
0️⃣ 들어가며
이전 글인 드라이버의 개요와 이어지는 내용이다.
그렇지만 느낌 상 조금 심화된 것 같으니
내 마음대로 드라이버 제작 기초로 분류하겠음.
1️⃣ 학습 내용
3. 커널 서비스
3-1. 커널의 동적 메모리 할당
✅ 동적 메모리 할당의 개요
-
각 영역의 메모리 할당
-
User Space
C Library(
glibc의malloc/free)에 의한 할당커널에게 큰 메모리 덩어리를 받아와서 각 프로그램에 쪼개어 줌
물리적으로 연속적일 필요 없음
물리적 연속 메모리의 할당이 아니므로 실패의 위험이 상대적으로 적음
-
Kernel Space
Buddy System(도매)과 Slab Allocator(소매)에 의한 할당
물리 메모리를 직접 관리함
하드웨어 제어를 위해 물리적으로 연속된 메모리를 요구하는 경우가 많아 할당 실패 위험이 상대적으로 큼
-
-
메모리의 할당 단위와 매핑
-
Page
가상 메모리 단위로, CPU가 접근하는 논리적인 단위, 기본 4KB
-
Frame
물리 메모리 단위로, 실제 RAM의 물리적인 단위
-
Mapping
MMU(Memory Management Unit)가 Page를 Frame에 연결함
가상 주소상으로는 연속적이라도 실제 물리 주소(Frame)은 연속적이지 않을 수 있음
-
-
할당자의 종류
구분 Buddy System (버디 시스템) Slab Allocator (슬랩 할당자) 역할 도매상 소매상 할당 단위 2^N Page (1, 2, 4, 8, ... Pages) Byte 단위 (객체 크기에 맞춤) 대상 큰 메모리 요청, Slab에 줄 페이지 공급 작은 객체 ( task_struct,inode)해결 문제 외부 단편화 해결 내부 단편화 해결 -
Buddy System
메모리를
2^N크기의 페이지 블록으로 관리메모리 해제 시, 인접한 빈 블록(Buddy)이 있으면 합쳐서 더 큰 블록을 생성함
큰 메모리 요청이 있을 때 할당이 가능하도록 하여 외부 단편화를 해결
할당하는 메모리 단위가 커서(최소 1 Page) 내부 단편화가 발생하는 문제 있음
-
Slab Allocator
Buddy로부터 큰 Page를 받아 와서 작은 크기로 쪼개어 관리하는 할당자
kmem_cache에 정의한 각 캐시 단위로 할당작은 객체들을 딱 맞는 크기의 공간에 채워 넣어 내부 단편화를 해결
자주 생성/해제되는 객체는 미리 만들어 둔 전용 캐시를 운영하여 속도 높임 (예 :
task_struct)
-
-
외부 단편화와 내부 단편화
외부 단편화란 남아 있는 총 메모리 공간이 요청한 메모리 공간보다 크지만, 연속적으로 위치하지 않아 요청한 메모리를 할당할 수 없는 것
내부 단편화란 남아 있는 메모리 영역의 크기가 요청 메모리보다 커서, 메모리 할당 시에 사용되지 않는 메모리가 포함되는 것
-
슬랩 정보 확인하기 :
/proc/slabinfo현재 커널의 슬랩 할당자 상태를 보여주는 파일
# cat /proc/slabinfo dma-kmalloc-8k 0 0 8192 4 8 : tunables 0 0 0 : slabdata 0 0 0 dma-kmalloc-4k 0 0 4096 8 8 : tunables 0 0 0 : slabdata 0 0 0 ... task_struct 304 312 7872 4 8 : tunables 0 0 0 : slabdata 78 78 0 # name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : ...kmalloc-xxx: 특정 구조체 전용이 아니라, 일반적인kmalloc(size)호출 시 사이즈에 맞추어 할당됨task_struct: 프로세스 생성(fork) 시 반드시 필요한 구조체이므로 전용 캐시를 통해 빠른 할당과 해제
✅ 커널 메모리 할당 함수
-
커널 메모리 할당 헤더 :
<linux/gfp.h>물리 페이지 메모리 할당과 관련된 플래그, 매크로, 함수들을 정의한 헤더
kmalloc에서 사용하는 GFP 플래그와 저수준 메모리 할당 함수를 포함
-
물리적 연속 메모리 할당 :
kmalloc/kfree커널에서 가장 일반적으로 사용하는 메모리 할당 함수로, 물리적으로 연속된 메모리를 할당함
할당 :
void *kmalloc(size_t size, gfp_t flags);해제 :
void kfree(cont void *objp);Slab Allocator를 통해 할당됨
할당 크기에 제한이 있으며 이 크기는 커널의 버전마다 다름
초기화되지 않은 메모리를 반환하므로 쓰레기값이 존재할 수 있음
<slab.h>의KMALLOC_MAX_SIZE를 참고 (보통 최대 4MB)#define KMALLOC_SHIFT_HIGH ... #define KMALLOC_MAX_SIZE ... // ./mmzone.h:24: #define MAX_ORDER 11 -
kmalloc의 대표적 옵션 (중요)할당 요청 시 메모리가 부족할 때 행동 방법을 결정하는 옵션
-
GFP_KERNELProcess Context(일반적인 드라이버 코드 등)에서 사용
메모리가 부족하면 Sleep(Block)하여 페이지가 확보될 때까지 대기
-
GFP_ATOMICInterrupt Context(ISR, SoftIRQ 등)에서 사용
메모리가 부족해도 Sleep할 수 없으며 즉시 실패(
NULL) 반환 (빈손으로 복귀)
-
-
초기화된 메모리 할당 :
kzallockmalloc으로 할당받은 메모리를 자동으로 0으로 초기화해주는 함수할당 :
void *kzalloc(size_t size, gfp_t flags);동작은
kmalloc(size, flags | __GFP_ZERO)와 동일함-
Managed Allocation 참고 :
devm_kzallocdevm_kzalloc(dev, size, flags)드라이버가 언로드되거나 디바이스가 제거될 때 커널이 자동으로 메모리를 해제,
kfree불필요최신 드라이버 코드에서 권장하는 방식
-
-
대용량 동적 메모리 할당 :
vmalloc물리적으로 비연속인 공간의 메모리 할당 함수
가상 주소 공간에서는 연속적으로 보이게 만들어 할당하므로,
kmalloc()보다 느림파편화 상황이라도 할당 가능한 총 메모리의 크기보다 요청 크기가 작으면 언제나 할당 가능
할당 :
void *vmalloc(unsigned long size);해제 :
void vfree(const void *addr);
-
페이지 단위 할당
바이트 단위가 아닌 Page(4KB) 단위로 직접 할당받는 저수준 함수
unsigned long __get_free_pages();void free_pages();
3-2. 인터럽트
✅ 인터럽트 처리
-
M-Profile의 인터럽트 처리
ARM Profiles에는 A-Profile, R-Profile, M-Profile이 있음
M-Profile은 Cortex-M(예 : STM32F401RE) 같은 마이크로컨트롤러용 프로파일
A/R-Profile과 예외/인터럽트 처리 방식이 다름
MMU를 사용하지 않고 MPU 기반 보호를 사용하는 경우가 많음
-
예외 처리
외부의 정상적인 요청이나 비정상적인 오류에 의해 실행 흐름을 바꾸는 것
프로그램을 잠시 중지하고 지정된 핸들러로 점프하여 발생한 요청이나 오류를 처리
예외는 그 종류에 따라 예외 벡터 테이블의 특정 오프셋으로 분기함
-
예외 벡터 테이블(Exception Vector Table)
Address (Offset) Exception Type Mode on Entry Priority (1=High) 0x00000000 Reset Supervisor (SVC) 1 0x00000004 Undefined Instruction Undefined (UND) 6 0x00000008 Software Interrupt (SWI/SVC) Supervisor (SVC) 6 0x0000000C Prefetch Abort (Instruction Fetch Fail) Abort (ABT) 5 0x00000010 Data Abort (Data Access Fail) Abort (ABT) 2 0x00000014 (Reserved) - - 0x00000018 IRQ (Interrupt Request) IRQ 4 0x0000001C FIQ (Fast Interrupt Request) FIQ 3
-
-
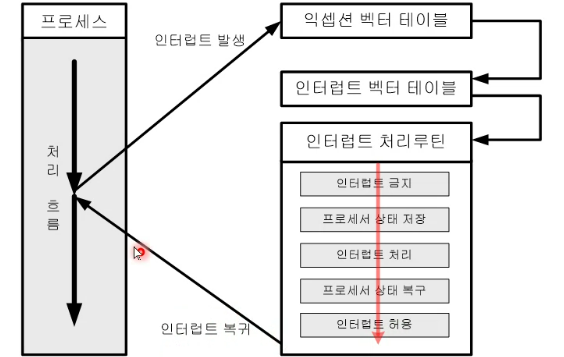
인터럽트 처리 과정
-
진입 단계 (#1 ~ #3)
#1 (H/W Interrupt) : 하드웨어 이벤트가 발생하여 CPU가 하던 일을 멈춤
#2 (EVT Jump) : CPU는 미리 정의된 EVT(Exception Vector Table)의 IRQ 주소로 점프, 여기엔 보통
b irqHandler같은 분기 명령어가 있음#3 (Enter Handler) : 공통 인터럽트 처리 루틴(
irqHandler)으로 진입
-
준비 단계 (#4 ~ #7)
#4 (Prologue) : 현재 실행 중이던 프로그램의 레지스터 값(Context)을 스택에 저장(Push)
#5 (Get Int No) : 인터럽트 컨트롤러(GIC 등)를 조회하여 누가 인터럽트를 걸었는지 번호(ID)를 알아냄
#6, #7 (Lookup IVT) : 알아낸 번호를 가지고 메모리에 있는 IVT(Interrupt Vector Table)를 참조하여, 실제 실행해야 할 함수(
isr3)의 주소를 가져옴
-
실행 및 복귀 단계 (#8 ~ #11)
#8, #9 (Call ISR) : 실제 디바이스 드라이버의 함수(
isr3)를 호출하여 인터럽트를 처리 (예: 키보드 입력 읽기)#10 (Epilogue) : #4에서 스택에 저장해뒀던 레지스터 값들을 다시 복구(Pop)
#11 (Return) : 인터럽트 발생 직전의 지점으로 돌아가(PC 복구) 멈췄던 프로그램을 계속 실행
-
-
리눅스의 인터럽트 처리 과정
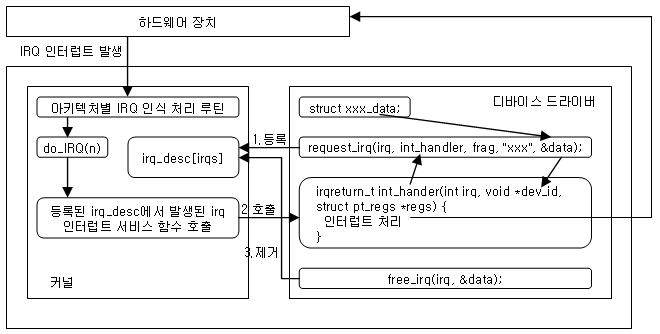
각 IRQ는 커널 내부의 인터럽트 디스크립터
irq_desc로 표현인터럽트가 트리거되면
irq_desc의handle_irq()경로로 진입irq_desc: IVT {isr1, isr2, …} → IVT처럼 보이는 등록 테이블 역할request_irq(irq, handler, flags, name, dev_id): 핸들러를 IRQ 라인에 연결하는 등록 함수
-
BCM2835 인터럽트 컨트롤러
SoC/아키텍처마다 인터럽트 컨트롤러와 레지스터 맵이 다름
BCM2835는 물리적 주소 0x2000B000에 위치한 메모리 맵 방식의 장치
일부 IRQ는 ARM CPU와 GPU에서 공유
✅ 인터럽트 서비스 함수
-
인터럽트 서비스 함수 사전 등록 :
request_irq<linux/interrupt.h>헤더 내에 포함#include <linux/interrupt.h> int request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, const char *name, void *dev);irqreturn_t xxx_interrupt() { //인터럽트 서비스 루틴 return IRQ_HANDLED; } int xxx_open() { if (! request_irq(XXX_IRQ, xxx_interrupt, IRQF_DISABLED, "xxx", NULL)) { // 정상 등록 후 처리 } return 0; } -
request_irq()파라미터파라미터 의미 설명 irqinterrupt no. 보드/DT(Device Tree)/플랫폼에 따라 번호가 다름 handlerISR 함수 포인터 보통 irqreturn_t (*handler)(int, void*)형태를 사용flagsIRQ 속성 공유 여부/트리거 방식 등을 지정 name디바이스 이름 /proc/interrupts에 표시되는 이름dev_id공유 IRQ 구분자 IRQF_SHARED 사용 시 필수로 고유 포인터를 넣는 게 정석(해제 시 매칭에 사용) -
flags 예시
IRQF_SHARED: IRQ 공유 허용(여러 드라이버가 같은 IRQ 라인 사용)IRQF_TIMER: 타이머 관련 IRQ (특수 용도)IRQF_TRIGGER_FALLING/IRQF_TRIGGER_RISING: 엣지 트리거IRQF_TRIGGER_HIGH/IRQF_TRIGGER_LOW: 레벨 트리거
-
-
등록된 ISR의 확인
# cat /proc/interrupts명령어 입력CPU0 CPU1 CPU2 CPU3 9: 0 0 0 0 GICv2 25 Level vgic 11: 547165 597936 667778 402088 GICv2 30 Level arch_timer 12: 0 0 0 0 GICv2 27 Level kvm guest vtimer 14: 49568 0 0 0 GICv2 65 Level fe00b880.mailbox 15: 9547 0 0 0 GICv2 114 Level DMA IRQ 16: 0 0 0 0 GICv2 116 Level DMA IRQ ...
✅ Top Half와 Bottom Half
-
Top half와 Bottom half의 분리
인터럽트 처리가 길어지면 시스템의 다른 중요한 이벤트 처리가 지연됨
시급한 작업과 미룰 수 있는 작업으로 나누어 처리
-
Top Half
ISR(Interrupt Service Handler)이 담당
Urgent & Non-blocking이 특징으로, 하드웨어와 직업 상호작용
실행 시간이 매우 짧아야 하며, 절대 Sleep할 수 없음
하드웨어 인터럽트 ACK, 하드웨어 버퍼의 데이터를 커널로 복사, BH 작업 예약
-
Bottom Half
kthread(worker thread) 담당
Defferable(지연 처리 가능)한 것이 특징으로, 다른 급한 인터럽트를 방해하지 않음
복사된 데이터의 가공, 복잡한 연산, I/O 처리 등의 작업
-
-
Interrupt context에서의 동적 메모리 할당
Top Half는 Interrupt Context에서 실행되며, Sleep(Blocking) 불가
반드시
GFP_ATOMIC플래그를 사용해야 함 (kmalloc(size, GFP_ATOMIC))
-
인터럽트의 금지와 허용
특정 구간에서 인터럽트를 금지하거나 허용할 때 사용하는 방법
ISR 등록 시
request_irq함수의flag를 변경(예 :
IRQF_DISABLED- 이전에 인터럽트 라인 차단하던 플래그,IRQF_SHARED- 공유 허용 여부 결정)코드 내에서는
local_irq_disable()/local_irq_enable()등으로 CPU의 인터럽트 금지/허용
-
Bottom Half 메커니즘 4가지
-
Softirq
컴파일 타임에 정적으로 생성, Interrupt Context에서 실행
커널 코어에서만 사용하고, 일반 드라이버에는 사용하지 않을 것을 권장
-
Tasklet
런타임에 동적으로 생성, Interrupt Context에서 실행
Softirq 기반으로 구현되어 있지만 obsolete(구식)
같은 타입의 Tasklet은 동시에 실행되지 않음
-
Workqueue
동적으로 생성, Process Context에서 실행
Kernel Thread(Worker)가 수행하며 Sleep 가능
work는 workqueue를 실행하는 단위로, 수행할 작업
Global Queue: 시스템 전용 큐(기성복)에 Work만 던져줌
Custom Queue: 전용 큐(맞춤복)를 직접 생성하여 사용
-
Threaded IRQ
동적으로 생성, Process Context에서 실행
ISR을 최소화하고 주 처리를 전용 커널 스레드로 위임
request_threaded_irq()로 등록
-
✅ Workqueue
-
Workqueue의 개요
할 일(work)를 큐(Queue)에 넣어두면 커널 스레드(Worker)가 나중에 꺼내서 처리하는 메커니즘
프로세스 컨텍스트의 특징을 가짐 (선점·스케줄링 가능, 인터럽트 허용, Sleep, 메모리 할당, …)
Global Workqueue와 Custom Workqueue로 두 가지 종류가 있음
-
Worker Kernel Threads :
kworker실제 지연 처리된 작업을 수행하는 커널 스레드
시스템 백그라운드에서 대기하다가 워크 큐에 작업이 들어오면 깨어남
워크 큐에 등록된 task(work)들을 하나씩 꺼내어 비동기적으로 처리
인터럽트 핸들러나 중요한 커널 스레드가 오랜 시간 블록되는 것을 방지하기 위해 사용
시간이 오래 걸리거나 즉시 처리할 필요가 없는 작업은 워크큐에 등록
커널의 응답성을 유지하고 시스템의 안정성을 높임
(수행 작업 예 : 파일 시스템 동기화, 장치 드라이버의 지연 작업 등)
-
kworker의 생성부팅 시 CPU별로 생성되고 시스템 백그라운드에서 대기하고 있음
schedule_work(),queue_work()함수를 호출하여 작업을 워크 큐에 추가→ 커널은
kworker스레드를 깨우거나 새롭게 생성하여 작업을 처리# ps -ef | grep kworker root 21 2 0 08:49 ? 00:00:00 [kworker/1:0-events] root 22 2 0 08:49 ? 00:00:00 [kworker/1:0H-kblockd] root 105 2 0 08:49 ? 00:00:00 [kworker/0:2H-kblockd] root 125 2 0 08:49 ? 00:00:00 [kworker/3:2H-kblockd] root 126 2 0 08:49 ? 00:00:00 [kworker/2:2H-kblockd] root 436 2 0 08:49 ? 00:00:06 [kworker/u9:1-brcmf_wq/mmc1:0001:1] root 717 2 0 08:49 ? 00:00:04 [kworker/u9:2-brcmf_wq/mmc1:0001:1] root 811 2 0 08:49 ? 00:00:00 [kworker/2:4-events] root 931 2 0 09:23 ? 00:00:00 [kworker/2:1H]
-
✅ Global Workqueue
- Global Workqueue의 생성
</linux/workqueue.h>-
정적 선언
DECLARE_WORK(work, function);워크 큐에 등록될 작업 구조체 변수를 정적으로 선언하고 초기화하는 매크로
work: 생성할struct work_struct변수function: 워크 큐에서 실행할 작업 처리 함수 -
동적 초기화
struct work_struct work; // 미리 선언 INIT_WORK(&work, function);이미 선언된 작업 구조체 변수를 초기화하는 매크로
work: 초기화할struct work_struct변수의 포인터function: 워크 큐에서 실행할 작업 처리 함수
-
- 워크 큐에 Work 스케줄링하기
// 워크 항목을 스케줄링 int schedule_work(struct work_struct *work); // 워커 스레드를 Delay(giffies)만큼 지연시켜 스케줄링 bool schedule_delayed_work(struct delayed_work *dwork, unsigned long delay); // 지정된 CPU에 스케줄링 bool schedule_work_on(int cpu, struct work_struct *work); // 지정된 CPU에 Delay만큼 지연시켜 스케줄링 int schedule_delayed_work(struct work_struct *work, unsigned long delay); - Work 취소 및 대기
// 큐에 있는 작업 취소 (실행 중이면 대기 후 취소) int cancel_work_sync(struct work_struct *work); bool cancel_delayed_work(struct delayed_work *dwork); // 지연 작업 // 현재 실행 중인 작업이 끝날 때까지 대기 (Flush) bool flush_work(struct work_struct *work); void flush_scheduled_work(void);
✅ Custom Workqueue
-
Custom Workqueue의 생성
<linux/workqueue.h>/kernel/workqueue.c동적 워크큐 생성 :
alloc_workqueue(name, flags, max_active)구형 함수 :
create_workqueue(name)해제 :
destroy_workqueue(wq)// 생성 struct workqueue_struct *my_wq; my_wq = alloc_workqueue("my_driver_wq", WQ_UNBOUND, 1); // 해제 destroy_workqueue(my_wq); -
커스텀 워크큐의 주요 플래그
플래그 의미 WQ_UNBOUND특정 CPU에 묶이지 않음 WQ_FREEZABLE시스템 절전 시 큐를 Freeze WQ_HIGHPRI높은 우선순위로 처리 WQ_CPU_INTENSIVECPU 집약적, 사용량이 많은 작업임을 알림 -
워크 큐에 Work 스케줄링하기
// 전용 큐에 작업 등록 bool queue_work(struct workqueue_struct *wq, struct work_struct *work); // 특정 CPU의 워크 큐에 작업 등록 bool queue_work_on(int cpu, struct workqueue_struct *wq, struct work_struct *work); // 워크 큐에 Delay만큼 지연시켜 작업 등록 bool queue_delayed_work(struct workqueue_struct *wq, struct delayed_work *dwork, unsigned long delay) // 특정 CPU의 워크 큐에 Delay만큼 지연시켜 작업 등록 bool queue_delayed_work_on(int cpu, struct workqueue_struct *wq, struct delayed_work *dwork, unsigned long delay); -
커스텀 워크 큐 사용 예시
#include <linux/workqueue.h> // stcurt work_struct xxx_work void xxx_func(void *data) { ... } DECLARE_WORK(xxx_work, xxx_func, &xxx_data); // 워크의 선언 struct workqueue_struct * xxx_workqueue; // 커스텀 워크큐 irqreturn_t xxx_interrupt(...) { ... // top half queue_work (xxx_workqueue, &xxx_work); // 엔큐 워크 to 커스텀 워크큐 } int xxx_init(void) { xxx_workqueue = create_workqueue("ktestd"); // 커스텀 워크큐 생성 } // 이후 destroy_workqueue()함수 적용
✅ Threaded IRQ
-
Threaded IRQ
인터럽트 핸들러가 수행해야 할 주 작업을 전용 커널 스레드로 생성하여 처리하는 방식
Latency 감소로 높은 시스템 응답성을 가짐
태스크릿이나 워크 큐를 따로 만들 필요 없이
request_threaded_irq()만 사용IRQ 공유가 용이하고,
ps명령어로irq/스레드를 볼 수 있어 상태 확인 편리함
2️⃣ 느낀 점
다른 건 그래도 있을만하다 싶은 내용이었는데
급하다고 소문난 인터럽트 안에서도 Top/Bottom 이 나뉘고
우선적으로 처리해야 하는 부분이 있다는 건 처음 알았다.
역시 세상에 쉬운 일은 하나도 없었다...!
할당이나 Bottom Half 처리 메커니즘도 여러 가지가 있고
요즘에는 사용하기 편리한 함수도 많다고 한다.
우리는 워크 큐에 관해 가장 오래 다루었지만
실제로는 Threaded IRQ 사용을 권장한다는 말도 있을 정도이니
잘 알아보고 개발하는 드라이버에 가장 적합한 방향을 선정하도록 합시다요
