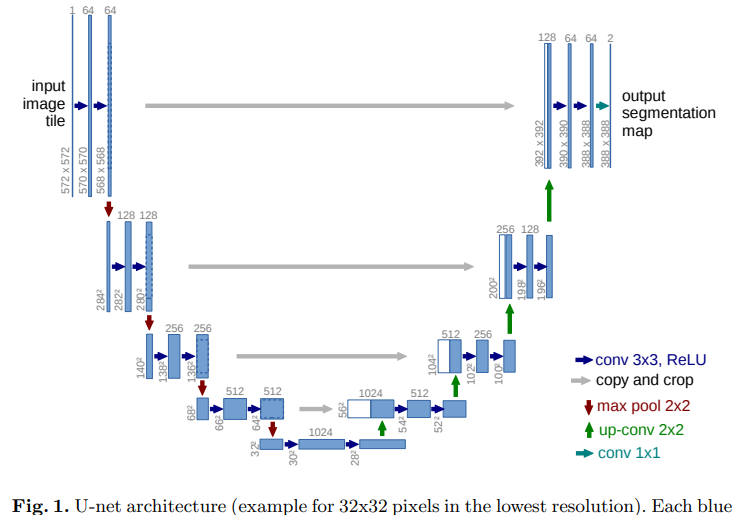
U-Net의 메인 아이디어
- Contracting Path(Encoding): 이미지의 context 캡처
- Expanding Path(Decoding): feature map을 upsampling 하고 캡처한 context와 결합
→ 더욱 정확한 localization 기대 가능- Data Augmentation으로 Random Elastic Deformation 사용
U-Net의 특징
- feature map을 upsampling 하고 캡처한 context와 결합을 통해 해상도가 높게 유지됨
- overlap-tile 전략
아래와 같이 feature map을 upsampling 하고 캡처한 context와 concatenation을 하면 해상도가 높게 유지된다.
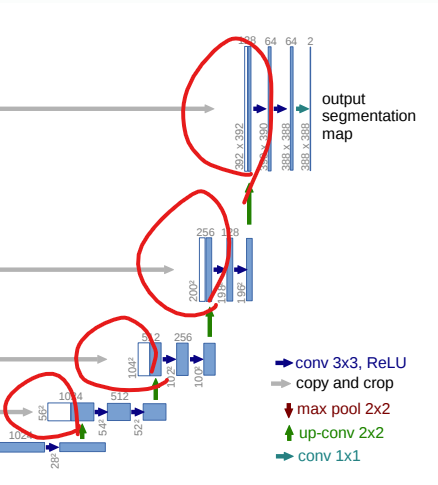
overlap-tile 전략은 기존 Segmentation 방법이 Sliding window를 사용하였기 때문에 너무 느리고 정확도가 떨어지기 때문에 제안된 방법이다.

이 전략은 파란색 단위(tile)로 선택(파란색)해서 처리하고 다음 타일을 이전 타일의 영역과 곂쳐 선택(빨간색)한다음 처리한다. 또, border 부분에는 0으로 채워넣는 Padding 방식이 아니고 주변 값들로 채워넣는 Mirroring 방법으로 픽셀 값을 채워넣는다.
4.SegNet
SegNet은 Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla가 제안하였고, 이 네트워크는 자율주행과 분야의 Sementic Segmentation 문제를 해결하기위해 설계되었다.
SegNet 모델은 크게 Encoder와 Decoder로 이루어져 있다.
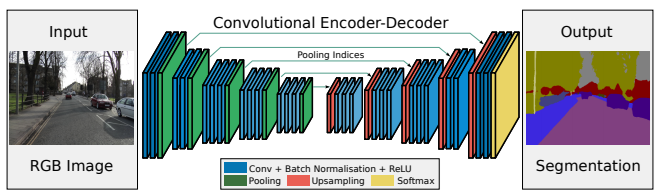
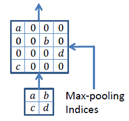
Encoder는 VGG16에서 완전 연결 레이어를 제외한 13개의 컨볼루션 레이어를 그대로 사용하였고, Encoder의 2x2 Max-pooling에서 해당되는 Max-pooling 인덱스를 저장한다.
Decoder는 Upsampling과 컨볼루션을 수행한다. Decoder의 Upsampling에서는 Encoder에서 저장한 Max-pooling 인덱스를 이용한다.
Recurrent Neural Network(RNN)
1.RNN
RNN은 시계열 데이터를 다루는데 특화된 데이터에 특화된 모델이다.
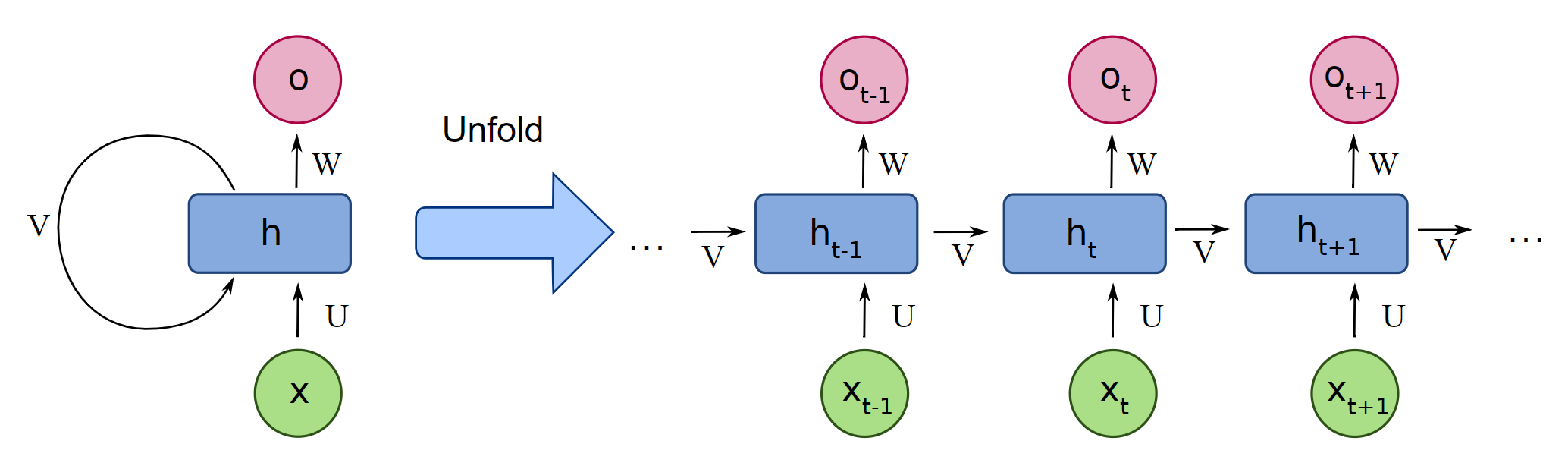
그림에서 보여주듯이 이전 시간(t-1)의 은닉층 출력이 다음 시간(t)의 입력으로 들어가는 것을 볼 수 있다.
이 구조는 현재 시간(t)가 다음 시간(t+1)에 영향을 미치고, 이것이 다음 시간(t+2)에 영향을 미치는 괴정이 끊임없이 반복되어 순환하는 구조이다.
하지만 RNN을 포함한 대부분의 신경망 구조는 학습이 계속 진행됨에 따라, 이전 입력 정보의 학습에 미치는 영향이 점점 감소하다 사라지는 치명적인 문제 vanishing gradient problem을 가지고 있다. 이를 해결한 모델인 LSTM을 살펴보자.
2.LSTM
LSTM는 Alex Graves가 제안한 모델이다.
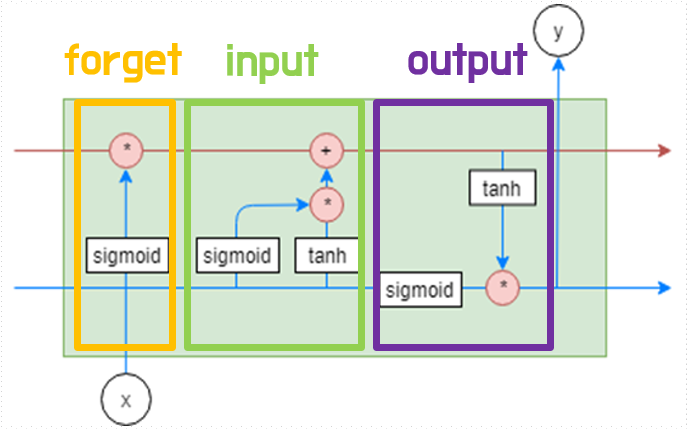
RNN의 hidden layer를 input, output, forget 3개의 게이트로 구성하는 메모리 블록으로 대체하여 Long Short-Term Memory구조를 제시하였다.
이를 통해 RNN의 Vanishing Gradient 문제를 해결하였고, 이 문제 때문에 나온 현상인 장기 의존성 문제를 해결하였다. 이 덕분에 LSTM은 먼 과거의 정보도 다음 시점의 은닉 층으로 전달할 수 있다.
3.Gated Recurrent Unit(GRU)
GRU Kyunghyun Cho이 제안한 LSTM의 장기기억능력은 보존하면서 연산은 적은 모델이다.

LSTM에서는 메모리 블록이 3개의 게이트로 구성되었지만, GRU에서는 reset, update 2개의 게이트만 있다.
LSTM과 구조적으로는 비슷하지만 output 게이트가 없다.
모델별 매개변수 개수
GRU : 개
LSTM : 개
RNN : 개
(셀의 입력 : N차원, 출력 : M차원)
