
개요
데이터베이스(DB)는 서비스 개발에 있어 데이터를 저장, 관리하는 중요한 역할을 합니다.
이러한 DB는 다양한 기준으로 구분되며 업무 요구사항에 맞는 DB를 잘 선택해야 합니다.
오늘은 새로 시작하는 프로젝트에서 사용하게 된 MongoDB와 MySQL을 비교해보려고 합니다.
각 DB의 간단한 설명
MySQL 이란?
MySQL은 오픈소스 관계형 데이터베이스 관리 시스템입니다. 다른 관계형 데이터베이스와 마찬가지로 MySQL은 행과 열로 구성된 테이블에 데이터를 저장합니다. 사용자는 더 일반적으로 SQL이라고 하는 구조화된 쿼리 언어를 사용하여 데이터를 정의, 조작, 제어, 쿼리할 수 있습니다. MySQL은 오픈소스이므로 25년 넘게 사용자와 긴밀히 협력하여 개발한 다양한 기능이 포함되어 있습니다.
- 데이터베이스 타입 : 관계형 데이터베이스(SQL 데이터베이스)
- 데이터 저장 형식 : 행, 열로 구성된 테이블
MongoDB 란?
MongoDB는 오픈소스 비관계형 데이터베이스 관리 시스템입니다. 테이블과 행 대신 유연한 문서를 활용해 다양한 데이터 형식을 처리하고 저장합니다. 사용자가 다변량 데이터 유형을 손쉽게 저장하고 쿼리할 수 있는 탄력적인 데이터 저장 모델을 제공합니다. 이는 개발자의 데이터베이스 관리를 간소화할 뿐 아니라, 뛰어난 확장성을 갖춘 크로스 플랫폼 애플리케이션 및 서비스 환경을 구축합니다.
- 데이터베이스 타입 : 비관계형 데이터베이스(NoSQL 데이터베이스)
- 데이터 저장 형식 : BSON(Binary JSON) 형식의 컬렉션
MySQL vs MongoDB
MySQL은 대표적인 관계형 데이터베이스이고
MongoDB는 대표적인 비관계형 데이터베이스이기에,
두 데이터베이스의 차이점은 이런 테이터베이스 타입에 의한 차이점이 많습니다.
주요용어 대응
| MySQL | MongoDB |
|---|---|
| Database | Database |
| Table | Collection |
| Row | Document |
| Column | Field |
차이점
1 . 데이터 저장 방식
DB 설명에도 작성했듯 MySQL은 데이터를 고정된 행과 열 기반의 테이블에 저장합니다.
미리 데이터 타입, 제약조건 등의 정적스키마를 정의하고 정의에 맞게 데이터를 저장하는 것입니다.
CREATE TABLE students (
id INT PRIMARY KEY,
age INT,
name VARCHAR(50)
);
INSERT INTO students (id, age, name) VALUES
(1, 20, 'Bobae'),
(2, 22, 'Momae'),
(3, 21, 'Jojae');| id | age | name |
|---|---|---|
| 1 | 20 | Bobae |
| 2 | 22 | Momae |
| 3 | 21 | Jojae |
위는 MySQL에서 '학생' 데이터를 저장한 예시입니다.
만약 요구사항이 변경되어 학생의 '성적' 정보를 저장해야 한다면 어떻게 해야할까요?
스키마를 변경하여 'grade'컬럼을 추가해야 할 것입니다.
이처럼 유연성이 부족하여 MySQL은 요구사항이 변경될 때마다 스키마 자체를 변경해주어야 합니다.
이미 대량의 데이터가 존재하는 테이블의 스키마를 변경하게 되면 서버에 부담이 갈 수도 있을 것입니다.
MongoDB는 데이터를 BSON 형식의 컬렉션에 저장합니다.
(BSON은 JSON 형식처럼 보이지만 디스크 사용량을 줄이기 위해 바이너리로 직렬화한 것.)
동적 스키마를 가지기 때문에 다양한 타입과 구조를 갖는 데이터를 저장할 수 있습니다.
{
"_id": 1,
"age": 20,
"grade": "A",
"name": "Bobae"
},
{
"_id": 2,
"age": 22,
"name": "Momae"
},
{
"_id": 3,
"age": 21,
"grade": "B",
"name": "Jojae"
"major": "Computer Science"
}
위와 같이 같은 "Students" 컬렉션이더라도 각 Document의 Field가 다양합니다.
MySQL에 비해 유연성이 좋아서 특정 Document에 새로운 Field를 추가하는 것 또한 가능합니다.
2 . 중복
MySQL은 관계형 데이터베이스이기 때문에 데이터의 중복을 최소화하는 방향으로 정규화를 진행합니다.
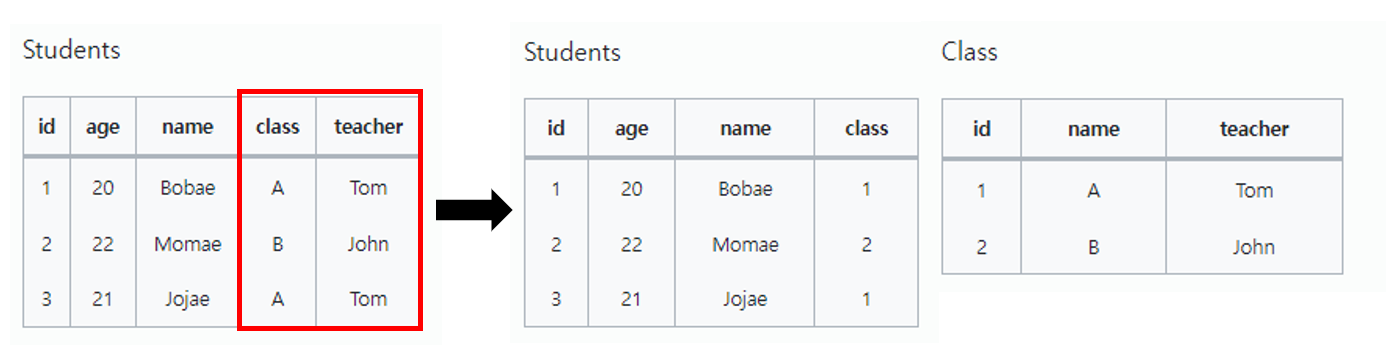
중복이 줄어들고 일관성을 유지하기 좋다는 장점은 있지만, 이로 인해 테이블 간의 Join이 증가하게 되고 cpu사용량, 응답시간이 늘어나게 됩니다.
복잡한 Join이 Read 성능을 하락시키는 것입니다.
MongoDB는 비관계형 데이터베이스로 중복을 허용합니다.
관계형 데이터베이스처럼 외래키를 사용하지 않고, 중첩 JSON을 사용해서 데이터를 그대로 나타냅니다.
(Document 생성 시 자동으로 생성되는 기본키, Object ID를 사용하기도 합니다.)
{
"_id": 1,
"age": 20,
"name": "Bobae",
"class": {
"name": "A",
"teacher": "Tom"
}
},
{
"_id": 2,
"age": 22,
"name": "Momae",
"class": {
"name": "B",
"teacher": "John"
}
},
{
"_id": 3,
"age": 21,
"name": "Jojae",
"class": {
"name": "A",
"teacher": "Tom"
}
}이때, 데이터 값이 변경되면 중복된 데이터들이 모두 최신 데이터를 유지할 수 있도록 업데이트, 관리해줘야 합니다. 일관성 측면에서 좀 더 신경써야한다는 것입니다.
3 . 확장성
데이터베이스에 Read, Write 요청이 증가하여 데이터베이스 서버의 확장이 필요한 경우가 생길 수 있습니다.
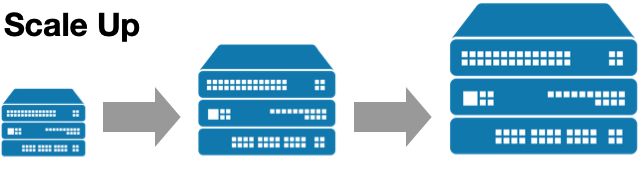
이때 MySQL은 Scale-Up으로 수직적 확장을 합니다.
데이터베이스 서버에 더 많은 리소스를 추가하여 성능을 향상시키는 것입니다.
이는 성능 향상에 따른 비용 증가의 폭이 큰 편이고, 하나의 서버에 부하가 집중되어 장애가 발생하면 그 영향이 크다는 단점이 있습니다.
다른 방법으로는 Replication 이 있습니다.
말 그대로 DB의 복제본을 만드는 것으로 복제본은 Read-Only(읽기전용)이 됩니다.
이는 Write 요청에 의한 부하를 해결할 수 없으며, 복제본이 원본보다 뒤쳐지는 문제가 발생할 수 있습니다.
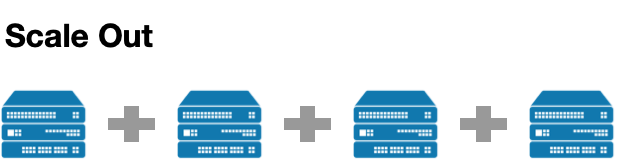
MongoDB는 Scale-Out으로 수평적 확장을 합니다.
서버를 추가하여 기존 서버의 부하를 분담하는 방법입니다.
데이터가 여러 서버로 분산되어 Read, Write 성능을 최적화할 수 있습니다.
4 . 성능
MySQL은 여러 테이블간의 고성능 조인을 수행하도록 설계되어 많은 수의 데이터를 READ할 때 좋은 성능을 냅니다.
다만 데이터를 한 행씩 삽입하기에 Write 성능은 떨어집니다.
MongoDB는 많은 수의 데이터를 삽입하고 업데이트할 때 좋은 성능을 냅니다.
정리
두 데이터베이스는 각각의 장단점이 있고, 필요에 따라 사용해야 합니다.
MySQL은 금융 시스템처럼 데이터의 일관성과 신뢰성이 중요한 경우 적합하고, MongoDB는 소셜 서비스처럼 비정형 데이터를 다룰 때, 또는 요구사항이 자주 바뀌거나 까다로울 때, 확장성이 중요한 경우 적합합니다.
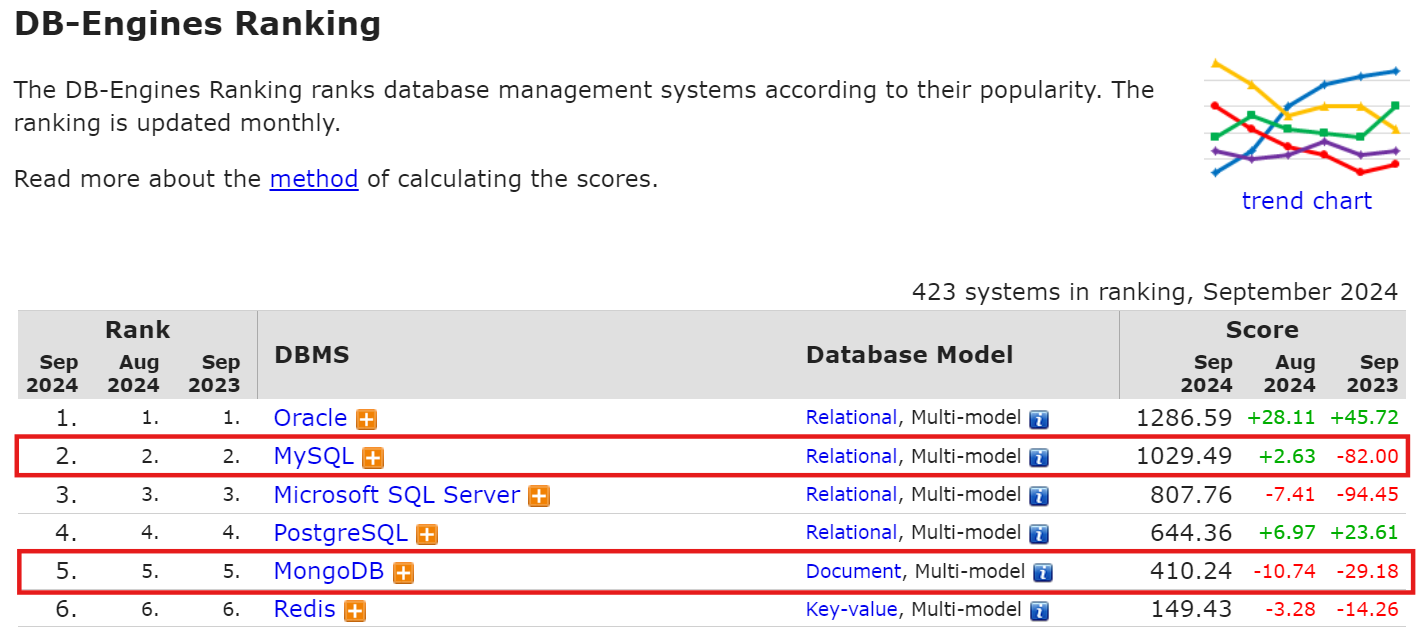
두 데이터베이스 모두 널리 사용되고 있는 만큼 꼭 사용해보았으면 좋겠습니다.
참고
https://aws.amazon.com/ko/compare/the-difference-between-mongodb-vs-mysql/
