자료구조
- 자료구조의 내용(en)
- 여러 데이터의 묶음을 저장, 사용하는 방법을 정의한 것
- 데이터는 분석하고 정리하여 활용해야만 의미를 가질 수 있음
- 데이터를 체계적으로 정리하여 저장해둬야 활용하기에 유리함
- 각각의 자료구조들은 특정한 상황에서 활용하기에 유리하도록 특화되어 만들어져 있음
Stack
- 데이터를 순서대로 쌓는 구조
- First In Last Out, 선입 후출 구조
- 대표적 예시, 웹 브라우저에서 페이지 이동 시에 이전 페이지 또는 다음 페이지를 보관하는 방식
Queue
- 데이터를 쌓은 순서대로 나가는 구조
- First In First Out, 선입 선출 구조
- 대표적 예시, 프린터의 출력 대기 목록을 관리하는 방식, 먼저 들어온 목록부터 출력하여 내보낸다
Graph
- 데이터의 그래프는 수학의 그래프와는 다르게, 네트워크망의 형태를 가진다
- 여러개의 점들이 서로 연결되어 있는 관계를 표현한 자료구조
- 대표적 예시, 기차 노선표 또는 전철 노선표, 역이 서로 이어져있는 구조와 유사하다
- 그래프 용어 정리
- 정점(vertex): 노드(node)라고도 하며, 데이터가 저장되는 그래프의 기본 원소
- 간선(edge): 정점 간의 관계(한방향 이동인지, 양방향 이동인지를 표시)
- 인접 정점(adjacent vertex): 하나의 정점에서 간선으로 직접 연결되어 있는 정점을 말한다
- 인접(adjacency): 정점 간에 간선이 직접 이어져 있다면 이 정점들은 인접한다
- 가중치 그래프(weighted): 연결의 강도(추가적인 정보, 데이터의 흐름에 영향을 주는 정보)가 적혀있는 그래프
- 비가중치 그래프(unweigthed): 연결의 강도가 적혀있지 않는 그래프
- 무향(무방향) 그래프(undirected): 정점간에 연결된 간선이 양방향 통행이 가능함을 의미함
- 단방향 그래프(directed): 정점의 간선이 일방통행인 경우를 의미함
- 진입차수(in-degree) / 진출차수(out-degree): 정점으로 들어오는 간선, 또는 나가는 간선의 수를 의미함
- 자기 루프(): 진출 간선이 다른 정점을 거치지 않고, 곧바로 자기에게 진입하는 경우
- 사이클(): 한 정점에서 출발, 다른 간선을 거쳐 자기에게 돌아갈 수 있다면 사이클이 있다고 한다
- 인접 행렬
- 서로 다른 정점들이 인접한 상태인지를 표시한 행렬로 2차원 배열로 나타낸다
- A-B는 양방향 그래프
- A->C로의 단방향 그래프
- C는 자기 루프 그래프
- 인접 리스트
- 각 정점이 어떤 정점과 인접하는지를 리스트로 표현
- 각 정점마다 하나의 리스트를 가지고, 인접한 정점을 담고 있다
- A -> C -> null
- B -> A -> C -> null
- C -> A -> null
- 메모리를 효율적으로 사용하고 싶을 때에 사용
- 인접 행렬은 모든 경우의 수를 저장, 상대적으로 메모리를 많이 차지함
Tree
- 하나의 root에서 edge가 가지처럼 사방으로 뻗은 나무와 닮은 형태
- 데이터가 바로 아래의 하나 이상의 데이터에 단방향으로 연결된 계층적 자료구조, 비선형 구조
- 트리 용어 정리
- 노드(node): 개별 데이터
- 루트(root): 시작점이 되는 노드
- 부모 노드(parent): 두 노드 중 루트쪽에 가까운 상위 노드
- 자식 노드(child): 두 노드 중 하위 노드
- 리프(leaf): 트리 구조의 끝 지점, 자식 노드가 없는 노드
- 깊이(depth): 루트(0)에서 노드까지의 거리
- 레벨(): 루트는 Lv1, 같은 깊이를 가진 노드를 묶어서 레벨로 표현하고 형제 노드(sibling node)라고 한다
- 높이(height): 리프 노드(0)에서 루트까지의 거리
- 서브 트리(sub tree): root에서 뻗어 나온 가지 중, 작은 구조를 갖춘 트리를 지칭함
BST
- 트리 구조는 데이터를 편리한 구조로 전시하고 그 데이터를 효율적으로 탐색하기 위해 작성함
- Binary Search Tree, 가장 간단하고 많이 사용하는 이진 트리(Binary tree)를 탐색하는 방식
- 모든 왼쪽 자식의 값이 루트나 부모보다 작고, 모든 오른쪽 자식의 값이 루트나 부모보다 큰 값을 가지는 특징이 있다
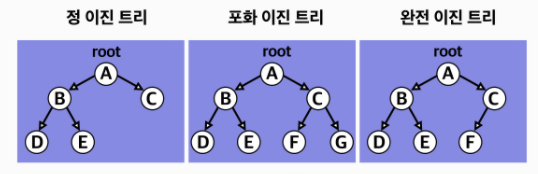
- 정 이진 트리(Full binary tree): 각 노드가 0 개 혹은 2 개의 자식 노드를 가진다
- 완전 이진 트리(Complete binary tree): 마지막 레벨을 제외한 모든 노드가 가득 차 있어야 하고, 마지막 레벨의 노드는 전부 차 있지 않아도 되지만 왼쪽이 채워져야 함
- 포화 이진 트리(Perfect binary tree): 정 이진 트리이면서 완전 이진 트리인 경우
Tree traversal
- 트리 순회: 특정 목적을 위해 트리의 모든 노드를 한 번씩 방문하는 것
- 트리 구조에서 노드를 순차적으로 조회할 때의 순서는 항상 왼쪽부터 오른쪽
- 전위 순회(Preorder traverse): 루트에서 시작해 왼쪽의 노드들을 순차적으로 둘러본 뒤, 왼쪽의 노드 탐색이 끝나면 오른쪽 노드를 탐색을 합니다.
- 중위 순회(Inorder traverse): 루트를 가운데에 두고 순회합니다. 제일 왼쪽 끝에 있는 노드부터 순회하기 시작하여, 루트를 기준으로 왼쪽에 있는 노드의 순회가 끝나면 루트를 거쳐 오른쪽에 있는 노드로 이동하여 마저 탐색합니다.
- 후위 순회(Postorder traverse): 루트를 가장 마지막에 순회합니다. 제일 왼쪽 끝에 있는 노드부터 순회하기 시작하여, 루트를 거치지 않고 오른쪽으로 이동해 순회한 뒤, 제일 마지막에 루트를 방문합니다
- 힙: 완전 이진 트리를 기본으로 최대값 또는 최소값을 찾는 연산을 빠르게 하기 위해 고안된 자료구조
- 자식 노드들이 특정한 성질을 가지고 정렬되어 있는 구조
- 키 값의 대소 관계는 부모-자식 간에만 성립하며, 형제 사이에는 대소 관계가 성립하지 않는다
- 최대 힙 구조(Max Heap): 부모 노드가 자식 노드들보다 큰 경우
- 최소 힙 구조(Min Heap): 부모 노드가 자식 노드들보다 작은 경우
- 힙(Heap) - wikipidia
BFS / DFS
- BFS
- Breadth-First Search, 너비 우선 탐색
- 가까운 정점들부터 탐색, 이후 다음 레벨의 정점들을 탐색하며 나아가는 방식
- DFS
- Deep-First Search, 깊이 우선 탐색
- 하나의 경로에 있는 정점들을 리프 끝까지 탐색, 이후 다음 경로를 리프 끝까지 탐색하며 나아가는 방식
