최근 ClickHouse 엔지니어링 블로그에 올라온 아키텍처 진화 관련 글들이 인상 깊어서, 현재 ClickHouse가 클라우드 환경에서 어떤 방향으로 나아가고 있는지 다뤄보았습니다.
최근 ClickHouse가 클라우드 네이티브 환경을 타겟으로 밀고 있는 SharedMergeTree와 Distributed Cache기반의 Stateless 아키텍처 위주로 정리했습니다.
1. ClickHouse 아키텍처의 발전 방향 → Shared-Nothing에서 Stateless로
ClickHouse는 이를 해결하기 위해 실제 데이터를 Object Storage로 완전히 빼버리는 SharedMergeTree 엔진을 도입했습니다. 인프라 관리의 복잡함을 스토리지 쪽으로 넘기고 스케일링을 유연하게 가져가겠다는 의도라 생각됩니다.
또한, 무겁고 비용이 비싼 DB 내부 디스크를 벗어나 비교적 저렴하고 연산상의 성능 이점을 가져갈 좋은 토대가 됩니다.
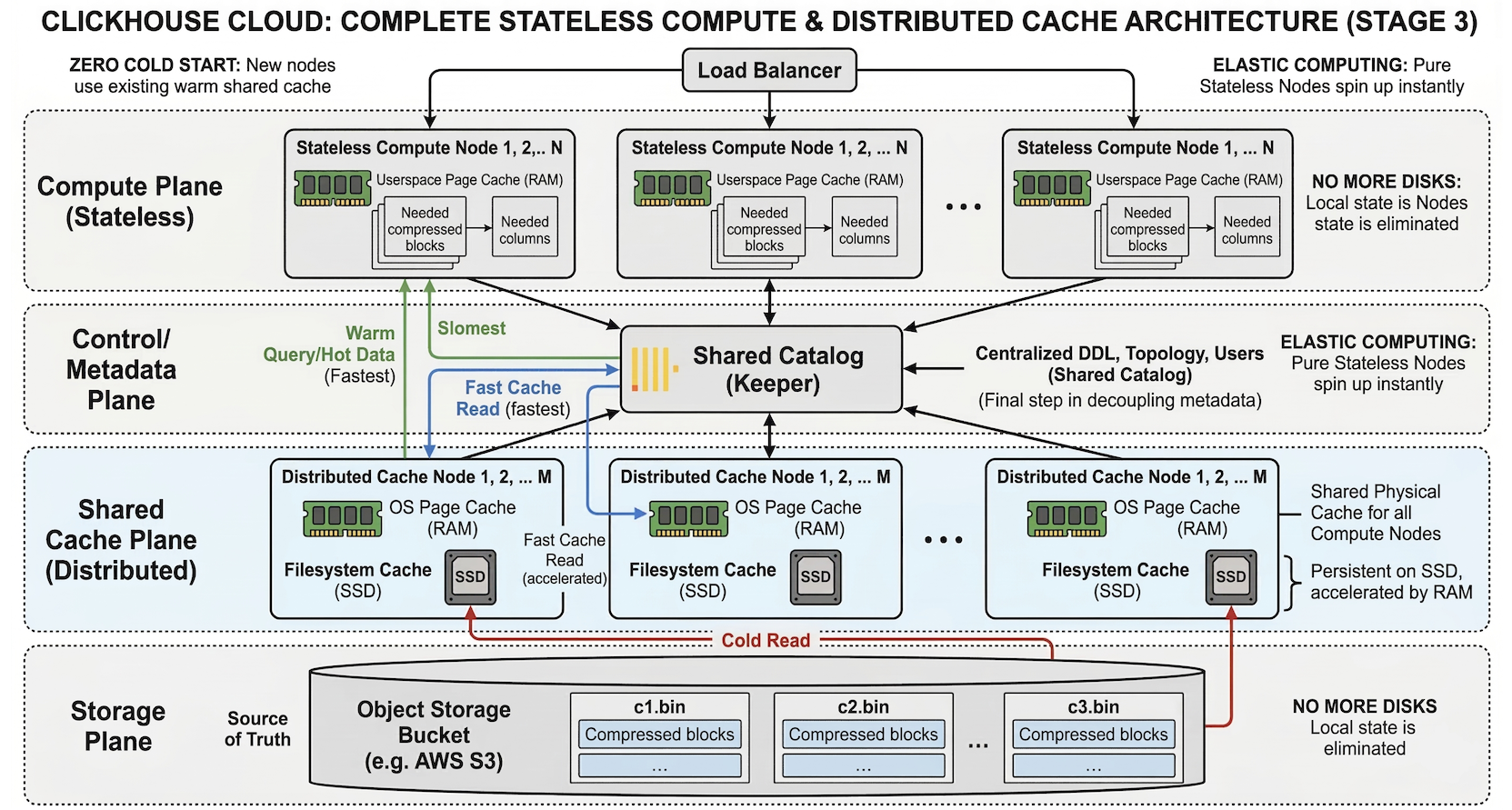
관련해서 최근(2025년 9월)에 올라온 블로그 글(No more disks: the architecture behind stateless compute in ClickHouse Cloud)을 보면, 여기서 데이터뿐만 아니라 메타데이터와 캐시까지 Compute Node에서 완전히 분리해 완벽한 Stateless 구조를 완성하는 쪽으로 진화 중이라는 것을 알 수 있습니다.
2. 성능 트레이드오프 극복 → Distributed Cache 도입
S3를 메인 스토리지로 쓸 때 가장 우려되는 부분은 당연히 로컬 디스크 대비 느린 I/O 속도라고 생각됩니다. 관련해서 어떤식으로 해결했을지 궁금해 clickhouse 블로그를 찾아보니 좋은 글(Building a Distributed Cache for S3)이 있었습니다.
현재 ClickHouse Cloud 공식 문서에 소개된 아키텍처(ClickHouse Cloud Architecture)를 보면, 초기(Stage 2)에는 연산 노드에 로컬 SSD를 달아 이를 캐시로 썼습니다. 하지만 이 방식은 트래픽이 몰려 연산 노드를 스케일 아웃할 때, 새로 뜬 노드들은 캐시가 비어있어 S3에서 데이터를 처음부터 긁어와야 하는 콜드 스타트 문제가 생긴다고 합니다.
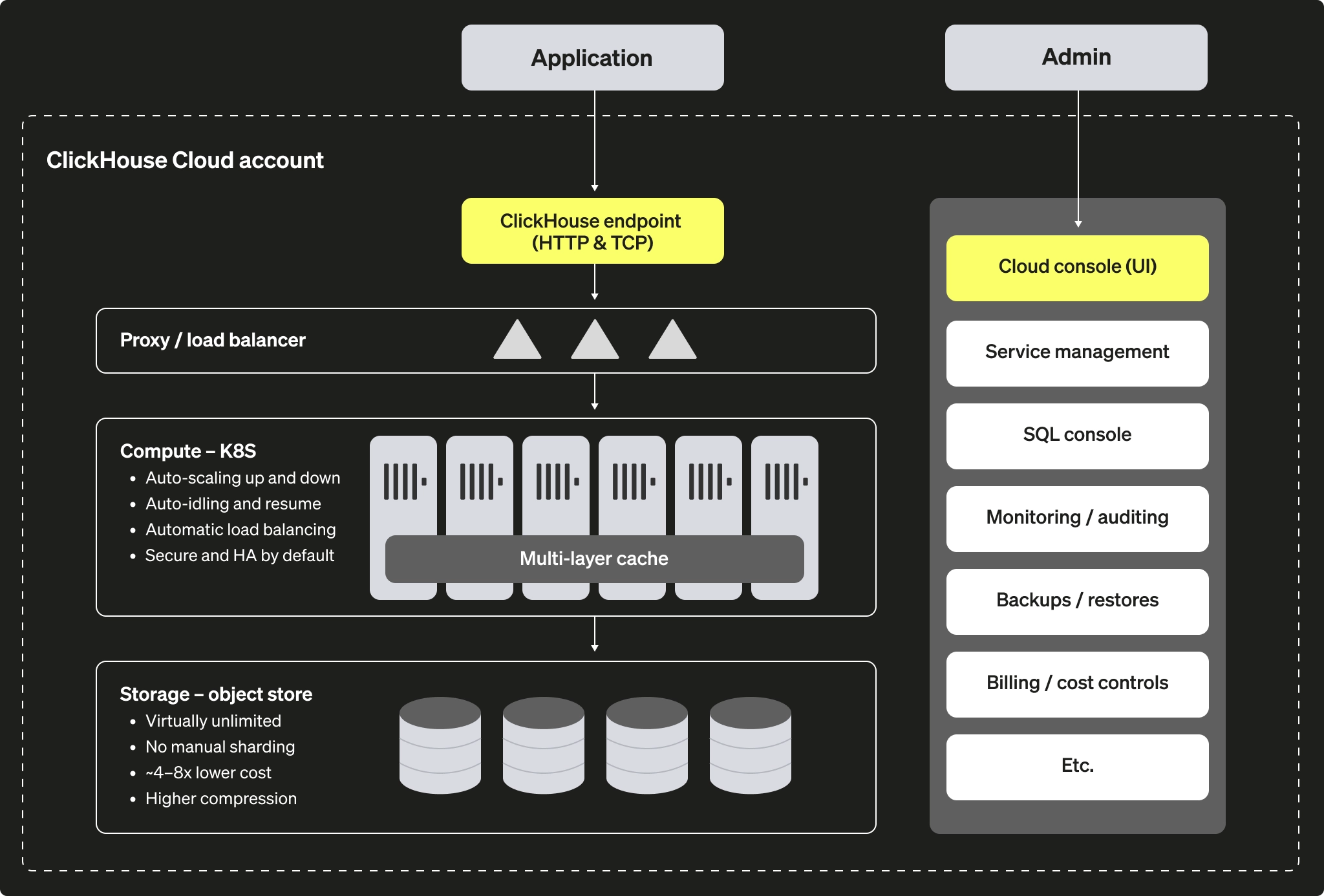
ClickHouse는 최근 이를 극복하기 위해 연산 노드와 S3 사이에 별도의 분산 캐시 노드를 두는 방식(Stage 3)을 도입했습니다. (Distributed Cache for S3 Work Process) 연산 노드가 여러 대로 늘어나더라도 이미 웜업된 상태의 공유 분산 캐시에서 데이터를 병렬로 즉각 가져오기 때문에 기존 로컬 디스크에 준하는 성능을 유지할 수 있게 되었습니다.
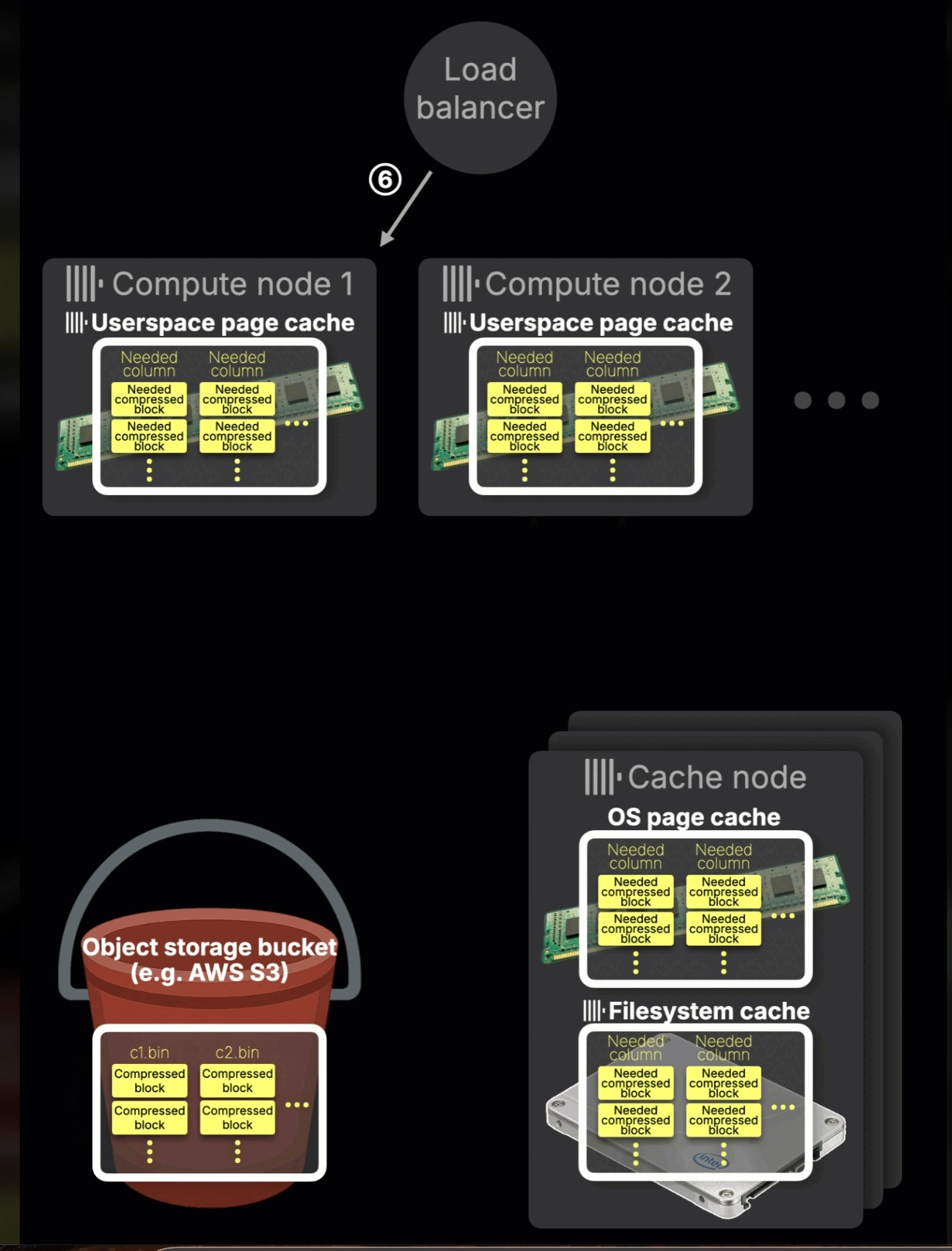
Compute Node에서의 캐시가 OS 캐시가 아닌 Userspace page Cache라고 불리는 이유
과거에는 Compute Node가 자기 로컬 디스크에서 파일을 읽었기 때문에 리눅스 OS가 알아서 메모리에 캐싱을 해줬습니다. 하지만 아키텍처가 진화하면서 Compute Node쪽 디스크를 제거하고 대신 네트워크를 타고 Cache Node에서 데이터를 가져오게 되어 리눅스 OS가 파일로 인식하지 못해 자동으로 캐싱해주지 않습니다. 그래서 Clickhouse 개발진이 소프트웨어적으로 메모리단에서 캐싱을 진행하여 userspace page cache라는 이름이 붙게 되었습니다.
clickhouse 분산캐시 벤치마크
아래 벤치마크는 분산 캐시 기술을 다룬 블로그 글(Benchmarking hot data caching in ClickHouse)에서 나온 분산 캐시가 적용된 환경에서 연산 노드가 확장될 때 S3 병목 없이 성능이 어떻게 유지되는지 보여줍니다.
테스트 대상
- 공유 리소스가 없는 자체 관리형 서버 (SSD 탑재)
- Clickhouse 클라우드와 기존 로컬 파일 시스템 캐싱
- Clickhouse 클라우드에 새로운 분산 파일 시스템 캐싱 (싱글 노드, 초기 워밍업)
- Clickhouse 클라우드에 새로운 분산 파일 시스템 캐싱 (싱글 노드, 후속 노드)
- Clickhouse 클라우드에 새로운 분산 파일 시스템 캐싱 (6개 병렬 노드)
테스트 1: 처리량 테스트 - 전체 테이블 스캔
모든 압축된 열을 대상으로 하기 때문에 E2E 캐시 처리량 테스트에 적합한 쿼리로 테스트 진행
SELECT count() FROM amazon.amazon_reviews WHERE NOT ignore(*);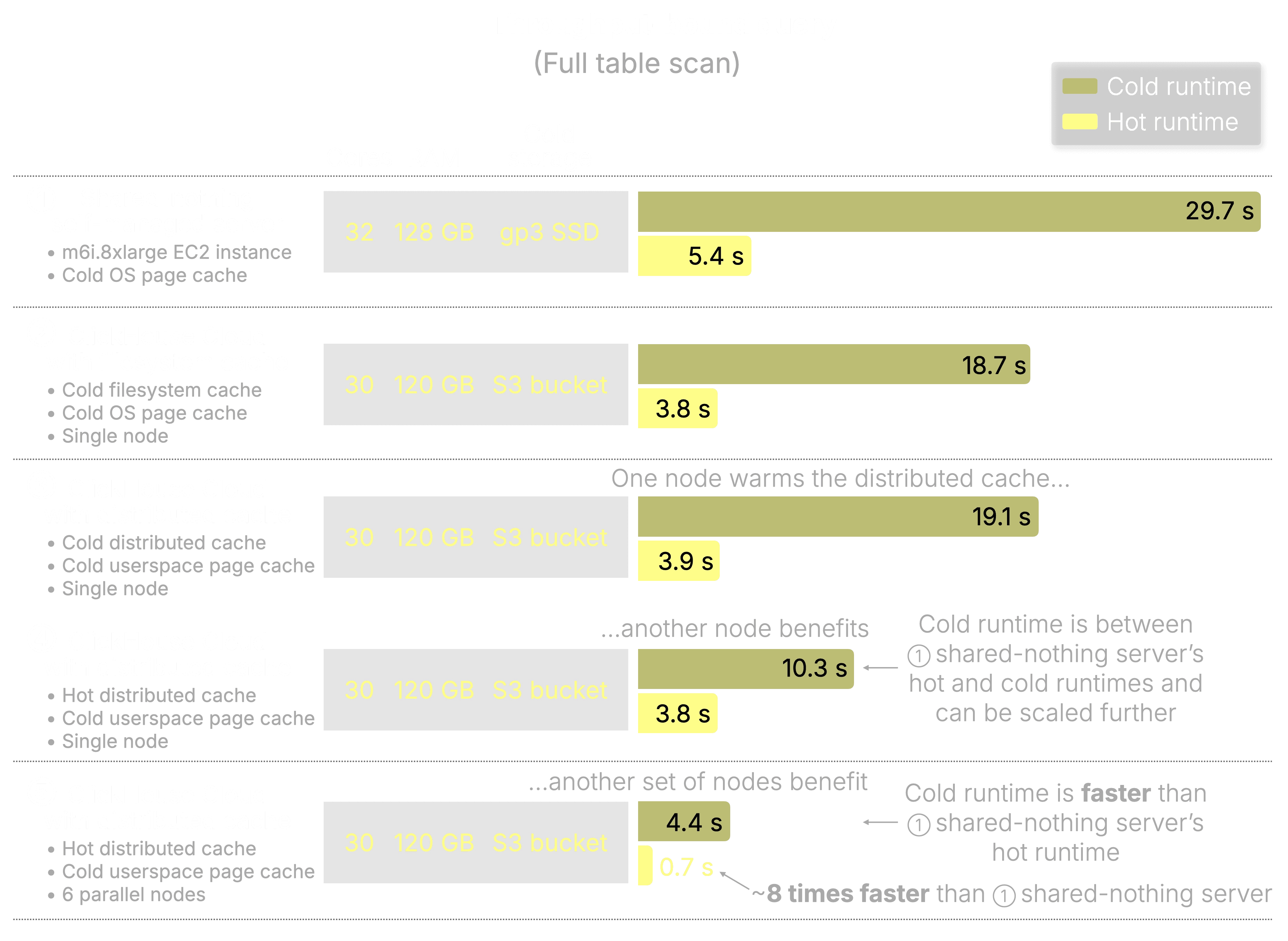
공유 분산 캐시와 병렬 컴퓨팅 노드를 결합하면 콜드 스타트시에도 로컬 SSD를 능가하는 속도가 나옵니다.
테스트 2: 지연시간 테스트 - 분산읽기
쿼리 크기가 작아질수록 처리량이 아닌 지연 시간이 병목 현상 → 분산되고 서로 관련없는 읽기를 사용하는 쿼리를 날려 테스트 진행
SELECT * FROM amazon.amazon_reviews WHERE review_date in ['1995-06-24', '2015-06-24', …] FORMAT Null;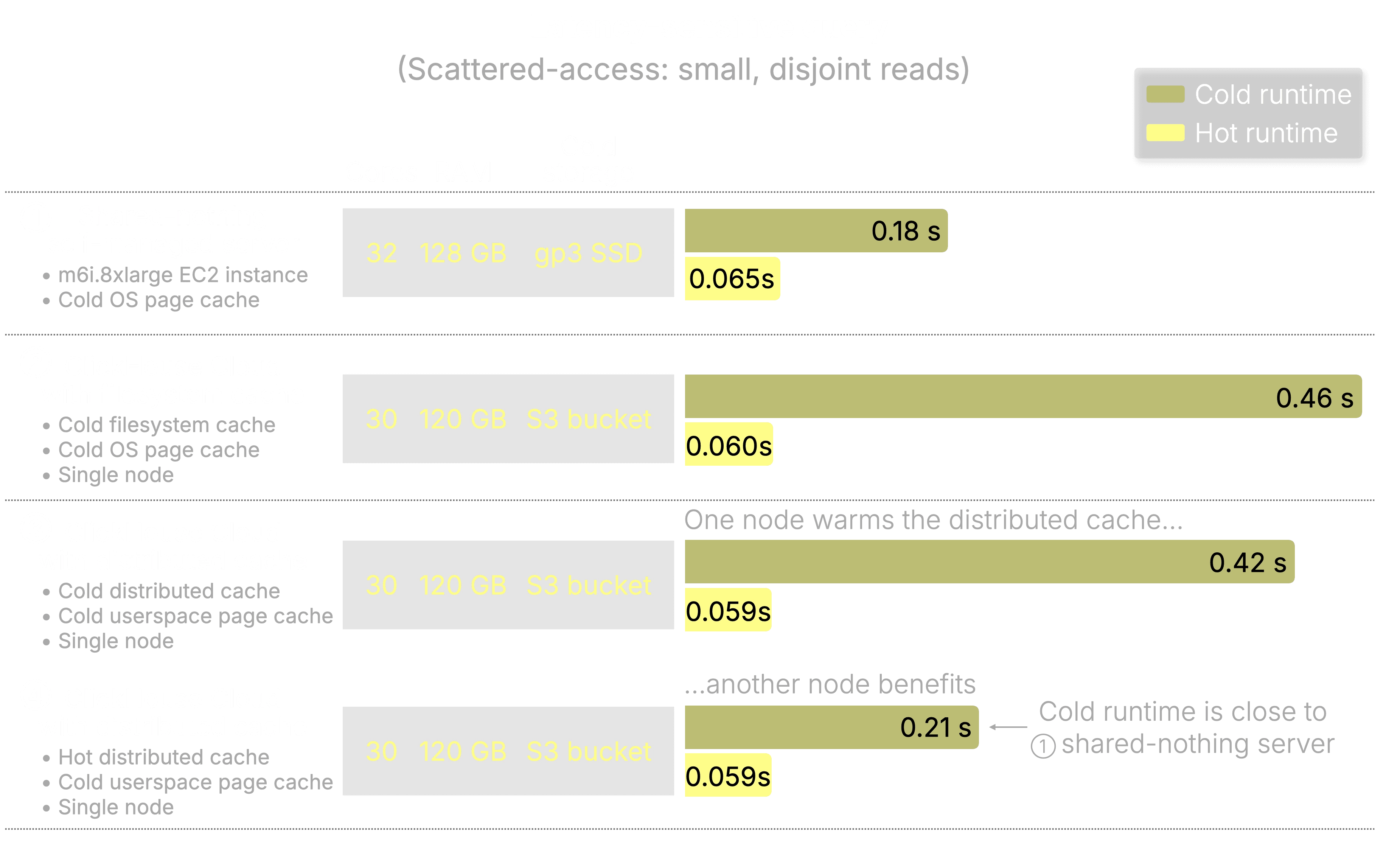
위의 처리량 벤치마크에서는 멀티스레드 읽기 덕분에 ClickHouse Cloud가 S3에서 데이터를 읽음에도 불구하고 SSD 기반 서버보다 우수한 성능을 보였지만, 여기서는 그러한 이점이 사라집니다. 작고 분산된 읽기 작업의 경우, I/O 스레드에 효율적으로 분산시킬 만큼 충분한 데이터가 없는 경우가 많습니다. 읽기 작업이 병렬로 실행되더라도 쿼리 성능은 결국 가장 느린 개별 읽기 작업에 의해 제한됩니다. 이 경우 대역폭이 아닌 레이턴시가 병목 현상이 되어 S3가 SSD보다 느려지는 것입니다.
결론
모든 컴퓨팅 노드는 객체 스토리지보다 훨씬 낮은 지연 시간으로 분산 캐시에서 캐시된 데이터를 가져올 수 있으며, 콜드 스타트 시 스토리지에서 다시 다운로드할 필요가 없습니다.
한 노드에서 수행된 작업은 다른 모든 노드에도 성능상 이점을 줍니다.
데이터를 로컬에 저장하거나 재시작 후 캐시를 재구축할 필요가 없습니다.
처리량 : 전체 테이블 스캔에서 콜드 쿼리는 컴퓨팅 노드 간 공유 캐싱 및 병렬 페치 덕분에 자체 관리형 SSD 설정보다 최대 4배 빠르게 실행되었습니다.
지연 시간 : 소규모 분산 읽기 작업의 경우, 콜드 쿼리는 SSD 성능과 동일했으며, 핫 쿼리는 60ms 미만의 메모리 속도 지연 시간을 기록했습니다. 이 모든 결과는 로컬 스토리지 없이 달성되었습니다.
3. 흥미로운점
앞서 설명한 완벽한 Stateless 구조와 분산 캐시 기술(Stage 3)은 오픈소스에 공개되지 않고 오직 자사 SaaS인 ClickHouse Cloud 환경에서만 프라이빗하게 제공되는 핵심 경쟁력이라고 합니다.
클라우드 인프라 위에서 오픈소스 ClickHouse를 서비스할 때, 유연한 확장성과 성능을 동시에 잡기 위해 어떤 식의 아키텍처 고민을 clickhouse 엔지니어들이 하였는지 보여주는 사례라고 생각합니다. 클라우드 환경에서 Managed ClickHouse를 제공할 때 S3 Object Storage와 Compute Node 사이에 독자적인 캐싱 레이어를 구성해보는 등의 방식으로 접근해보아도 괜찮을 것 같습니다.
현재의 Clickhouse Cloud Stage 3 예상 아키텍처
주요 특징
Keeper를 통한 메타데이터 공유로 Compute plane의 stateless화
Object Storage와 Compute 사이의 분산 캐시 도입으로 SharedMergeTree 방식에서의 성능 개선