Apache Spark 기초
Spark 개요 (Spark Software Components)
Spark Software Components (1/2)
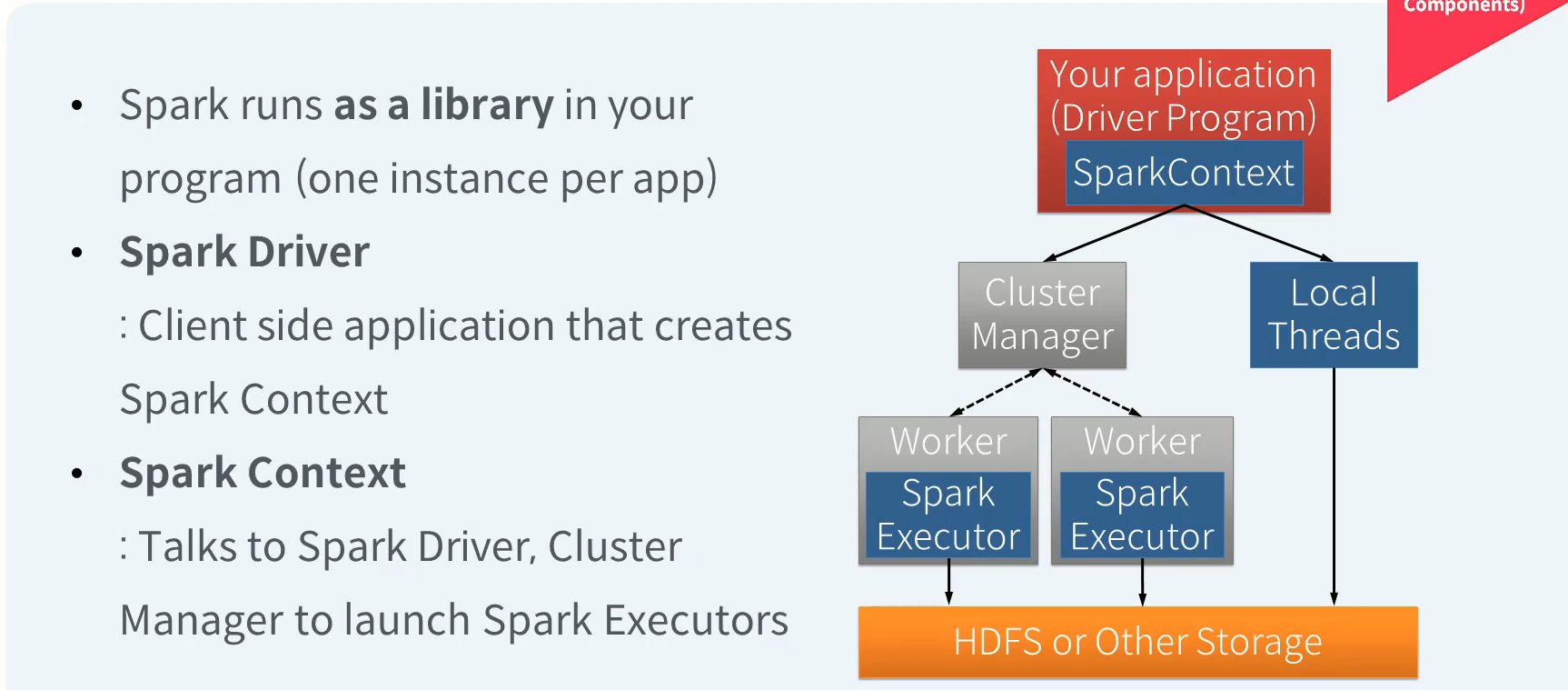
Driver는 클라이언트 사이드의 어플리케이션으로서 Spark 프로그램의 시작점인 Spark Context를 내부에 생성하고 유지합니다. Spark의 동작은 Spark Context로부터 시작됩니다. Driver는 Spark Context를 통해 Spark Standalone, Hadoop YARN과 같은 Cluster manager와 통신하여 실제 분산 병렬 연산을 수행하는 Executor 생성을 요청하게 됩니다.
Spark Software Components (2/2)

로컬 환경은 여러 머신이 아닌 단일머신에서 로컬 cpu 코어를 통해 병렬 쓰레드로 여러 task들을 수행합니다. 반면 분산 환경은 복수개의 머신에서 각 서버의 cpu 코어를 통해 다수개의 task들을 분산 병렬로 수행하게 됩니다. 결국 우리가 작성하여 실행하는 spark 어플리케이션은 하나의 드라이브 프로그램과 복수개의 Executor들로 구성되어 실행됩니다. 각각의 Executor들은 드라이브가 할당한 task들을 병렬로 실행하고 그 결과를 드라이브에게 전달합니다. spark 어플리케이션을 로컬환경에서 실행하면 익스큐트 프로그램은 별도로 실행되지 않고 드라이버 프로그램의 프로세스 내에서 로컬 스레드로 실행됩니다. 스팍 어플리케이션을 분산환경에서 실행하면 익스큐트 프로그램은 클러스터 매니저가 할당해준 서버들 위에서 각각 별도의 프로세스로 실행된다.
Submitting Applications on Cluster
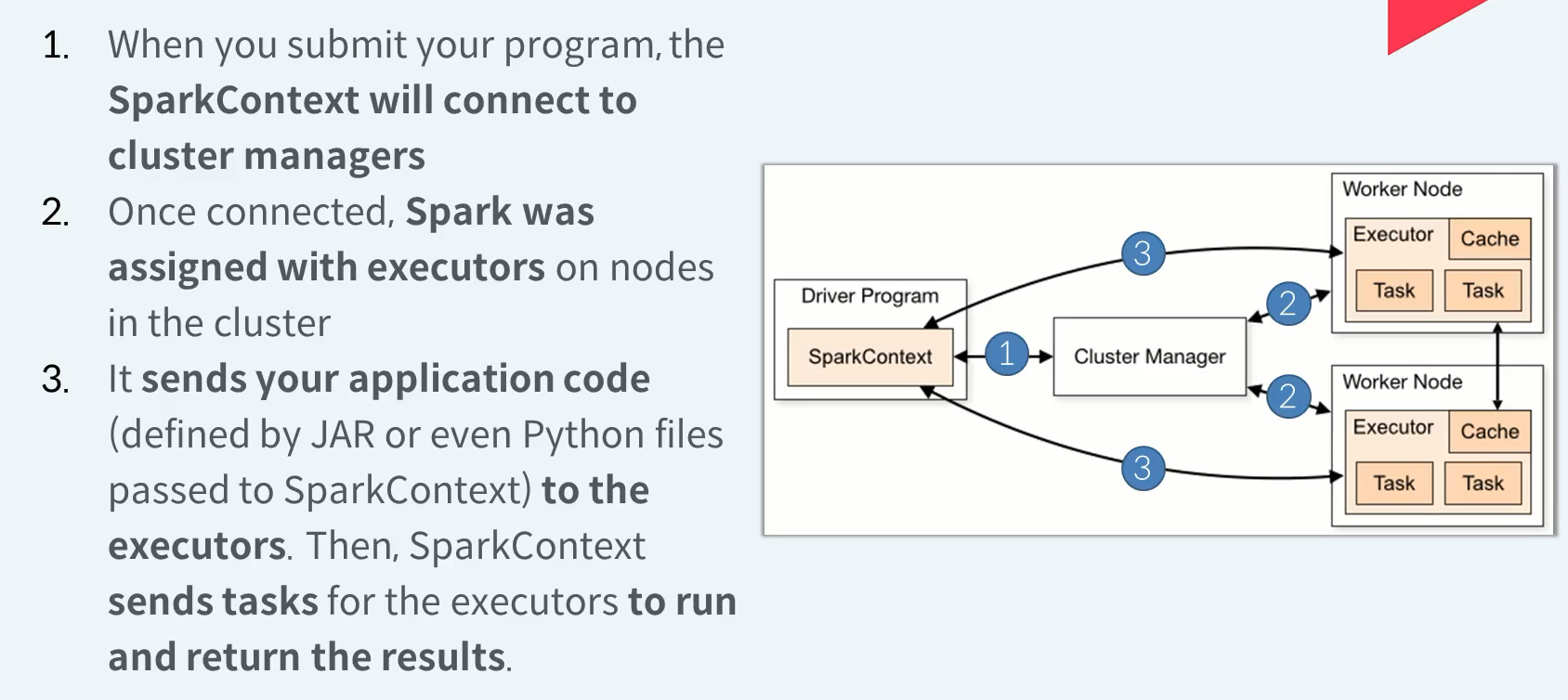
- 프로그램을 제출하면 Spark Context가 클러스터 관리자에 연결됩니다.
- 연결되면 스파크는 클러스터의 노드에서 실행자와 함께 할당됩니다.
- 애플리케이션 코드(JAR에 의해 정의되거나 SparkContext에 전달된 Python 파일에 의해 정의됨)를 실행자에게 보냅니다. 그런 다음 SparkContext는 실행자가 실행하고 결과를 반환할 수 있도록 작업을 전송합니다.
Spark 개요 (Spark Programming Model)
Spark Programming Model - SparkContext
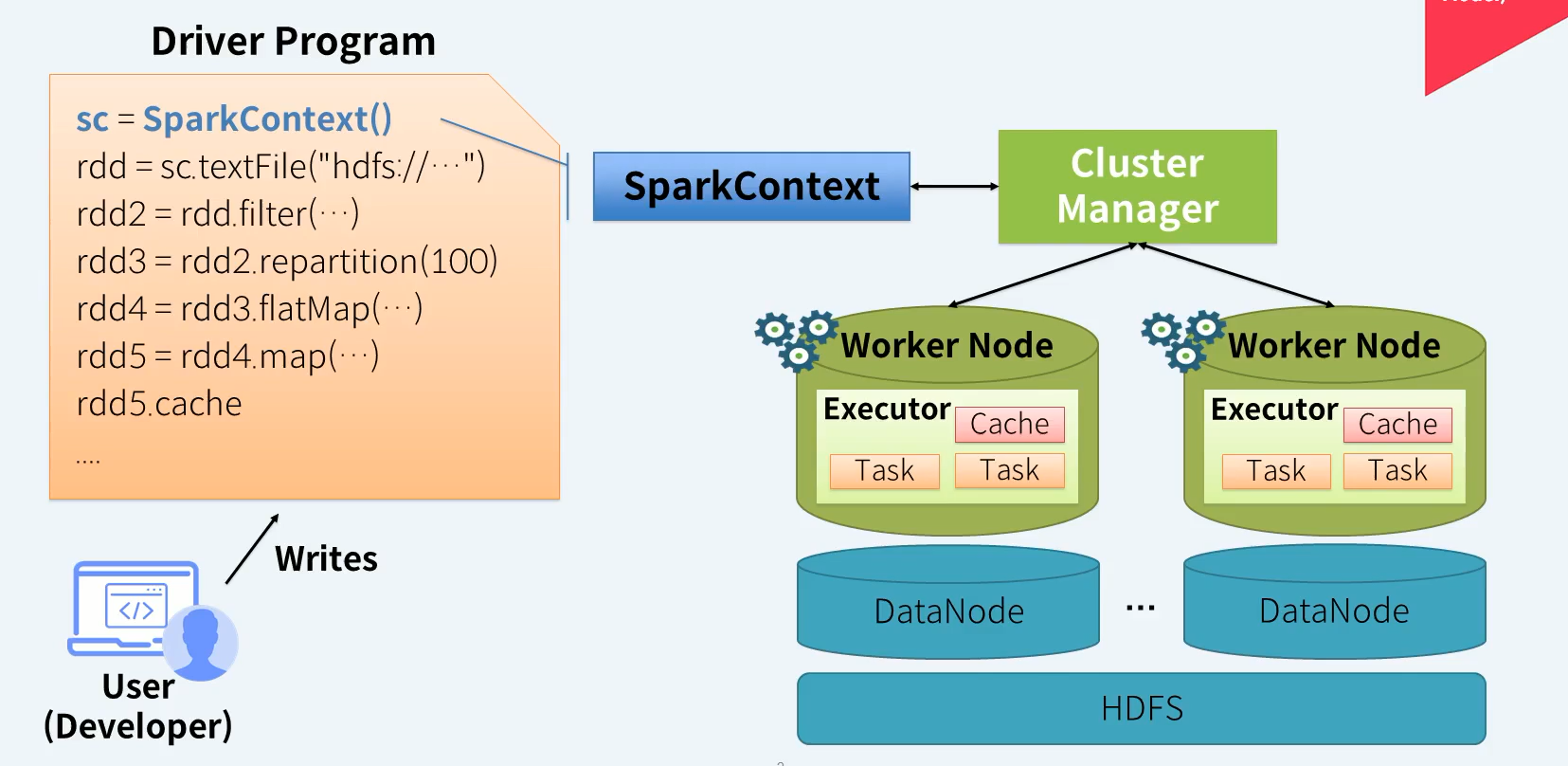
SparkContext는 클러스터 매니저에게 Executor 생성을 요청합니다. 실제 데이터를 읽고 처리하고 저장하는 것은 Executor의 타스크를 통해 이루어집니다. 데이터 캐시도 Executor의 메모리를 사용합니다.
Spark Programming Model - RDD (1/2)
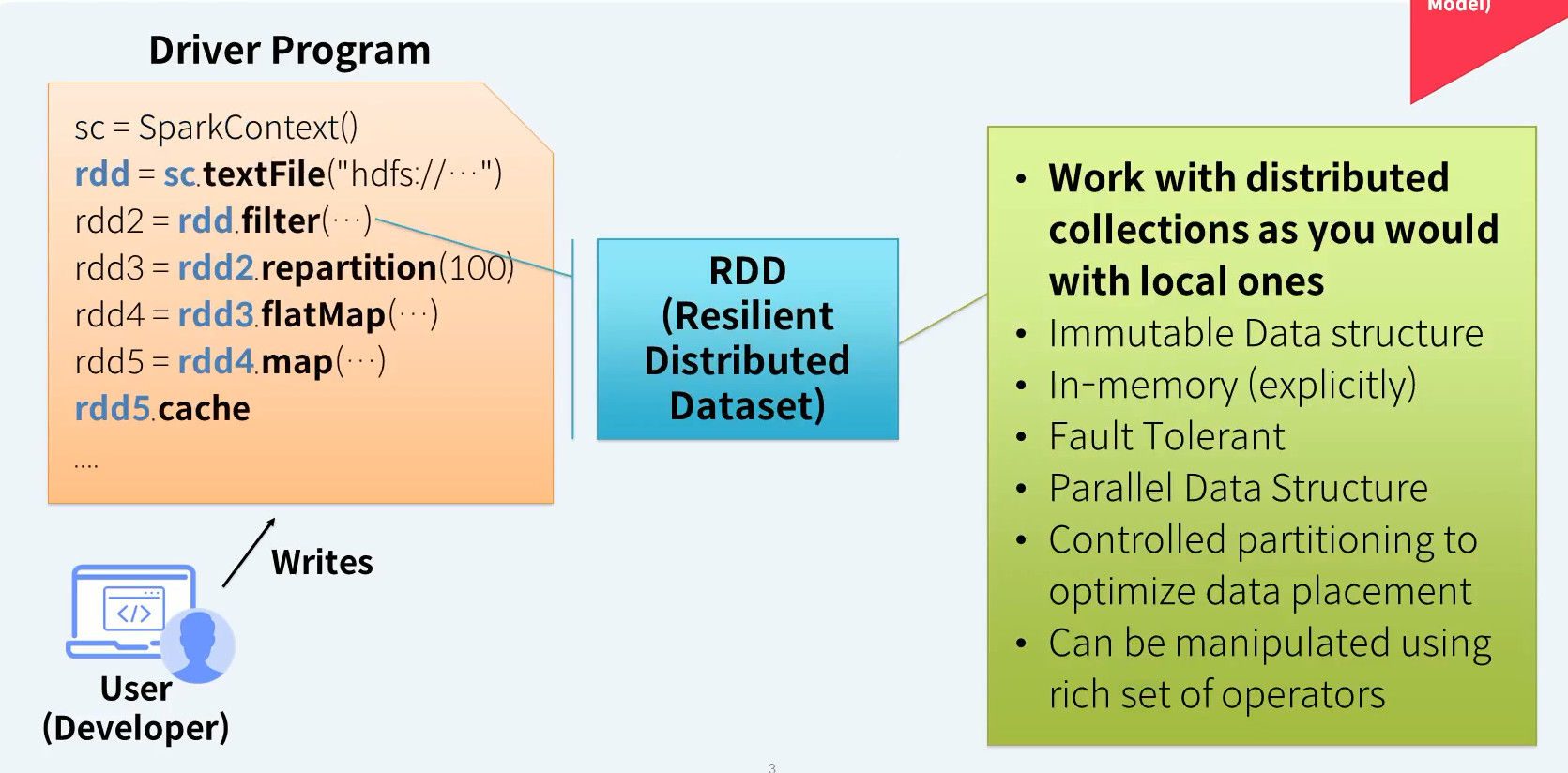
- 로컬 컬렉션과 마찬가지로 분산 컬렉션 작업
- 불변의 데이터 구조
- 인메모리(명시적으로)
- 내결함성
- 병렬 데이터 구조
- 데이터 배치를 최적화하기 위한 제어된 파티셔닝
- 풍부한 연산자 집합을 사용하여 조작할 수 있음
Spark Programming Model - RDD (2/2)
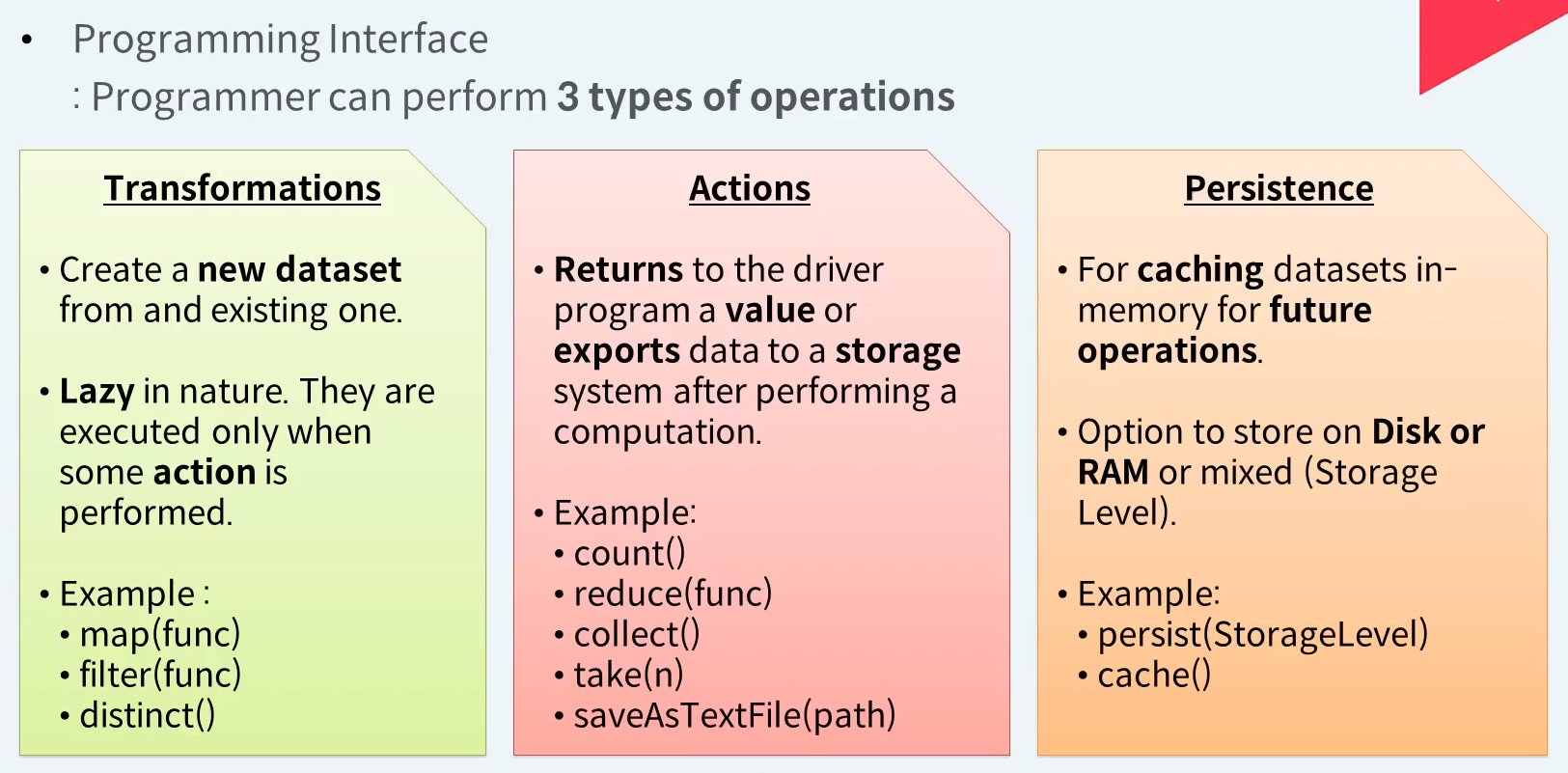
RDD가 제공하는 API는 크게 3가지가 있다. RDD에 담겨진 데이터의 변경을 위한 Transformations API, RDD에 담겨진 데이터를 드라이브에 가져오거나 외부 저장소에 저장하는 Actions API, 반복적으로 자주 사용될 것 같은 RDD를 성능 향상을 위헤 메모리나 디스크에 캐시하기 위한 Persistence API가 그 3가지 입니다.
Transformations :
- 기존 데이터 집합에서 새 데이터 집합을 만듭니다.
- 천성이 게으르다. 일부 작업이 수행될 때만 실행됩니다.
Actions :
- 계산을 수행한 후 dirver 프로그램으로 값을 반환하거나 데이터를 스토리지 시스템으로 내보냅니다.
Persistence :
- 향후 작업을 위해 데이터셋을 메모리에 캐슁하는 데 사용됩니다.
- Disk 또는 RAM에 저장하거나 혼합(스토리지 수준)하는 옵션
Spark 개요 (RDD - Lazy Evaluation + No Cache/Cache)
RDD - Lazy Evaluation + No cache
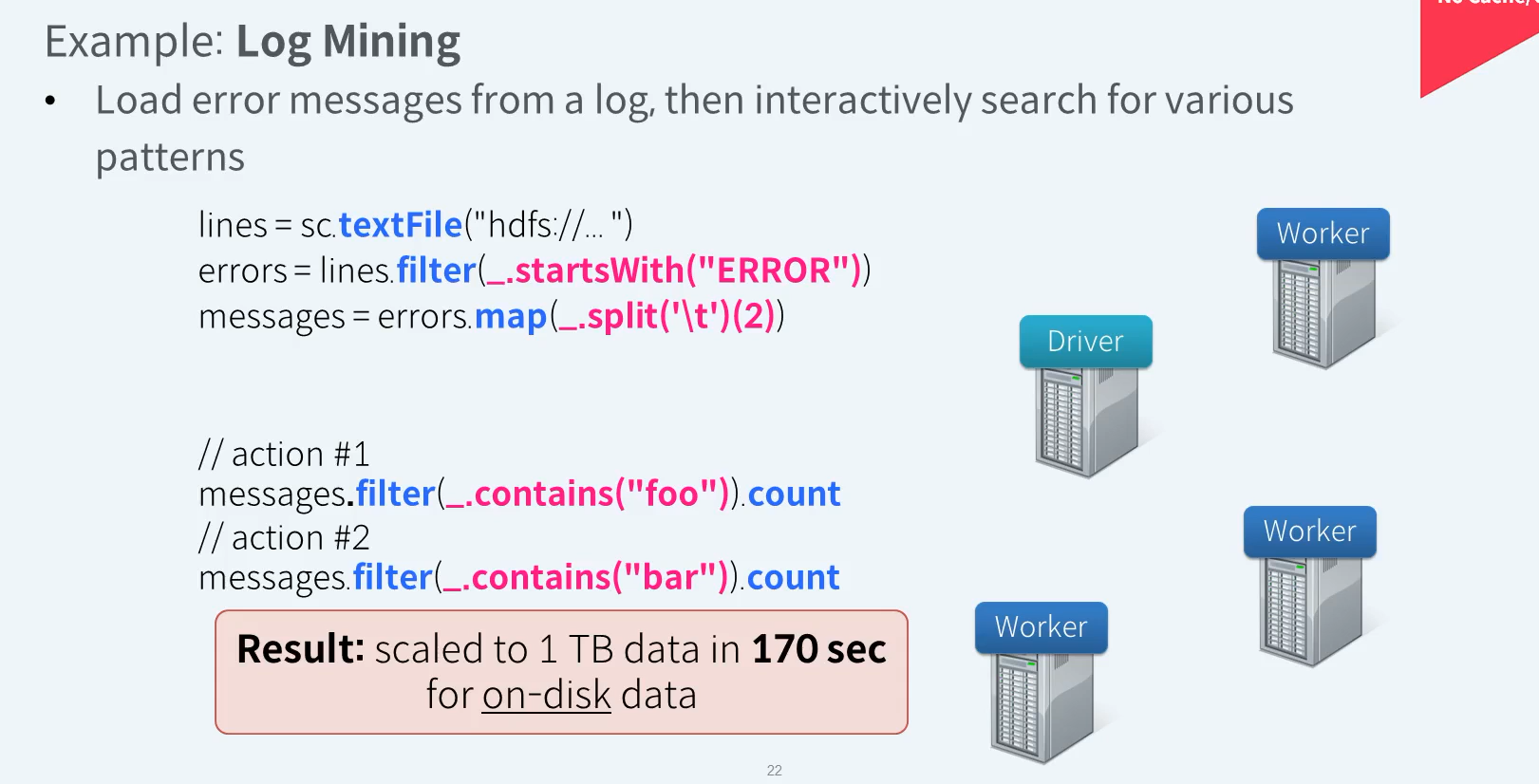
분석 클러스터는 마스터 서버 1대와 워크서버 3대로 구성되어 있습니다.
RDD - Lazy Evaluation + Cache

동일 작업에 대해 메모리 캐시를 이용하면 1TB의 데이터에 대해서도 5~7초 사이에 결과를 확인할 수 있다고 한다. 반복적으로 사용되는 RDD에 대한 Cache는 성능 향상을 가져옵니다.
RDD - Behavior with Less RAM
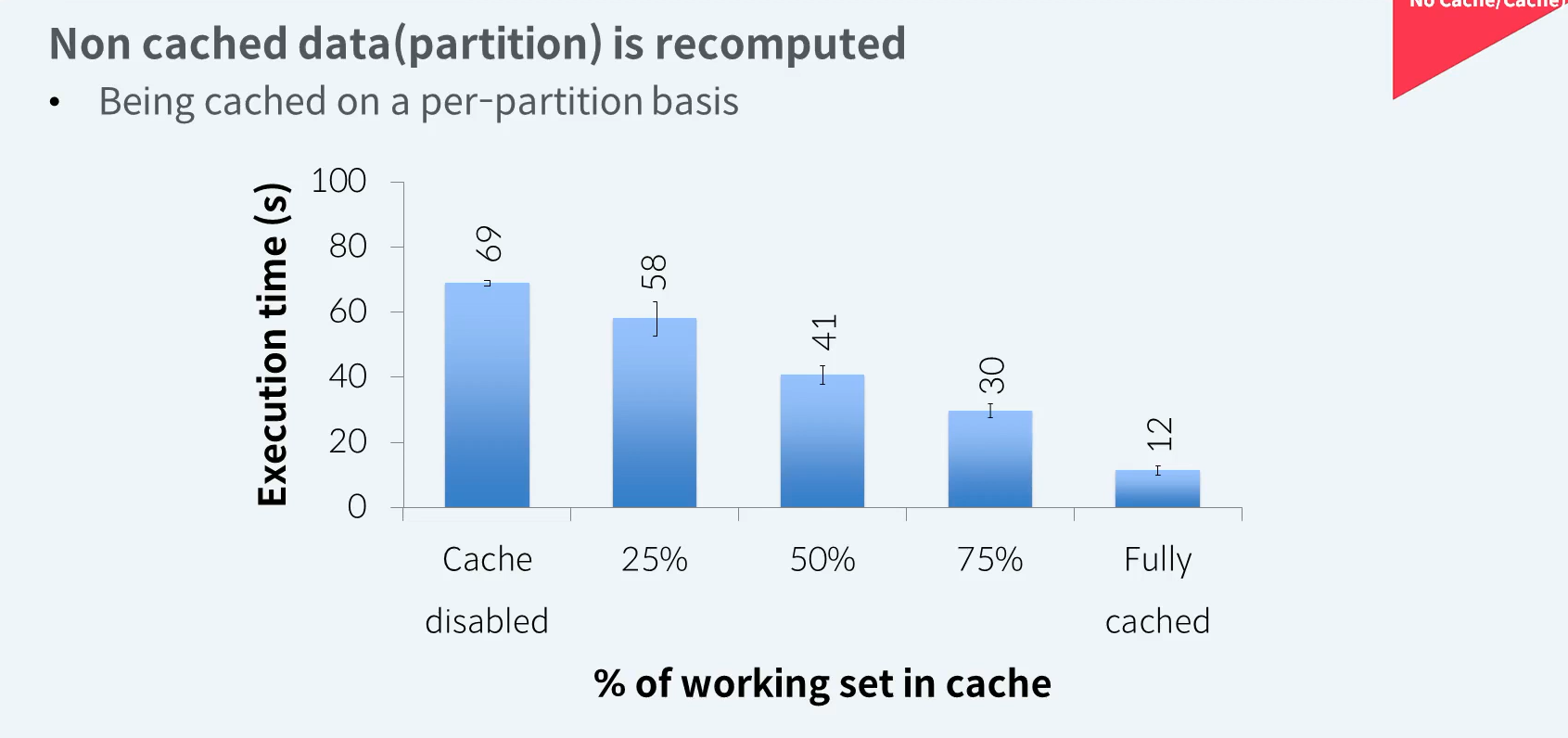
캐시는 RDD에 파티션 단위로 처리됩니다. 하나의 파티션을 메모리에 모두 캐시하기에 충분한 메모리가 없다면 메모리에 일부 여유가 있더라도 파티션의 일부만 캐시하지 않습니다. 하나의 파티션 전체가 캐시되거나 캐시되지않거나 입니다. 캐시되지 않는 파티션의 데이터는 디스크의 저장된 원본파일로부터 다시 읽어서 연산을 수행합니다 .메모리에 여유가 생겨 해당 파티션을 캐시하기 전까지는 Action 수행시마다 캐시되지 않은 파티션의 데이터는 디스크로부터 반복적으로 다시 읽어와야 합니다. 당연히 캐시된 파티션이 많을수록 실행속도는 빨라질것입니다.
Spark 개요 (RDD - Fault Tolerance)
RDD - Fault Tolerance
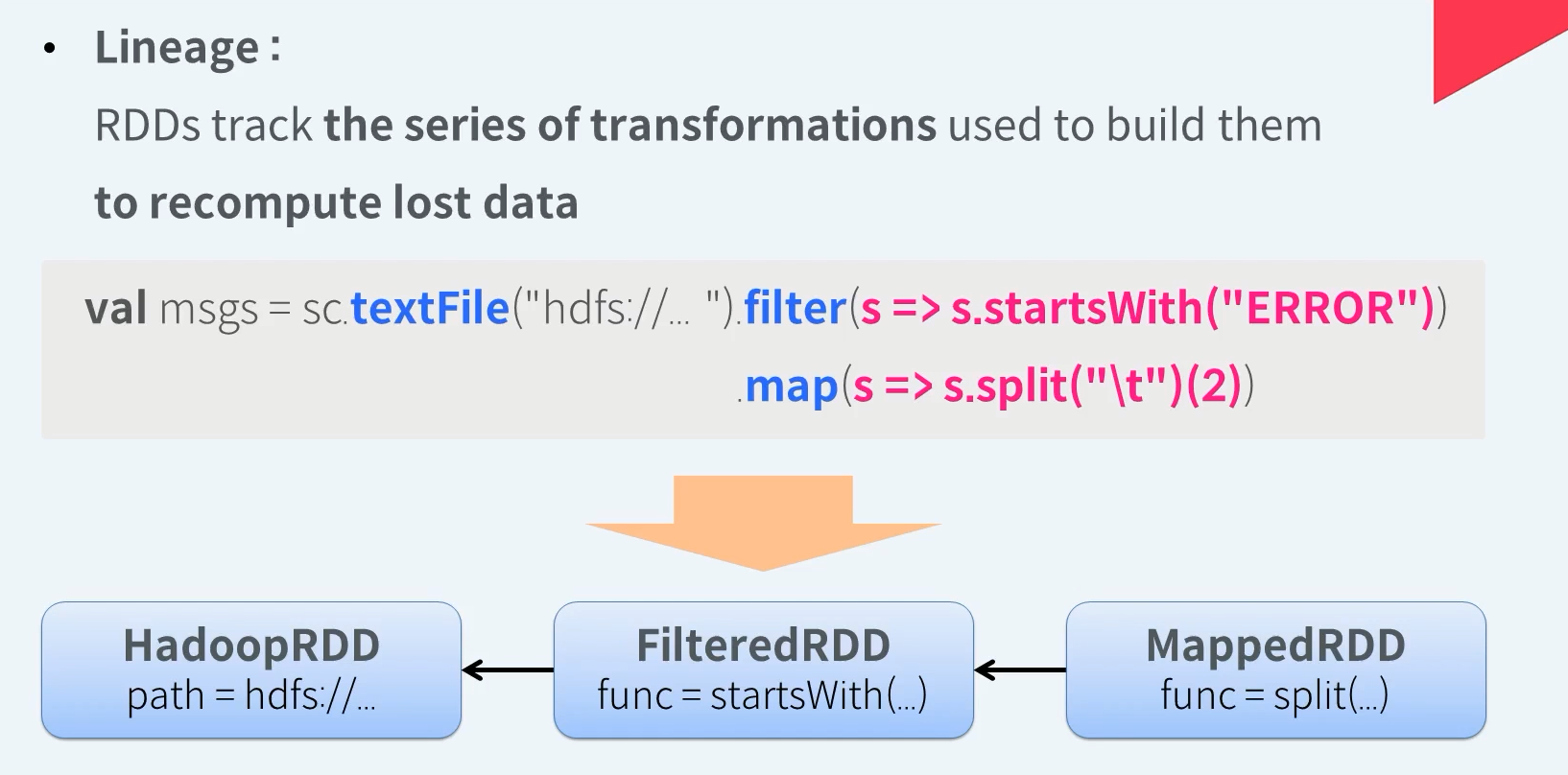
Apache Spark은 특정 RDD가 만들어지기까지 수행된 일련의 트랜스포메이션 작업들을 추척하고 있습니다. 이를 Lineage라 부릅니다. RDD의 혈통을 기록한것이라고 생각하면 됩니다. 이는 손실된 데이터를 다시 계산하여 결함이 발생한 RDD를 복구하는데에 사용됩니다. 예를 들어 메시지 RDD의 Lineage는 HDFS에 있는 특정 경로에 데이터를 읽어와 에러 메세지만 필터링 하고 구분자로 사용된 탭으로 스플릿하여 인덱스 인 위치의 값을 추출한다는 일련의 변환작업이 기록되어 있습니다.
RDD - Fault Recovery Test

첫번째 액션에서 실제 메모리에 캐시하는 작업이 이루어지기 때문에 실행시간이 조금 많이 걸립니다. 두번째 액션부터는 캐시된 데이터로 부터 연산이 시작되기 때문에 상대적으로 짧은 시간에 실행이 이루어집니다. 다섯번째 액션을 정상 실행한 후 장애가 발생합니다. 캐시된 데이터중 일부가 손실됩니다. 여섯번째 액션에서 손실되지 않은 캐시데이터는 정상적으로 사용됩니다. 손실된 일부 캐시데이터는 Lineage를 통해 처음부터 다시 재연산 됩니다. 이를 통해 캐시는 다시 100% 정상으로 복구됩니다. 이 과정에서 손실된 일부 데이터를 디스크에서 다시 읽어와 재연산하기에 시간이 다소 더 걸립니다. 하지만 대부분 정상적인 캐시를 사용하므로 첫번째 액션 수행보다는 짧은 시간안에 실행이 이루어집니다. 일곱번째 액션부터는 실행속도가 기존처럼 다시 빨라집니다.
