Process, Thread 차이
- 독립된 메모리(프로세스), 공유메모리(스레드)
- 많은 메모리 필요(프로세스), 적은 메모리(스레드)
- 좀비(데드)프로세스 생성 가능성, 좀비(데드) 스레드 생성 쉽지 않음
- 오버헤드 큼(프로세스), 오버헤드 작음(스레드)
- 생성/소멸 다소 느림(프로세스), 생성/소멸 빠름(스레드)
- 코드 작성 쉬움/디버깅 어려움(프로세스), 코드작성 어려움/디버깅 어려움(스레드)
기본 실행
from multiprocessing import Process
import time
import logging
def proc_func(name):
print("Sub-Process {}: starting".format(name))
"""
Process Task
"""
print("Sub-Process {}: finishing".format(name))
def main():
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO, datefmt="%H:%M:%S")
p = Process(target=proc_func, args=("First",))
logging.info("Main-Process : before creating Process")
p.start()
logging.info("Main-Process : During Process")
# logging.info("Main-Process : Terminated Process")
# p.terminate()
logging.info("Main-Process : Joined Process")
p.join()
print(f"Process p is alive: {p.is_alive()}")
if __name__ == "__main__":
main()
- 스레드와 마찬가지로 target 함수, args 인자를 가진다.
terminate(): 강제 종료
프로세스 종료 관리
프로세스는 독립적이기 때문에 부모 프로세스가 종료했더라도 자식 프로세스는 그대로 남아있을 수 있다. 그 역할을 다했더라도 컴퓨팅 자원을 그대로 가진 채로 비효율을 유발할 수 있기 때문에 역할이 끝난다면 반드시 종료를 명시해주어야 한다.
from multiprocessing import Process, current_process
import os
import random
import time
# 실행 방법
def square(n):
# 랜덤 sleep
time.sleep(random.randint(1, 3))
process_id = os.getpid()
process_name = current_process().name
# 제곱
result = n * n
# 정보 출력
print(f"Process ID: {process_id}, Process Name: {process_name}")
print(f"Result of {n} square : {result}")
if __name__ == "__main__":
processes = list()
for i in range(10):
p = Process(name=str(i), target=square, args=(i,))
processes.append(p)
p.start()
# Join
for process in processes:
process.join()
# 종료
print("Main-Processing Done!")위 코드의 Join과 같이 실행한 프로세스를 리스트에 담아서 모든 리스트에 대해 join()을 해줘서 모든 프로세스가 안전하게 종료되고 좀비 프로세스가 없도록 관리한다.
ProcessPoolExcuter
from concurrent.futures import ProcessPoolExecutor, as_completed
import urllib.request
URLS = ['http://www.daum.net/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
# 실행 함수
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
def main():
# 프로세스풀 Context 영역
with ProcessPoolExecutor(max_workers=5) as executor:
# Future 로드(실행X)
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
# 실행
for future in as_completed(future_to_url): # timeout=1(테스트 추천)
# Key값이 Future 객체
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
# 메인 시작
if __name__ == '__main__':
main()
ProcessPoolExcuter을 이용하여 여러 url에 대한 요청을 병렬적으로 처리하는 코드이다.
with문을 통해 ProcessPoolExcuter을 다루면 해당 with문이 끝날 때 ProcessPoolExcuter에 의해 실행된 멀티프로세스들이 함께 종료되어 더 안전한 코드 작성이 가능하다.
Memory Sharing
프로세스는 독립적이기 때문에 직접적인 메모리 공유가 되지 않는다. 공유 메모리 객체나 통신 방법을 이용한다.
Reference
https://docs.python.org/3/library/multiprocessing.html#synchronization-between-processes
Value, Array
from multiprocessing import Process, current_process, Value, Array
import random
import os
def generate_update_number(v : int):
for i in range(50):
v.value += 1
print(current_process().name, "data", v.value)
def main():
# 부모 프로세스 아이디
parent_process_id = os.getpid()
# 출력
print(f"Parent process ID {parent_process_id}")
processes = list()
share_value = Value('i', 0)
for _ in range(1,10):
# 생성
p = Process(target=generate_update_number, args=(share_value,))
# 배열에 담기
processes.append(p)
# 실행
p.start()
for p in processes:
p.join()
# 최종 프로세스 부모 변수 확인
print("Final Data(share_value) in parent process", share_value.value)
if __name__ == '__main__':
main()- Value, Array는 말 그대로 변수, 또는 리스트를 공유메모리 맵에 저장시킬수 있다.
multiprocessing.Value(typecode_or_type, *args, lock=True)
-
공유 메모리에 할당된
ctypes객체를 반환 -
값에 대한 접근은
Value.value로 접근 가능 -
typecode_or_type: 반환된 객체의 형을 결정 -
lock: 액세스를 동기화하기 위한Lock객체 생성. 동기화를 보장해준다.
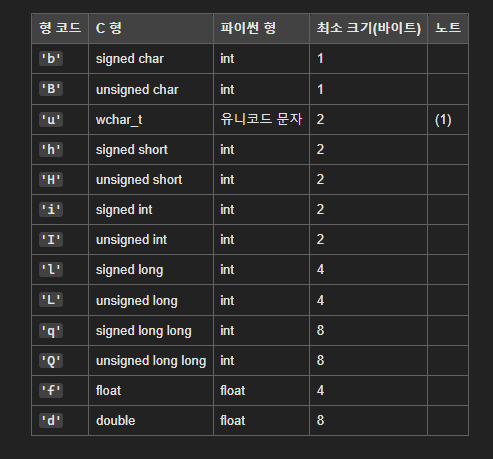
multiprocessing.Array(typecode_or_type, size_or_initializer, *, lock=True)
multiprocessing.Value와 거의 비슷하게 사용된다.size_or_initializer: 말 그대로 사이즈를 지정해주거나 초기화 객체를 입력한다.
Queue
from multiprocessing import Process, Queue, current_process
import time
import os
# 실행 함수
def worker(id, baseNum, q):
process_id = os.getpid()
process_name = current_process().name
sub_total = 0
for i in range(baseNum):
sub_total += 1
q.put(sub_total)
print(f"Process ID: {process_id}, Process Name: {process_name}")
print(f"Result : {sub_total}")
def main():
processes = list()
start_time = time.time()
# Queue 선언
q = Queue()
for i in range(5):
p = Process(name=str(i), target=worker, args=(1, 100000000, q))
processes.append(p)
p.start()
# Join
for process in processes:
process.join()
# 순수 계산 시간
print("--- %s seconds ---" % (time.time() - start_time))
# 종료 플래그
q.put("exit")
total = 0
# 대기 상태
while True:
tmp = q.get()
if tmp == "exit":
break
else:
total += tmp
print()
print("Main-Processing Total_count={}".format(total))
print("Main-Processing Done!")
if __name__ == '__main__':
main()- Queue는 Array와 비슷하지만 Queue 처리방식을 따른다.
- while문에서 대기 상태일 때,
q.get()에서 멈춰있으므로 while문을 돌고있는 상태가 아니다. 덕분에 컴퓨팅 코스트의 낭비는 일어나지 않는다. queue.Queue의 클론에 가깝다.
Pipe
from multiprocessing import Process, Pipe, current_process
import time
import os
# 실행 함수
def worker(id, baseNum, conn):
process_id = os.getpid()
process_name = current_process().name
sub_total = 0
for _ in range(baseNum):
sub_total += 1
# Produce
conn.send(sub_total)
conn.close()
# 정보 출력
print(f"Result : {sub_total}")
def main():
# 시작 시간
start_time = time.time()
# Pipe 선언
parent_conn, child_conn = Pipe()
p = Process(target=worker, args=(1, 100000000, child_conn))
p.start()
p.join()
# 순수 계산 시간
print("--- %s seconds ---" % (time.time() - start_time))
print()
print("Main-Processing : {}".format(parent_conn.recv()))
print("Main-Processing Done!")
if __name__ == "__main__":
main()multiprocessing.Pipe([duplex])
- 파이프의 끝을 나타내는 Connection 객체 쌍
(conn1, conn2)를 반환Connection 객체
기본적으로send(),recv()와 같이 송수신을 가진다.
Reference: https://docs.python.org/ko/3/library/multiprocessing.html#multiprocessing.connection.Connection duplex가True(default)면 양방향 통신이고,False이면 단방향 통신이다.- 단방향 통신이라면
conn1은 수신,conn2는 송신만 가능하다.
- 단방향 통신이라면
