
컬렉션 타입의 이해
tuple
- 리스트와 같이 복수개의 값을 갖는 컬렉션 타입
- 생성된 후 변경이 불가능
a = [1, 2, 3]
b = (1, 2, 3)
print(type(a))
print(type(b))
a[0] = 100
print(a)
b[0] = 100
print(b)
<class 'list'>
<class 'tuple'>
[100, 2, 3]
typle unpacking
- 튜플의 값을 차례대로 변수에 대입
a, b, c = 100, 200
print(a, b, c)
100 200- 연습문제 : a와 b의 값을 교환하시오
a = 5
b = 4
print(a, b)
# 일반적인 logic
temp = a
a = b
b = temp
# 파이썬은 튜플의 언팩킹으로 쉽게 교환 가능
a, b = b, a
print(a, b)
5 4
4 5dictionary
- 키와 값을 갖는 데이터 구조
- 키는 내부적으로 ahsh값으로 저장
- 순서를 따지지 않음. 즉, 인덱스가 없음
# dictionary 은 중괄호를 사용함
a = {'Korea' : 'Seoul',
'Canada': 'Ottawa',
'USA': 'Washington D.C' }
b = {0:1, 1:6, 7:9, 8:10}
type(b) # dict
print(b[0]) # 인덱스값을 찾는게 아니라 b의 딕셔너리 값들이 상수여서 상수 0을 찾는것
print(a) # {'Korea' : 'Seoul', 'Canada': 'Ottawa', 'USA': 'Washington D.C' }
print(a['Korea']) # Seoul-
항목 추가 및 변경
- 기존에 키가 존재 하면, 새로운 값으로 업데이트
- 존재하지 않으면, 새로운 키, 값 생성
a = {'Korea' : 'Seoul', 'Canada': 'Ottawa', 'USA': 'Washington D.C' } a['Japan'] = 'Tokyo' a['China'] = 'Beijing' print(a) # {'Korea' : 'Seoul', 'Canada': 'Ottawa', 'USA': 'Washington D.C', 'Japan':'Tokyo', 'China':'Beijing' } -
update()
- 두 딕셔너리를 병합함
- 겹치는 키가 있다면 parameter로 전달되는 키 값이 overwrite된다.
a = {'a': 1, 'b': 2, 'c': 3} b = {'a': 2, 'd': 4, 'e': 5} a.update(b) print(a) {'a': 2, 'b': 2, 'c': 3, 'd': 4, 'e': 5} -
key 삭제
- del 키워드 사용
- pop 함수 이용
a = {'a': 1, 'b': 2, 'c': 3} print(a) # {'a': 1, 'b': 2, 'c': 3} a.pop('b') del a['b'] # 범용적으로 지울 수 있는 del print(a) # {'a': 1, 'c': 3} -
clear()
- 딕셔너리의 모든 값을 초기화
a = {'a': 1, 'b': 2, 'c': 3} print(a) # {'a': 1, 'b': 2, 'c': 3} a.clear() print(a) # {} -
in
- key값 존재 확인
- O(1) 연산 - 딕셔너리의 크기와 관계없이 항상 연산의 속도가 일정하다는 의미
a = {'a': 1, 'b': 2, 'c': 3} print(a) # {'a': 1, 'b': 2, 'c': 3} 'b' in a # True 'd' in a # False ## dict의 in은 갯수가 무수히 많든 바로 찾음 -
value access
-
dict[key]로 접근, 키가 없는 경우 에러 발생
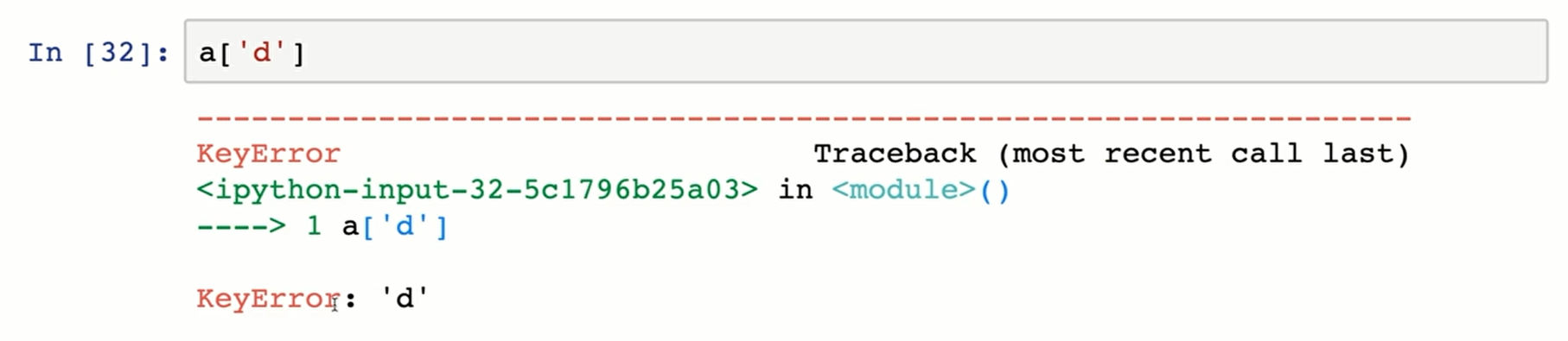
-
.get() 함수로 접근, 키가 없는 경우 None반환

-
모든 keys, values 접근
- keys() - 키만 반환
- values() - 값만 반환
- items() - 키, 값의 튜플을 반환
a = {'a': 1, 'b': 2, 'c': 3}
print(a) # {'a': 1, 'b': 2, 'c': 3}
print(a.keys()) # dict_keys(['a', 'b', 'c'])
print(a.values()) # dict_values([1, 2, 3])
print(list(a.keys())) # ['a', 'b', 'c'] ## list로 변환가능
print(list(a.values())) # [1, 2, 3] ## list로 변환 가능
list(a.items()) # [('a', 1), ('b', 2), ('c', 3)]set
- dictionary에서 key만 활용하는 데이터 구조로 이해
- 수학에서의 집합과 동일한 개념
a = {1, 1, 2, 3, 3, 4, 1, 5}
print(a) # {1, 2, 3, 4, 5} ## 중복을 제거해서 출력함
print(a[0]) # 인덱스 값이 없어 오류남- set()으로 집합으로 변환
a = set() # 빈 set을 생성함
a = [1, 1, 2, 3, 3, 4, 1, 5]
print(a) # [1, 1, 2, 3, 3, 4, 1, 5]
b = set(a)
print(b) # {1, 2, 3, 4, 5}
- set operations
- 수학 연산과 동일
- 교집합, 합집합, 차집합 등 지원
a = {1, 2, 3}
b = {2, 3, 4}
print(a.union(b)) # {1, 2, 3, 4} ## 합집합
print(a.intersection(b))# {2, 3} ## 교집합
print(a.difference(b)) # {1} ## 차집합
print(a.issubset(b)) # False ## 부분 집합
조건문(if, elif, else) 활용하기
condition (조건문)
- 특정 조건을 만족하는 경우에만 수행할 작업이 있는 경우 사용
- 모든 조건은 boolean으로 표현 됨 (예외 사항은 아래 배울 예정)
- if, elif, else 키워드가 사용
- 조건문의 경우 if, elif, else 블록에 종속된 코드는 들여쓰기로 표현 가능
- 즉 아래코드에서와 같이, 조건문 아래에 들여쓰기된 2줄의 코드만이 조건문의 조건에 따라 수행될 수도, 수행되지 않을 수도 있는 코드라고 할 수 있음
- 들여쓰기 된 코드를 블록(block), 또는 코드블록이라고 함
- python에서 모든 블록의 시작점의 마지막에는 :(콜론, colon) 추가가 필요
if 6 >= 5:
print ('6 is greater than 5')
print ('Yeah, it is true')
print ('This code is not belongs to if statements')- Logical AND, OR, NOT
- 조건문에 사용되는 조건의 경우, boolean이기 때문에, 논리식 AND, OR, NOT이 사용 가능
- AND : and
- OR : or
- NOT : not
- 논리표
- AND
- T AND T : T
- T AND F : F
- F AND T : F
- F AND F : F
- OR
- T OR T : T
- T OR F : T
- F OR T : T
- F OR F : F
- NOT
- NOT T : F
- NOT F : T
- AND
- 우선순위
- NOT > AND > OR
if의 조건이 bool이 아닌 경우
- 일반적으로는 조건문에는 bool이 주로 위치 함
- 하지만, 정수, 실수, 문자열 리스트 등 기본 타입도 조건에 사용 가능
- False로 간주되는 값( 각 타입의 기본값)
- None
- 0
- 0.0
- ''
- [] -> 빈 리스트
- () -> 빈 튜플
- {} -> 빈 딕셔너리
- set() -> 빈 집합
- 그 밖에는 모두 True로 간주
if, else
- if가 아닌 경우, 나머지 조건을 표현하고 싶다면 바로 아래 else 블락 사용
- 이 경우, if조건이 True인 경우, if 블락의 코드가 수행, 거짓인 경우 else 블락의 코드가 수행
- 주의 할 점: if와 else사이에 다른 코드 삽입 불가
# 짝수인 경우에는 2로 나눈 값을 출력하고
# 홀수인 경우에는 1을 더한 값을 출력해라
a = 10
if a % 2 == 0: # 짝수인지 판별
print(a / 2)
else:
print(a + 1)
5.0if, elif, else
- 조건이 여러개인 경우, 다음 조건을 elif 블록에 명시 가능
- 이 경우, 각 조건을 확인 후, True인 조건의 코드 브락을 실행 한 후, 전체 if, elif, else 구문을 종료
- 조건문을 사용할 때는, if 이후, 0개 이상의 elif를 사용 가능하며 0개 또는 1개의 else를 사용 가능함

중첩 조건문(nested condition)
- 조건문의 경우 중첩하여 작성 가능
- 중첩의 의미는 depth(깊이)로 생각할 수 있으며, depth의 제한은 없음
a = 10
b = 9
c = 8
if a == 10:
if c == 8:
if b == 8:
print('a is ten and b is 8')
else:
print('a is ten and b is not 8')