Overview
2010년 트위터, 페이스북, 아마존 등의 글로벌 기업들이 급부상했습니다. 모바일 등의 클라이언트 증가로 사용자와의 인터랙티브가 많아졌습니다. 이렇게 많은 요청과 응답이 왔을 때 기존 RDBMS로는 성능적인 문제를 해결하기 위해 많은 비용을 들여야 했습니다. 또한 실시간 정보를 처리하는 기업들이 많아지면서 연산 속도가 중요해졌습니다.
쿠팡은 하루에 350만명 이상이 접속하는 대규모 트래픽이 발생합니다. 회원 정보와는 무관하게 이러한 350만명에게는 똑같은 메인페이지가 보여집니다. 이렇게 같은 데이터를 수백만번, 수천만번 웹 서버에서 요청을 받아 DB에게 동일한 쿼리를 날려 정보를 가져오는 것은 효율적이지 않아 보입니다. 또한 대다수의 방문자는 다른 방문자가 조회한 페이지와 중복된 데이터를 많이 요청하곤 합니다.
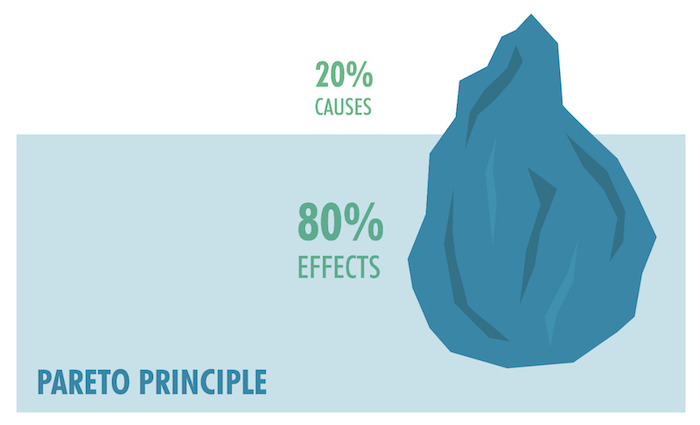
사회현상을 분석할 때 '파레토의 법칙' 이라는 유명한 이론이 있습니다. 상위 20%의 원인이 80%의 효과를 만들어낸다고 하여, 국가의 소비 80%는 상위 소득 20%의 인구가 만들어낸다는 이야기가 좋은 예입니다. 웹 사이트 접근 또한 마찬가지입니다. 하나의 웹 사이트 접근 80%가 사용하는 데이터는 고작 20%밖에 되지 않아, 이 20%를 효율적으로 관리하면 자원 관리를 극적으로 향상할 수 있다고 합니다.
우리는 이 자주 오는 요청을 기억하고 같은 요청이 왔을 때 이미 사용했던 데이터를 효율적이고 빠르게 건네주고 싶을 것입니다. 이 방식으로 주로 '캐싱'을 사용하곤 합니다.
Cache
효율을 중시하던 웹 서비스는 자원관리를 위한 다양한 캐싱전략이 나왔습니다.
Cache Aside
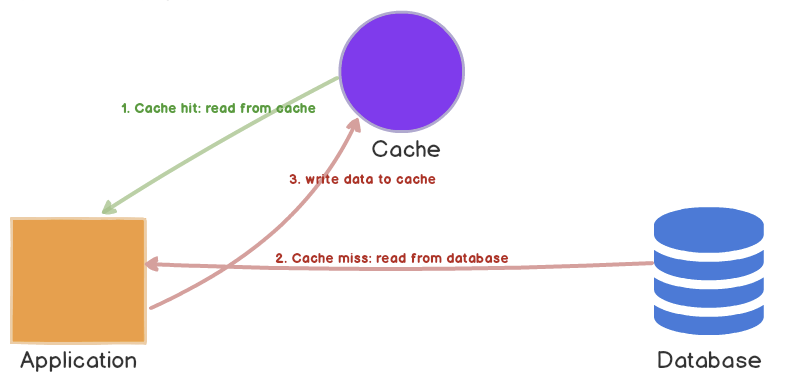
Cache Aside 방식은 캐시 서버를 두고 필요할 때만 데이터를 캐시에 로드하는 전략입니다.
최초 방문자가 요청을 했을 때, 캐시 스토리지에는 아무 데이터가 없을 것입니다. 먼저 애플리케이션은 캐시 저장소에 데이터가 있는지 조회를 합니다. 하지만 데이터가 없기 때문에 기존에 사용하고 있던 DB를 조회하고 데이터를 반환합니다. 그런 다음 애플리케이션은 Cache 저장소에 가져왔던 데이터를 저장합니다.
두 번째 방문자가 같은 요청을 하게 되면, 역시 캐시 저장소에 데이터가 있는지 조회를 합니다. 데이터가 있기 때문에 바로 데이터를 반환합니다.
읽기 요청이 많은 경우에는 성능적인 이점이 많습니다. 또한 DB에 기반하여 데이터를 관리하기 때문에 캐시 저장소가 눕더라도 전체 시스템에 이상이 없습니다. 하지만 캐시에 없는 데이터를 가져오는 경우 조회를 두번하게 되므로 시간이 더 걸릴 수 있습니다. 또한 기존 DB 데이터가 최신화가 안되어있는 경우가 있어 동기화 문제가 생길 수 있습니다.
Read-Through
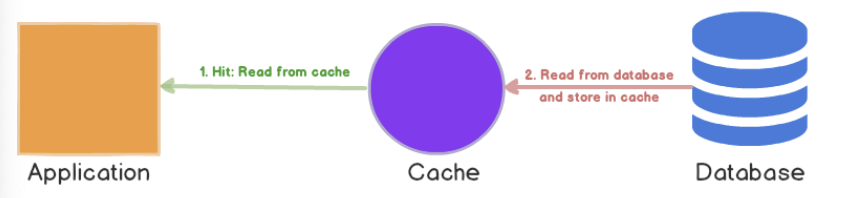
Cache Aside 방식과 유사합니다. 캐시 미스가 발생하면 데이터베이스에서 누락된 데이터를 로드하고 캐시를 채우고 애플리케이션에 반환합니다. 하지만 애플리케이션이 캐시를 채우는 역할을 하느냐 마느냐에 달려 있습니다.
Write-Back (Write-Behind)
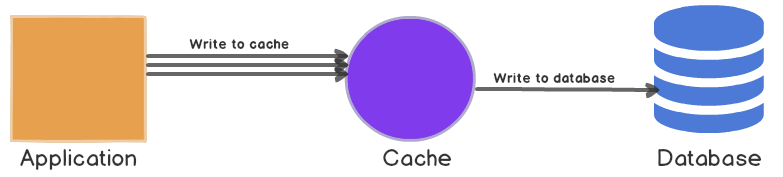
캐싱 전략은 '읽기' 뿐만 아니라 '쓰기' 성능 향상을 목적으로도 사용할 수 있습니다. 지연쓰기 전략으로 쓰기 연산을 캐싱한 뒤 master DB에 벌크로 쓰기 연산을 하는 방식입니다.
이 전략은 쓰기가 많은 방식에 적합합니다. Read-Through와 결합해서 가장 최근에 업데이트되고 엑세스 된 데이터를 항상 캐시에서 사용할 수 있는 작업에 적합합니다. 데이터 베이스에 대한 전체 쓰기를 줄 일 수 있어서 비용이 감소할 수 있습니다.
물론 캐시가 DB에 쓰기를 하지 않았을 때 캐시에 이상이 생기면 데이터는 전부 소실될 수 있습니다.
이외에도 다양한 캐싱 전략이 있습니다.
In-Memory
캐싱 방법은 기존 DB와는 다르게 효율적인 방식으로 데이터를 접근하여 성능을 높입니다. 주로 사용하는 RDBMS는 무결성을 위해 Disk에서 데이터를 읽어옵니다. 하지만 캐싱 기법을 사용하는 기술들은 메모리에서 데이터를 가져옵니다.
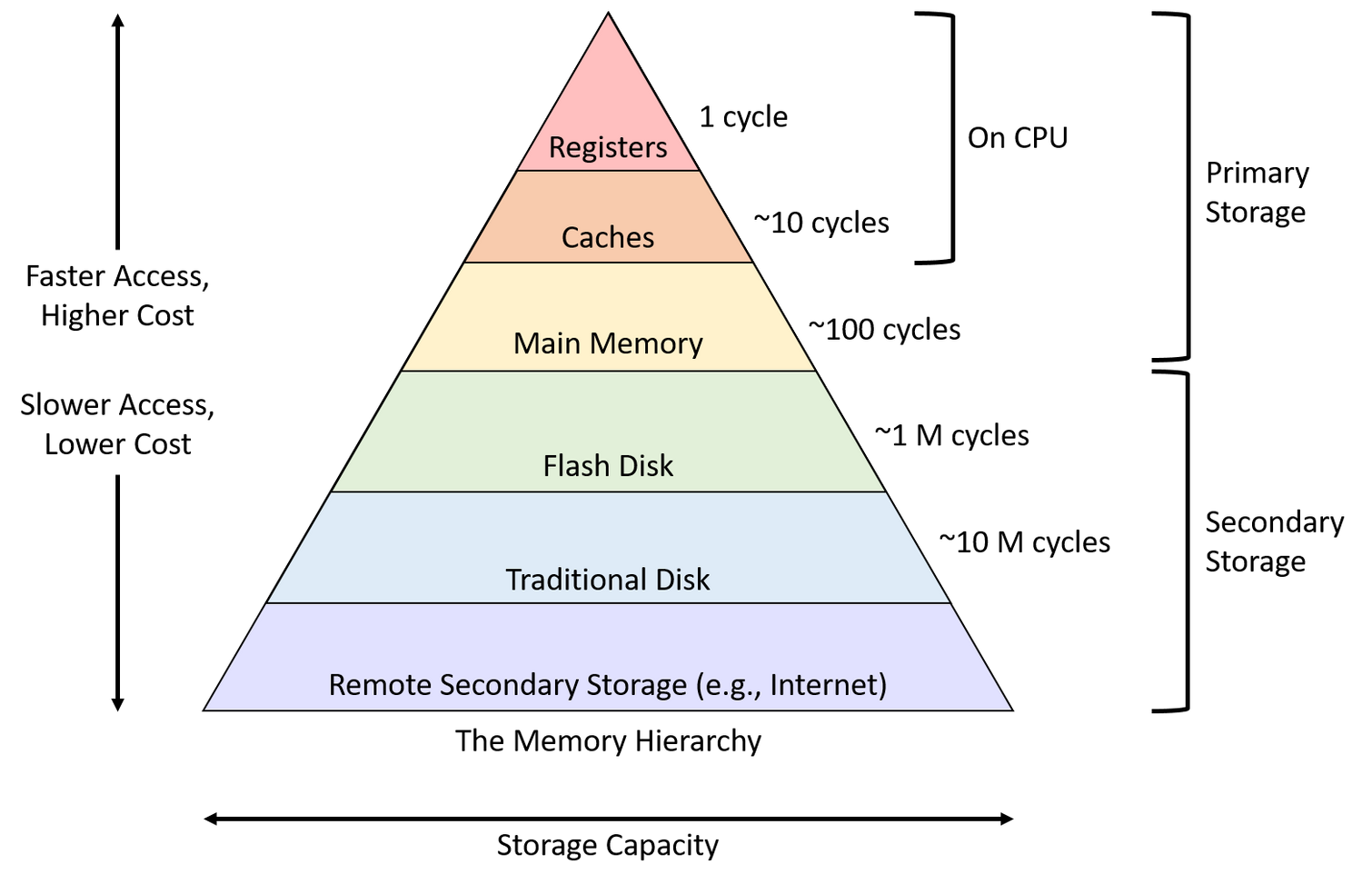
위의 그림은 메모리 계층구조입니다. 상위의 계층일수록 접근 속도가 빠르며, 비용이 많이 듭니다. 반대로 아래의 계층은 접근속도가 느리고 비용이 적게 듭니다. 흔히 우리가 컴퓨터를 구매할 때 RAM(Random Access Memory)을 고려하는데, RAM이 Main Memory의 일부입니다. 조금 더 메모리 구조를 파고들어가면 CPU가 어떻게 메모리를 사용하는 방법도 알 수 있지만 생략합니다.
기술의 발전으로 많은 데이터를 빠르게 연산하는 방법이 고도화가 되었습니다. 하지만 Disk의 성능을 향상시키는 방법으로 CPU,메모리,하드디스크를 향상시키는 스케일업과 서버의 수를 늘리는 스케일아웃이 있었지만 물리적인 한계와 비효율적인 자원낭비가 심했습니다. 그래서 기술적인 방법으로 해결하는 방법을 모색했고 HDD, SDD가 속해있는 Disk 계층보다도 효용성을 중시할 수 있는 Main Memory의 사용 비중이 높아지고 발전했습니다.
NoSQL
분산 환경에서 대량의 데이터를 빠르게 처리하기 위해서는 RDBMS는 적합하지 않았습니다. 대안으로 나온 NoSQL은 데이터를 빠르게 처리할 수 있는 구조와 함께 스케일 아웃에 따라 선형적인 성능의 발전을 확인할 수 있는 데이터 베이스입니다.
NoSQL의 특징은 아래와 같습니다.
NoSQL 특징
- 거대한 Map으로서 key-value 형식을 지원한다.
- RDBMS가 데이터의 관계를 Foreign Key 등으로 정의하고 Join 등 관계형 연상을 하지만 NoSQL은 관계를 정의하지 않는다.
- 대용량 데이터 저장을 한다.
- 분산형 구조를 통해 여러대의 서버에 분산하여 저장하고 상호복제하여 데이터 유실이나 서비스 중지에 대비한다.
- Schema-less
- 읽기 작업보다 쓰기 작업이 더 빠르며, 일반적으로 RDBMS에 비하여 쓰기와 읽기 성능이 빠르다.
NoSQL이 분산환경에 최적화 되어있는 이유는 CAP 이론으로 확인할 수 있습니다.
CAP 이론
분산형 구조는 Consistency, Availability, Partition Tolerance의 특징을 가지고 있습니다. CAP이론은 이 중 2가지만 가지고 있어도 분산형 구조로 Database를 구성할 수 있다는 이론입니다. RDBMS는 CA의 특징을 가지고 있으며 Redis는 CP의 특징을 가지고 있습니다. CAP를 모두 만족하는 데이터베이스는 현재 존재하지 않습니다.
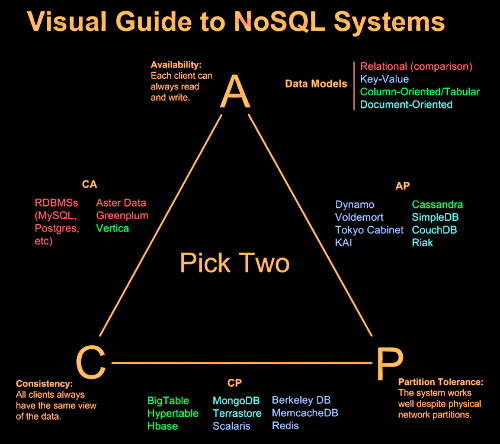
- 일관성(Consistency) : 분산된 노드 중 어느 노드로 접근하더라도 데이터 값이 같아야 한다.
- 가용성(Availability) : 클러스터링된 노드 중 하나 이상의 노드가 실패(Fail)히더라도 정상적으로 요청을 처리할 수 있는 기능을 제공한다.
- 분산 허용(Partition Tolerance) : 클러스터링 노드 간에 통신하는 네트워크가 장애가 나더라도 정상적으로 서비스를 수행한다. 노드 간 물리적으로 전혀 다른 네트워크공간에 위치도 가능하다.
Redis
앞서 얘기한 여러 이점을 활용하기 하기위해서 우리는 캐싱 전략에 적합한 In-Memory 기반의 NoSQL 데이터베이스인 레디스를 사용합니다.
Redis의 개념
레디스는 Remote Dictionary Server의 약자입니다. Dictionary는 Java, Javascript에서의 Hashmap, Python에서의 Dictionary와 같이 Key-value를 사용해서 데이터를 반환하는 자료구조입니다.
Remote Dictionary Server
- 외부에 있는 Dictionary(Hash Map, Key-value)를 사용하는 서버이다.
- Database, Cache, Message broker
- In-memory Data Structure Store
- Supports rich data structure
- Only 1 Commiter
Redis는 모든 데이터를 메모리에 영구적(임의로 삭제하거나 Expire를 설정하지 않으면)으로 저장하고 조회합니다. 단, 다른 In-Memory 데이터베이스인 Memcached와 기능적인 차이가 있습니다. Redis는 다양한 자료구조를 지원합니다.
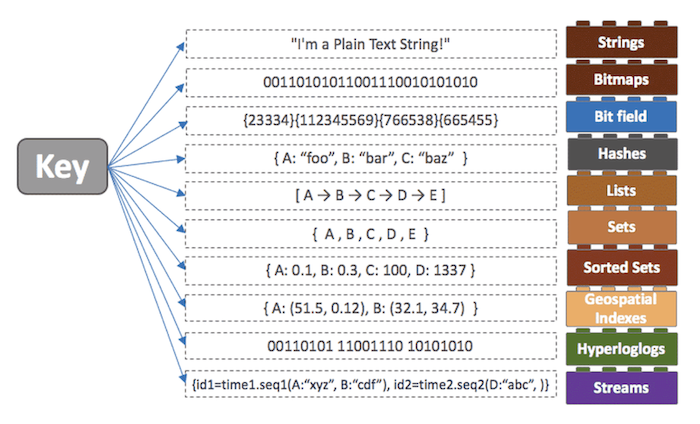
Redis는 기본적으로 String, List, Set, Sorted Set, Hash 등 많은 자료구조를 제공합니다. 따라서 레디스를 사용하면 해당하는 자료구조를 바로 서비스에서 사용할 수 있습니다. 이외에도 Redis는 Memcached에 비해 다양한 장점과 단점이 있습니다. 자바 진영의 스프링 프레임워크는 Redis가 캐싱과 세션 관리에 있어서 더욱 강력한 기능을 가졌다고 판단하여 Redis를 채택하였습니다.
Redis 특징
- key-value 스토어 : 단순 스트링에 대한 Key-Value 구조를 지원
- Key, Value 모두 512MB
- 바이너리 데이터 쓰기 가능
- 컬렉션 지원 : List, Set, Sorted Set, Hash 등의 자료구조를 지원함
- Pub/Sub 지원 : Publish/Subscribe 모델을 지원.
- 메시지 브로커로 사용
- 디스크 저장
- 현재 메모리 상태의 스냅샷을 남기는 기능 'RDB' / 지금까지 실행된 업데이트 관련 명령어의 집합 'AOF'
- RDB : 메모리 내용을 저장하는 기능 외에는 아무것도 지원하지 않는다. (데이터베이스가 아니다)
- AOF (Append Only File) : set / del 등의 업데이트 관련 명령어를 그대로 기록함
- 복제 (replication) : 다른 노드에서 해당 내용을 복제할 수 잇는 마스터/슬레이브 구조를 지원
- 빠른 속도 : 이상의 기능을 지원하면서도 초당 100,000 QPS (Queries Per Second) 수준의 높은 성능을 자랑
- Expire : 레디스는 In-Memory인 만큼 메모리에 저장될 수 있는 데이터가 한정적입니다. 따라서 데이터를 주기적으로 삭제해주는 로직이 필요한데, expire은 데이터를 입력할 때 사용기한을 직접 설정해주는 기능입니다.
Redis use case
- Remote Data Store : a,b,c 서버에서 데이터를 공유하고 싶을 때 사용
- Cache
- 인증 토큰 등을 저장
- 랭킹 보드 사용(sorted set)
- 유저 api limit
- 잡 큐(list), 메시지 브로커
Redis 자료구조
Strings
Strings 타입은 Redis에서 가장 기본적인 Type 입니다. Key-value 형식이며 binary safe한 특징을 가지고 있어, 어떠한 데이터의 종류도 key, value가 될 수 있습니다.

- 값의 최대 길이는 512MB 입니다.
- INCR, DECR, INCRBY 명령어를 통해 thread safe한 Atomic Counter를 구현할 수 있다.
- APPEND 명령어를 통해 값을 이어나갈 수 있습니다.
- GETRANGE, SETRANGE 명령어를 통해 랜덤 액세스가 가능합니다. 랜덤 액세스는 값의 어느 위치든 index를 통해 접근할 수 있는 기능입니다. (값의 중간을 조회할 수 있다.)
set [key] [value]
get [key]
set [key] [value] ex [seconds]
setex [key] [value] [seconds]
# -1은 설정 x, -2는 만료
ttl [key]
append [key] [append value]
getrange [key] name [from index] [to index]
setrange [key] [index] [value]
incr [key]
decr [key]Lists
Lists는 Linked List와 유사한 형태로 데이터가 저장되는 Redis에서 제공하는 자료구조입니다. 따라서 처음과 마지막 부분에 element를 추가 / 삭제 / 조회하는 것은 O(1)의 속도를 가지지만 중간 특정 index를 조회할 때는 O(N)의 속도를 가지는 단점을 가지고 있습니다. 따라서 중간의 값을 가져올 때는 Sorted Set 자료구조가 용이합니다.
- lpush, rpush를 통해 각각 가장 앞에 오는 값과, 가장 마지막에 오는 값을 삽입할 수 있습니다.
- 소셜 네트워크에서 타임라인 같은 기능을 구현할 때 lpush와 lrange를 통해 일정한 크기의 리스트를 빠르게 반환할 수 있습니다.
- lpush와 ltream을 사용해서 Lists의 크기를 유지할 수 있다.
- lpush와 lpop를 통해 message를 전달하는 queue의 형태로 사용할 수 있습니다.
lpush [key] [element]
rpush [key] [element]
lrange [key] [from index] [to index]
# 리스트 전체
lrange [key] 0 -1Sets
Redis의 Sets는 순서가 보장되지 않는 Strings의 집합 자료구조입니다. 기본적으로 추가, 삭제, element의 존재 유무 확인 등에 대해서 O(1)의 속도를 보장합니다. 또한 Set이기 때문에 동일한 value는 중복 제거가 됩니다.
- 트래킹에 사용될 수 있습니다. 애플리케이션에 접근한 IP, 세션 리스트를 관리하고자 할 때 중복을 허용하지 않는 Sets 자료구조를 활용할 수 있습니다.
- 게시글의 태그를 표현하기 좋습니다.
- Sets는 Sets간의 합집합, 차집합 등 집합연산을 사용할 수 있습니다.
- Sets의 요소를 랜덤으로 뽑는 spop, srandmember 등의 명령어가 있습니다.
# 이미 존재하면 0, 추가가 완료되면 1 반환
sadd [key] [element]
# 전체 멤버 반환
smembers [key]Sorted Sets
Sorted Sets는 Sets 자료구조에 Score를 추가로 기록하여 score가 낮은순서부터 높은순서대로 정렬되는 자료구조입니다. 동일한 값은 오지 못하며 Score는 동일할 수 있습니다.
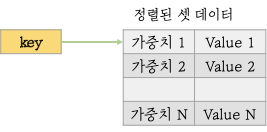
셋 데이터와 동일한 특징을 가지나 저장된 요소에 가중치를 부여하여 작은 값부터 큰 값 정렬을 제공합니다. 단 같은 가중치인 경우는 순서가 변경될 수 있습니다. 가중치에 입력할 수 있는 값은 정수 또는 float 타입입니다.
- 랭킹 리스트를 표현할 때 사용될 수 있습니다. zadd 명령어를 통해 score와 이름을 함께 보내면 쉽고 빠르게 정렬되고 유일한 값을 가지는 자료구조를 만들 수 있습니다. 또한 찾을 때는 zrank, zrange 명령어를 이용할 수 있습니다.
- Sorted Sets는 자주 Redis에 저장된 데이터의 index를 저장하기 위해서 사용되기도 합니다. hashes에 user를 담아둔다고 한다면 이 값을 나이순으로 정렬하던지 할 수 있습니다.
zadd [key] [score] [value]
# 전체 리스트 반환
zrange [key] 0 -1
# 전체 리스트 반환 with score
zrange [key] 0 -1 withscoresHashes
해시는 key-value 구조에서 value에 또다른 key-value Map을 가질 수 있게하는 자료구조입니다.
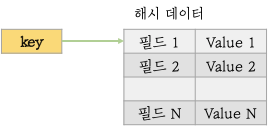
- 해시 데이터에는 2^32-1개의 필드를 저장할 수 있습니다.
hset [hash key] [key] [value]
hget [hash key] [key]
hgetall [hash key]Single Thread
같은 In-Memory DB이면서 NoSQL 데이터베이스인 Memcached와 레디스의 가장 큰 차이점 중 하나는 Redis는 싱글 스레드로 운용이 된다는 점입니다. 싱글 스레드의 강력한 강점은 원자성(Atomic)을 보장합니다.
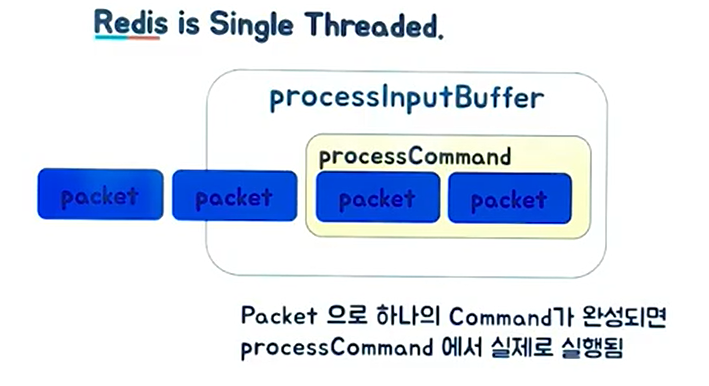
따라서 멀티 스레드를 사용할 때 문제가 되는 Race Condition과 Context Swtiching이 발생하지 않습니다. Race Condition과 Context Switching은 공유되는 자원을 다른 쓰레드 환경에서 동시에 접근할 때 동기화 메커니즘 없이 접근하여 발생하는 문제입니다.
DB를 관리할 때 가장 이슈가 되는 상황이지만, Redis는 싱글 스레드를 기반으로 하기 때문에 기본적인 원자성이 보장이 됩니다.
하지만 싱글 스레드이기 때문에 명령을 수행할 때 시간 복잡도를 필수적으로 고려해야 합니다. 여러 요청이 동시에 들어올 경우 하나의 작업 수행의 시간이 지연될 경우 이후의 요청 역시 지연되기 때문입니다. 따라서 O(N) 연산이 수행되는 명령어를 조심해야 하고 대표적인 명령어는 다음과 같습니다.
O(N) 명령어
- keys
- FLUSHALL, FLUSHDB
- Delete Collections
- Get All Collections
Redis와 Memcached 비교
| Redis | Memcached | |
|---|---|---|
| 스레드 | 싱글 스레드 | 멀티 스레드 |
| 자료 구조 | list, string, hashes, sorted sets, bitmaps 등 | string과 integers 지원 |
| 데이터 저장 | Memory, Disk | Only Memory |
| 처리속도 | Memcached보다 느리지만 큰 차이는 없음. | 디스크를 사용하지 않아 redis보다 빠르다. |
| Replication | 지원 | 지원 안함 |
| Partitioning method | 지원 | 지원 안함 |
| 영속성(Persistence) | 영속성있는 데이터 사용 | 지원 안함 |
- 영속성은 프로그램이 중단되어도 데이터가 살아있는지를 뜻한다.
- 기본적으로 Redis는 In-Memory DB여서 프로그램이 중단되면 데이터가 날라간다.
- 하지만 redis는 일정 시점에 DB의 데이터를 스냅샷으로 저장하고 그동안 기록된 커맨드를 기록하여 이 데이터를 다시 복구하는 기능이 있다.
- RDB, AOF에 대해 알아보면 Redis의 영속성에 대해서 알 수 있다.
- 따라서 설정에 따라 영속성있는 데이터를 활용할 수 있다.
대표적인 실수 사례
- key가 백만개 이상인데 keys사용하는 경우
- scan 명령어로 긴 명령을 짧은 여러번의 명령으로 변경 가능
- 아이템이 몇 만개든 hash, sorted set, set에서 데이터를 가져오는 경우
- 일부만 가져오기
- 큰 collection을 작은 여러 collection으로 나눠서 저장
- Spring security oath RedisTokenStore 이슈
- 최신 버전에서는 set(o(1))로 해결
또한, 자료구조의 시간복잡도를 고려하여 redis를 활용해야지 이슈를 방지할 수 있습니다.
Redis 운영시 주의사항 & 다루지 않은 내용들
- 메모리 파편화
- 가상메모리 Swap
- Replication - fork 문제
- 분산 기법(sharding)
- 쿠팡 레디스 오류
- 카카오 '레디스, 잘못 쓰면 망한다' - 2013
- Pub/Sub
- 루아 스크립트
Redis Tutorial
레디스 튜토리얼 (in web)
우분투 Redis 설치 Command
# 먼저 apt-get을 업데이트 해준다.
$ sudo apt-get update
$ sudo apt-get upgrade
# 아래의 명령어로 설치한다.
$ sudo apt-get install redis-server
# 버전확인
$ redis-server --version
# 이제 redis.conf 파일을 열어서 Redis가 사용할 수 있는 최대 사용 메모리양을 정하고
# 최대 사용 메모리를 초과하게 될때 데이터를 어떻게 삭제할지를 정의할 것이다.
$ sudo nano /etc/redis/redis.conf
# 설정 파일에서 maxmemory와 maxmemory-policy를 찾아서 다음과 같이 바꾼다.
# 최대 사용 메모리양은 1G로 정하고, 최대 사용 메모리를 초과할 시 가장 오래된
# 데이터를 지워서 메모리를 확보하며 가장 최근에 저장된 데이터를 사용하는 것으로 설정한다.
maxmemory 1g
maxmemory-policy allkeys-lru
# 설정이 적용되도록 Redis를 재시작한다.
$ sudo systemctl restart redis-server.service
# Redis의 기본포트는 6379이다. Redis가 6379 포트를 쓰고 있는지 확인한다.
$ netstat -nlpt | grep 6379
redis-cli# set을 사용해서 key - value로 데이터를 입력한다.
set [key] [value]
# get [key]로 데이터 값을 찾아온다
get [key]
# 저장된 key를 검색할 수도 있다
keys *검색어*
# 아래와 같이 전체 key를 조회해보자
keys *
# getrange substring과 유사
getrange [key] [from] [to]
# getrange name 0 4
# mset lang English technology Redis
# mget lang technology
# 만료시간 설정
expire [key] [seconds]
# 만료시간 확인
# -2가 반환되면 만료된 key
ttl [key]
# 등록과 동시에 만료시간 설정
setex [key] [expire-seconds] [value]
# key value 싹다 삭제
flushall
# list push
lpush [key] [value]
lpush [key] [value2]
# list all
lrange country 0 -1
# redis 이미지 저장
# 성능 측정
redis-benchmark
Redis Course - In-Memory Database Tutorial
Reference
