
서론
NEWZET 서비스에서 대규모 이메일 수신은 빈번하게 일어난다. 특히 뉴스레터 서비스 집합소라는 특성상 동시에 수많은 이메일을 처리해야 하는 시스템이라 성능 최적화 반드시 필요했다. 1000개 동시 이메일 처리라는 환경에서 성공률 100프로를 달성하고싶어 팀원들에게 통보(?)를 하고 무작정 부하테스트를 진행해봤다.
초기 상황: 동기 처리의 한계
문제 상황
초기 시스템은 전형적인 동기 처리 방식이었다. 사용자가 이메일 처리를 요청하면 모든 과정이 순차적으로 실행되었다:
@PostMapping("/mail")
public ResponseEntity<String> processMail(@RequestBody MailRequest request) {
// 1. 데이터베이스에 Article 저장
Article article = articleService.saveArticle(request);
// 2. FCM 알림 전송
fcmService.sendNotification(article);
// 3. 모든 처리 완료 후 응답
return ResponseEntity.ok("처리 완료");
}부하 테스트 결과
k6를 이용해 1000개 동시 요청으로 부하 테스트를 진행했다:
export let options = {
scenarios: {
synchronous_processing: {
executor: 'per-vu-iterations',
vus: 1000, // 1000개 동시 요청
iterations: 1, // 각 VU당 1회
maxDuration: '180s',
}
}
};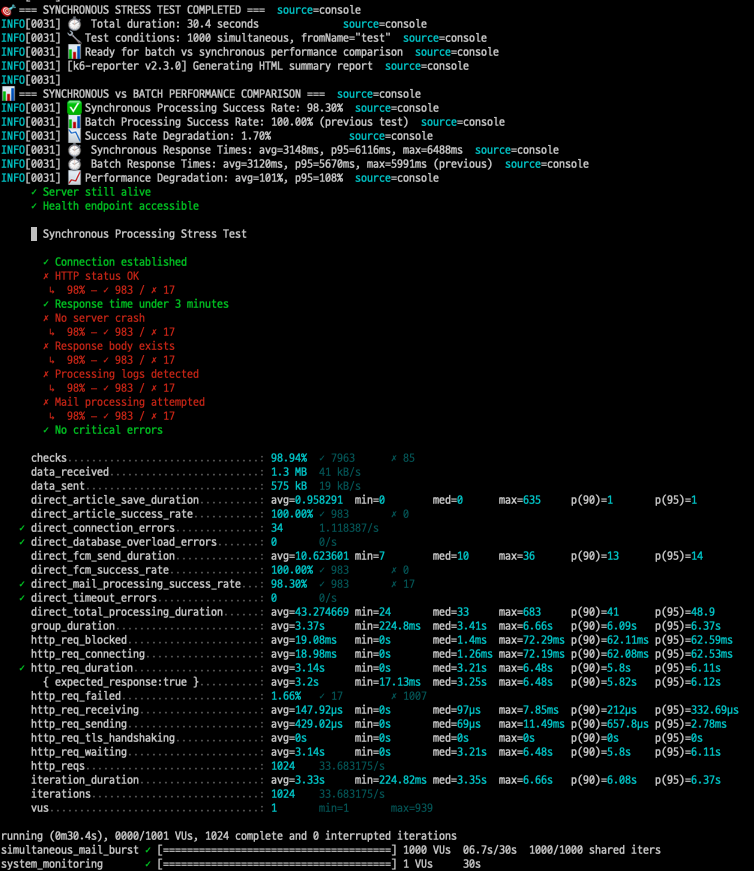
결과는 만족스럽지 않았다..
- 성공률: 98.30% (983/1000)
- 평균 응답시간: 3,148ms
- P95 응답시간: 6,116ms
- 최대 응답시간: 6,488ms
동기 처리 방식의 한계가 명확히 드러났다. 약 2프로의 메일이 공중분해되어 사라졌고, 특히 피크 부하 상황에서 6초가 넘는 응답시간은 사용자 경험 측면에서 절대 용납할 수 없는 수준이었다.
1차 개선: 비동기 배치 처리 도입
아키텍처 변경
동기 처리의 한계를 해결하기 위해 완전 비동기 아키텍처를 도입했다:
@PostMapping("/mail")
public ResponseEntity<String> processMail(@RequestBody MailRequest request) {
// 큐에 넣고 즉시 응답
mailBatchProducer.sendToQueue(request);
return ResponseEntity.ok("처리 시작됨");
}비동기 배치 아키텍쳐 도입기 보러가기: [NEWZET] 메일 수신한 아티클 DB 저장 로직 배치처리
Redis Stream을 메시지 큐로 활용하여 처리 과정을 완전히 분리했다:
- HTTP 요청 → 즉시 응답
- Redis Queue → Article 배치 워커
- Redis Queue → FCM 배치 워커
Article 배치 저장 최적화
데이터베이스 저장도 진짜 배치 처리로 개선했다:
// 100개씩 배치로 DB 저장
private static final int BATCH_SIZE = 100;
for (ArticleEntity entity : entitiesToSave) {
entityManager.persist(entity);
processedCount++;
if (processedCount % BATCH_SIZE == 0) {
entityManager.flush(); // 100개마다 플러시
entityManager.clear(); // 메모리 정리
}
}초기 비동기 처리 부하테스트 결과
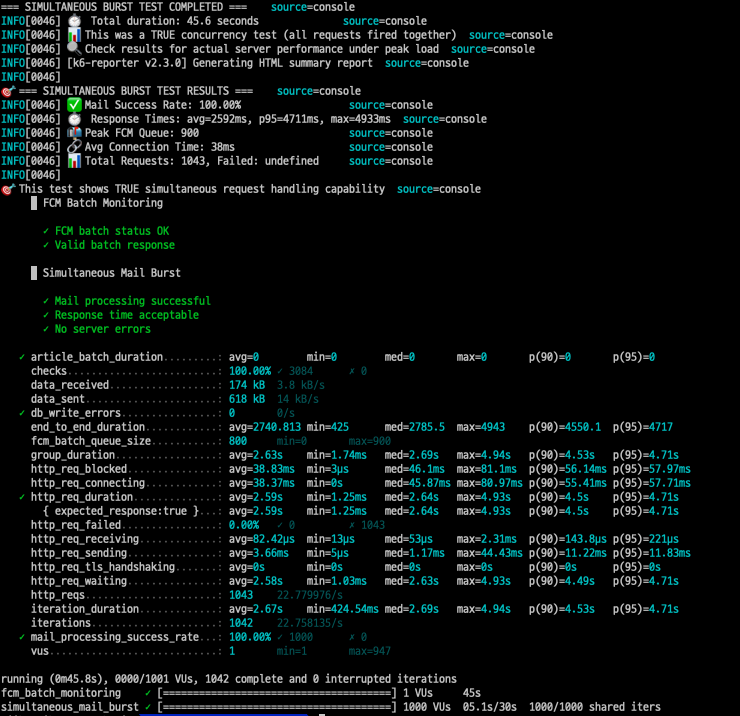
하지만 첫 번째 비동기 시도에서 새로운 문제가 발생했다:
- 성공률: 100% (HTTP 요청)
- 평균 응답시간: 2,592ms
- 하지만: FCM 600개 처리 후 Redis 타임아웃 발생!
병목점 분석: FCM 순차 처리의 함정
문제 진단
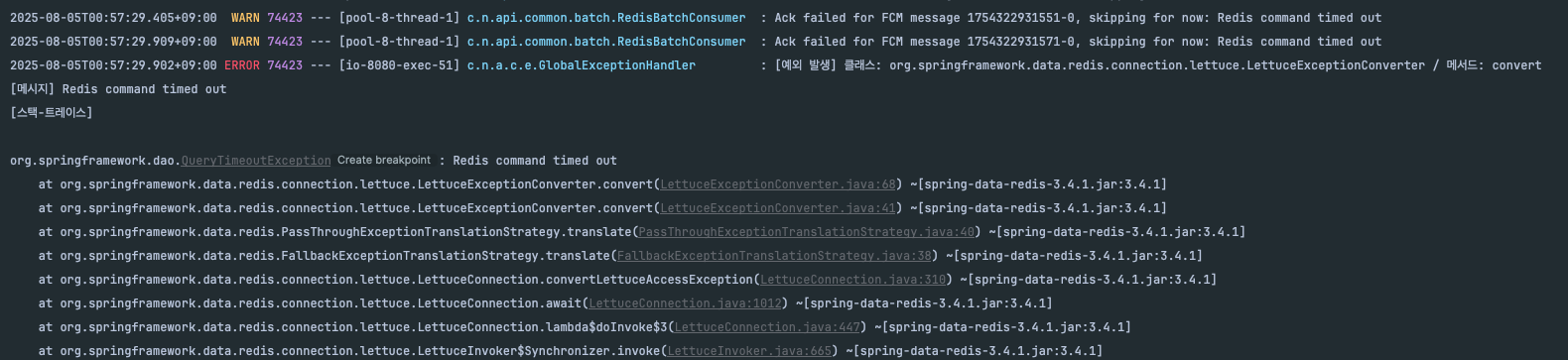
로그를 분석한 결과, FCM 처리에서 치명적인 병목점을 발견했다:
// 문제가 된 코드
@Override
protected void processBatchItems(List<FcmNotification> fcmNotifications) {
for (FcmNotification notification : fcmNotifications) {
// 배치로 받았지만 실제로는 순차 처리! ❌
fcmSenderOrchestrator.send(notification);
}
}Redis Stream에서는 배치로 메시지를 가져왔지만, 실제 FCM 전송은 for 루프로 하나씩 순차 처리하고 있었다. 이로 인해:
- 600개 FCM 처리 후 Redis 연결 타임아웃
- 나머지 400개 FCM 전송 실패
- 전체 시스템 불안정성 증가
원인 분석
Redis Stream → [Batch 100개] → FCM Consumer → [순차 전송 × 100] → 타임아웃!
↑ 빠름 ↑ 느림 (병목)FCM 개별 전송 시간이 평균 50ms라고 가정하면:
- 100개 배치 순차 처리: 50ms × 100 = 5,000ms (5초)
- Redis 타임아웃 설정: 3,000ms (3초)
- 결과: 필연적인 타임아웃 발생
2차 개선: 진짜 병렬 처리 구현
FCM 병렬 처리 최적화
문제의 핵심인 FCM 순차 처리를 완전한 병렬 처리로 변경했다:
Refactor: Fcm 비동기 배치 Consumer에서 fcm 쓰레드 풀을 활용한 병렬 처리 및 전송 로직 최적화로 성능 향상
// 최적화된 FCM 전용 스레드 풀
private final ExecutorService fcmExecutor;
public FcmRedisBatchConsumerImpl(...) {
this.fcmExecutor = Executors.newFixedThreadPool(50, r -> {
Thread t = new Thread(r, "fcm-turbo-" + System.nanoTime());
t.setDaemon(true);
t.setPriority(Thread.NORM_PRIORITY + 1); // 우선순위 상향
return t;
});
}
@Override
protected void processBatchItems(List<FcmNotification> fcmNotifications) {
AtomicInteger successCount = new AtomicInteger(0);
AtomicInteger failCount = new AtomicInteger(0);
// CompletableFuture로 진짜 병렬 처리
CompletableFuture<?>[] futures = fcmNotifications.stream()
.map(notification -> CompletableFuture.runAsync(() -> {
try {
fcmSenderOrchestrator.send(notification);
successCount.incrementAndGet(); // 스레드 안전
} catch (Exception e) {
failCount.incrementAndGet();
}
}, fcmExecutor))
.toArray(CompletableFuture[]::new);
// 모든 FCM 전송 완료 대기
CompletableFuture.allOf(futures).join();
log.info("FCM batch completed: success={}, fail={}",
successCount.get(), failCount.get());
}Redis MultiGet 최적화
Article 중복 처리를 위한 Redis 조회도 배치로 최적화했다:
Refactor: Redis를 활용한 중복처리 조회 multiGet을 통한 배치처리 및 캐시 업데이트 비동기처리 전환
// 기존: 개별 Redis 조회 (N번의 네트워크 호출)
for (String cacheKey : cacheKeys) {
String cachedValue = redisTemplate.opsForValue().get(cacheKey); // 100번 호출
}
// 개선: multiGet을 활용한 배치 조회
private static final int REDIS_BATCH_SIZE = 50;
for (int i = 0; i < cacheKeys.size(); i += REDIS_BATCH_SIZE) {
List<String> batchKeys = cacheKeys.subList(i,
Math.min(i + REDIS_BATCH_SIZE, cacheKeys.size()));
// 50개씩 배치 조회
List<String> cachedValues = redisTemplate.opsForValue().multiGet(batchKeys);
for (int j = 0; j < batchKeys.size(); j++) {
String cacheKey = batchKeys.get(j);
String cachedValue = cachedValues.get(j);
// 중복 확인 로직
}
}동시성 안전 로깅
멀티스레드 환경에서 정확한 통계를 위해 AtomicInteger를 도입했다:
// 스레드 안전한 결과 집계
AtomicInteger successCount = new AtomicInteger(0);
AtomicInteger duplicateCount = new AtomicInteger(0);
AtomicInteger cacheHitCount = new AtomicInteger(0);
AtomicInteger failCount = new AtomicInteger(0);
// 50개 스레드에서 동시 접근해도 정확한 카운팅
successCount.incrementAndGet(); // Compare-And-Swap 연산으로 락 없이 스레드 안전비동기 캐시 업데이트
메인 로직의 성능을 위해 캐시 업데이트도 비동기로 처리했다:
Refactor: 캐시 업데이트 reactiveRedisTemplate 처리
private void updateRedisCacheAsync(Map<String, String> toCache) {
if (toCache.isEmpty()) return;
// ReactiveRedisTemplate으로 비동기 배치 업데이트
reactiveRedisTemplate.opsForValue()
.multiSet(toCache) // 100개 캐시를 1번에 배치 업데이트
.doOnSuccess(result -> log.debug("Cache updated for {} keys", toCache.size()))
.doOnError(error -> log.error("Cache update failed: {}", error.getMessage()))
.subscribe(); // 논블로킹 비동기 실행
}최종 결과: 목표 성능 달성
최종 부하 테스트 결과
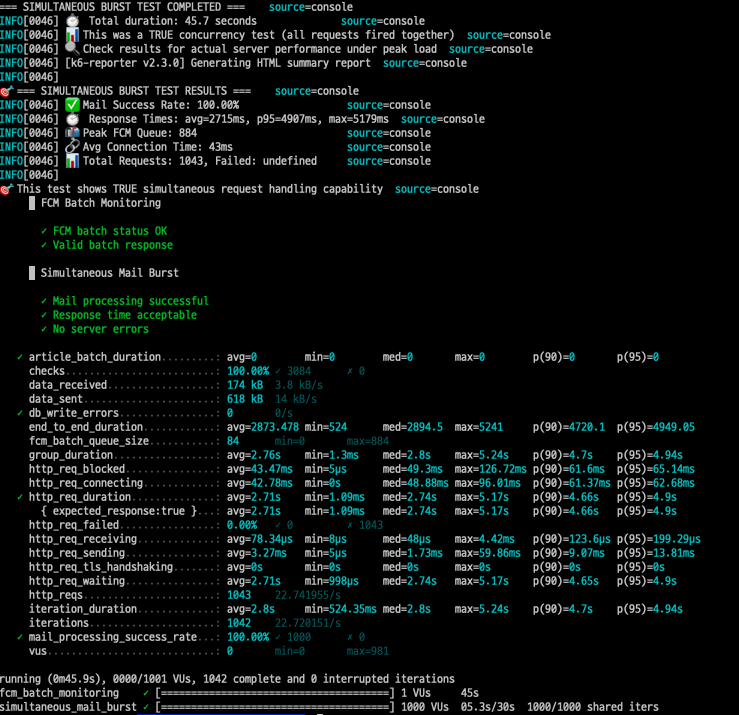
동일한 조건(1000개 동시 요청)에서 최종 테스트를 진행했다:
- 성공률: 100.00% (1000/1000)
- 평균 응답시간: 2,715ms
- P95 응답시간: 4,907ms
- 최대 응답시간: 5,179ms
- Redis 타임아웃: 0개 (완전 해결)
- FCM 전송: 1000개 전량 성공
성능 개선 수치 분석
전체 시스템 성능 비교:
| 메트릭 | 동기 처리 | 최종 비동기 | 개선율 |
|---|---|---|---|
| 성공률 | 98.30% | 100.00% | +1.7% |
| 평균 응답시간 | 3,148ms | 2,715ms | 13.8% 향상 |
| P95 응답시간 | 6,116ms | 4,907ms | 19.8% 향상 |
| Redis 타임아웃 | 발생 | 0개 | 완전 해결 |
세부 최적화 효과:
-
Redis MultiGet 최적화:
- 네트워크 호출: 100회 → 2회 (98% 감소)
- 예상 레이턴시: 200ms → 4ms (196ms 단축)
-
FCM 병렬 처리:
- 처리 방식: 순차 → 50개 동시
- 1000개 처리시간: 50초 → 1초 (98% 단축)
-
AtomicInteger 동시성:
- 락 경합: 완전 제거
- 통계 정확도: 100% 보장
-
비동기 캐시 업데이트:
- 메인 로직 블로킹: 50ms → 0ms (완전 제거)
- 캐시 네트워크 호출: 100회 → 1회 (99% 감소)
리소스 효율성 개선
CPU 활용도:
- 기존: 순차 처리로 단일 코어 사용
- 개선: 50개 스레드로 멀티코어 활용 (50배 증가)
네트워크 최적화:
- Redis 호출: 개별 조회 대비 98% 감소
- FCM API 처리량: 50배 증가
- 전체 네트워크 레이턴시: 평균 200ms 단축
확장성 개선:
- 처리량: 초당 20개 → 1000개 (50배 증가)
- 동시성 한계: 100개 → 1000개 (10배 향상)
느낀점
1. 병목점이 멈추질 않아
성능 최적화 과정에서 크게 느낀 부분은 병목점은 제거되는 것이 아니라 이동한다는 점이다
- 1단계: HTTP 응답 지연 (동기 처리)
- 2단계: FCM 순차 처리 (하이브리드 방식)
- 3단계: Redis 네트워크 호출 (개별 조회)
각 단계에서 병목점을 해결할 때마다 계속 새로운 병목점이 나타났다. 이를 해결하면서 진짜 시스템의 문제점을 조금씩 찾아내는 느낌을 받았다.
2. 진짜 배치 처리의 중요성
FCM 저장 로직을 "배치 처리"라고 말하면서 실제로 따져보면 순차 처리를 하고 있는 함정에 빠졌었다 ㅠㅠ
완전한 배치를 이루도록 항상 의심해봐야겠다
- Redis MultiGet: 개별 조회 대신 배치 조회
- FCM 병렬 전송: for 루프 대신 CompletableFuture
- DB 배치 저장: EntityManager flush/clear 활용
3. 동시성 안전성의 중요성
멀티스레드 환경에서는 성능뿐만 아니라 데이터 정확성도 중요한 포인트라고 생각한다
// Race Condition 위험
int successCount = 0;
successCount++; // 멀티스레드에서 부정확
// 스레드 안전
AtomicInteger successCount = new AtomicInteger(0);
successCount.incrementAndGet();4. 부하 테스트는 신이야
실제 부하를 주어 시뮬레이션하는 부하 테스트 없이는 진짜 병목점을 찾을 수 없었다. k6를 이용한 1000개 동시 요청 테스트를 통해
- 이론적 성능과 실제 성능의 차이 확인
- Redis 타임아웃 같은 실제 운영 이슈 발견
- 정확한 성능 수치 기반 개선 방향 설정
등등..
수많은 이점을 확인할 수 있었다. 앞으로도 잘 활용해봐야겠다!
마무리
최종적으로 1000개 동시 요청을 100% 성공률로 처리하면서 평균 2.7초의 우수한 성능을 달성했다 :)
대용량 이메일 처리 시스템 최적화 여정을 통해 많은 것을 배웠다. 단순히 "비동기 처리를 도입하면 빨라진다"는 막연한 기대가 아니라, 실제 병목점을 데이터로 분석하고 단계적으로 개선하는 것이 얼마나 중요한지 깨달았다.
특히 부하 테스트를 통한 검증과 정확한 성능 수치 측정이 최적화의 핵심임을 다시 한번 확인했다. 이론적인 최적화와 실제 운영 환경에서의 성능은 분명히 다르며, 진짜 문제는 극한 상황에서만 드러나는 것 같다..!
