
문제 상황
최근 진행 중인 [DDIP: 일상의 순간을 돈으로] 프로젝트에서 DdipEvent 도메인을 구현하면서 성능 이슈에 직면했다. DdipEventEntity가 PhotoEntity와 InteractionEntity와 각각 1:N 관계를 맺고 있는 상황에서 발생한 N+1 문제와 그 해결 과정을 공유하고자 한다.
엔티티 구조
먼저 문제가 발생한 엔티티 구조를 살펴보자.
@Entity
@Table(name = "ddip_event")
public class DdipEventEntity {
// ... 기본 필드들
@OneToMany(mappedBy = "ddipEvent", cascade = CascadeType.ALL,
orphanRemoval = true, fetch = FetchType.LAZY)
private List<PhotoEntity> photos;
@OneToMany(mappedBy = "ddipEvent", cascade = CascadeType.ALL,
orphanRemoval = true, fetch = FetchType.LAZY)
private List<InteractionEntity> interactions;
}EAGER Loading을 선택하지 않은 이유
처음에는 FetchType.EAGER를 고려했지만, 다음과 같은 이유로 적용하지 않았다:
1. 메모리 부족 위험
- 불필요한 데이터까지 모두 메모리에 로드하여 OutOfMemory 발생 가능
- 특히 대용량 데이터 처리 시 심각한 성능 저하
2. 과도한 리소스 점유
- 모든 연관 엔티티를 항상 로드하여 불필요한 DB 커넥션 점유
- 네트워크 대역폭 낭비
3. 성능 예측의 어려움
- 어떤 쿼리가 실행될지 예측하기 어려움
- 연관 관계가 복잡할수록 예상치 못한 성능 이슈 발생
4. Cartesian Product 문제
- 여러 컬렉션을 EAGER로 로드할 때 데이터 중복 발생
- 실제 필요한 데이터보다 훨씬 많은 데이터 전송
N+1 문제 발생
LAZY Loading을 적용했지만, Repository에서 데이터 조회 시 전형적인 N+1 문제가 발생했다:
// 1개의 쿼리로 DdipEvent 목록 조회
List<DdipEventEntity> events = ddipEventJpaRepository.findAll();
// 각 event마다 photos와 interactions 조회 (N번의 추가 쿼리)
for (DdipEventEntity event : events) {
event.getPhotos().size(); // 추가 쿼리 발생
event.getInteractions().size(); // 추가 쿼리 발생
}결과적으로 1 + (N × 2)개의 쿼리가 실행되는 상황이 발생했다.
첫 번째 시도: EntityGraph
N+1 문제를 해결하기 위해 @EntityGraph를 적용해봤다:
public interface DdipEventJpaRepository extends JpaRepository<DdipEventEntity, UUID> {
@EntityGraph(attributePaths = {"photos", "interactions"})
List<DdipEventEntity> findAllWithAssociations();
}하지만 실행 시 다음과 같은 오류가 발생했다:
org.hibernate.loader.MultipleBagFetchException:
cannot simultaneously fetch multiple bagsMultipleBagFetchException 분석
이 오류는 두 개 이상의 List 타입 컬렉션을 동시에 fetch join할 때 발생한다.
발생 원리
- Hibernate는 컬렉션을 "Bag"이라는 자료구조로 관리
- 여러 Bag을 동시에 fetch하면 Cartesian Product로 인한 데이터 중복 발생
- 어떤 데이터가 어떤 컬렉션에 속하는지 구분이 어려워짐
일반적인 해결 방법들
Set사용: 중복 제거되지만 순서 보장 안됨@OrderColumn+List: 성능 이슈 존재- 별도 쿼리로 분리: 여전히 여러 쿼리 실행
하지만 우리 프로젝트에서는 순서가 중요하고 중복이 발생할 수 있어 List를 유지해야 했다.
최종 해결책: Batch Loading
고민 끝에 Batch Loading을 적용하기로 결정했다.
Batch Loading 설정 - 방법 1
@Entity
@Table(name = "ddip_event")
public class DdipEventEntity {
@BatchSize(size = 1000)
@OneToMany(mappedBy = "ddipEvent", cascade = CascadeType.ALL,
orphanRemoval = true, fetch = FetchType.LAZY)
private List<PhotoEntity> photos;
@BatchSize(size = 1000)
@OneToMany(mappedBy = "ddipEvent", cascade = CascadeType.ALL,
orphanRemoval = true, fetch = FetchType.LAZY)
private List<InteractionEntity> interactions;
}Batch Loading 설정 - 방법 2
spring.jpa.properties.hibernate.default_batch_fetch_size=1000방법1은 엔티티단에 정의하여 개별 배치 사이즈를 지정해주는 방식이고,
방법2는 properties 등 설정파일에 적용하여 공통적으로 JPA/Hibernate단에 전역 설정으로 적용
하는 방식이다.
해당 프로젝트에서는 전역적으로 사용할 예정이라 방법2 를 사용했다!
동작 원리
Batch Loading은 다음과 같이 작동한다:
-- 1. DdipEvent 조회
SELECT * FROM ddip_event WHERE ...
-- 2. Photos 배치 조회 (IN 절 사용)
SELECT * FROM photo_entity WHERE ddip_event_id IN (?, ?, ?, ..., ?)
-- 3. Interactions 배치 조회 (IN 절 사용)
SELECT * FROM interaction_entity WHERE ddip_event_id IN (?, ?, ?, ..., ?)성능 테스트 결과
실제 테스트를 통해 성능 개선 효과를 확인했다.
테스트 환경
- DdipEvent: 1,000개
- 각 Event당 Photos: 3개
- 각 Event당 Interactions: 5개
- 배치 사이즈: 1000
테스트 환경에 맞게 미리 데이터를 생성해두고, k6를 통한 부하테스트를 진행하였다.
100개, 300개, 600개, 1000개의 DdipEvent를 조회하고 연관된 Photos와 Interactions를 조회하는 과정을 각각 10번씩 수행하여 수치를 파악했다.
Before (N+1 문제)
데이터가 증가할수록 지수적으로 늘어나는 실행 시간
- 100개 조회시
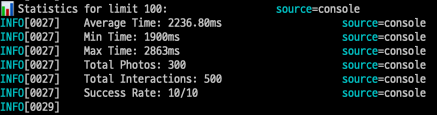
실행된 쿼리 수: 1 + (100 × 2) = 201개
최소 실행시간: 1900ms
최대 실행시간: 2863ms
평균 실행시간: 2236.80ms- 300개 조회시
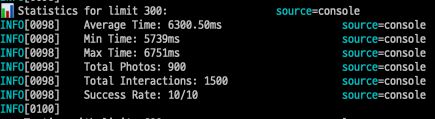
실행된 쿼리 수: 1 + (300 × 2) = 601개
최소 실행시간: 5739ms
최대 실행시간: 6751ms
평균 실행시간: 6300.50ms- 600개 조회시
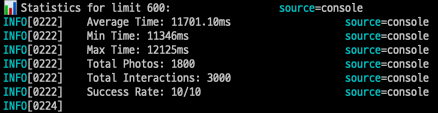
실행된 쿼리 수: 1 + (600 × 2) = 1,201개
최소 실행시간: 11346ms
최대 실행시간: 12125ms
평균 실행시간: 11701.10ms- 1000개 조회시
실행된 쿼리 수: 1 + (1,000 × 2) = 2,001개
최소 실행시간: 19140ms
최대 실행시간: 20828ms
평균 실행시간: 19810.50ms⚠️ N+1 문제의 심각성: 데이터가 10배 증가하면 실행 시간도 거의 10배 증가하는 선형적 성능 저하를 보인다. 특히 1000개 조회 시 거의 20초라는 치명적인 응답 시간을 보여준다.
After (Batch Loading)
데이터 양과 관계없이 일정한 성능을 보이는 최적화
- 100개 조회시
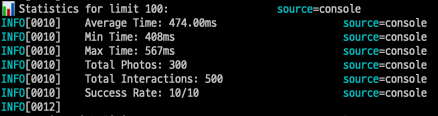
실행된 쿼리 수: 1 + 2 = 3개
최소 실행시간: 408ms
최대 실행시간: 567ms
평균 실행시간: 474.00ms- 300개 조회시
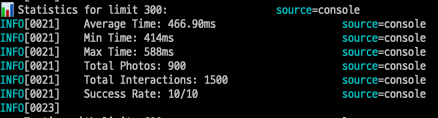
실행된 쿼리 수: 1 + 2 = 3개
최소 실행시간: 414ms
최대 실행시간: 588ms
평균 실행시간: 466.90ms- 600개 조회시
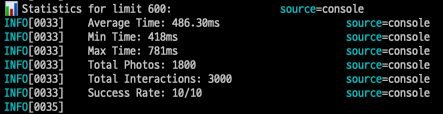
실행된 쿼리 수: 1 + 2 = 3개
최소 실행시간: 418ms
최대 실행시간: 781ms
평균 실행시간: 486.30ms- 1000개 조회시
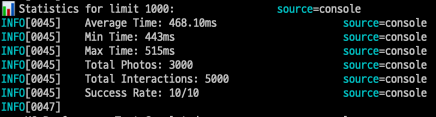
실행된 쿼리 수: 1 + 2 = 3개
최소 실행시간: 443ms
최대 실행시간: 515ms
평균 실행시간: 468.10ms배치 로딩의 효과: 데이터가 10배 증가해도 실행 시간은 거의 동일하다. 모든 경우에서 500ms 이내의 일관된 성능을 보여준다.
성능 개선 효과
| 데이터 수 | Before (N+1) | After (Batch) | 개선율 | 시간 단축 |
|---|---|---|---|---|
| 100개 | 2,237ms | 474ms | 78.8% | 1,763ms |
| 300개 | 6,301ms | 467ms | 92.6% | 5,834ms |
| 600개 | 11,701ms | 486ms | 95.8% | 11,215ms |
| 1000개 | 19,811ms | 468ms | 97.6% | 19,343ms |
최대 97% 이상의 성능 개선 효과를 확인할 수 있었다.
Batch Loading의 장점
1. 획기적인 쿼리 수 감소
- N+1 → 1+ceil(N/batch_size) 쿼리로 대폭 감소
- 배치 사이즈에 따라 조절 가능
2. MultipleBagFetchException 회피
- 한 번에 하나씩 컬렉션을 로드하여 오류 방지
List타입 유지 가능
3. 메모리 효율성
- 필요한 시점에만 로드 (LAZY의 장점 유지)
- 배치 단위로 제어하여 메모리 사용량 예측 가능
4. 설정의 간편함
@BatchSize어노테이션만 추가하면 적용 완료- 기존 코드 변경 최소화
- 설정 파일에 추가하여 전역적으로 적용 가능
실무 적용 시 기대 효과
사용자 경험: 20초 → 0.5초로 40배 빠른 응답
서버 안정성: DB 커넥션 풀 고갈 위험 해소
확장성: 트래픽 증가에도 안정적인 서비스 제공
운영 비용: DB 서버 부하 감소로 하드웨어 비용 절약
마무리
N+1 문제는 JPA를 사용하면서 자주 마주치는 성능 이슈라고 생각한다.
이번 성능 테스트를 통해 단순한 어노테이션 또는 설정 하나가 얼마나 강력한 효과를 가져올 수 있는지 직접 확인할 수 있었다.
- EAGER Loading: 간단하지만 메모리와 성능 문제 발생 가능
- Fetch Join: 단일 컬렉션에는 효과적이지만 Multiple Bag 문제
- Batch Loading: 여러 컬렉션이 있을 때 실용적인 해결책
위와 같은 다양한 문제 상황에 대한 해결책 중, 프로젝트에 맞는 적절한 최적화 방안을 선택한 후
@BatchSize 어노테이션 또는 전역적 설정 하나로 실제 최대 97.6%의 성능 향상을 달성했다.
특히 주목할 점은 데이터가 10배 증가해도 응답 시간은 거의 동일하다는 것이다. 이는 서비스 규모가 커져도 안정적인 성능을 보장할 수 있음을 의미한다고 생각한다.
유저 경험 향상에서 핵심인 응답 속도를 좌우하는 DB 조회 성능을,
간단한 설정만으로도 크게 개선할 수 있음을 실제 지표를 통해 확인할 수 있었던 의미 있는 시간이었다.
참고 자료:
