
목차
- 데이터베이스 시스템
- 데이터베이스 핵심 개념
- SQL
데이터베이스 시스템
데이터베이스 시스템은 말 그래도 데이터를 저장 및 보전하는 시스템이다. 데이터베이스에 저장되어 있는 데이터를 읽어들일 수 있으며, 기존의 데이터를 업데이트 및 추가, 삭제도 가능하다.
일반적으로 데이터베이스 시스템에서는 크게 관계형데이터 베이스 시스템(RDBMS), 비관계형 데이터베이스가 있다.
관계형 데이터베이스
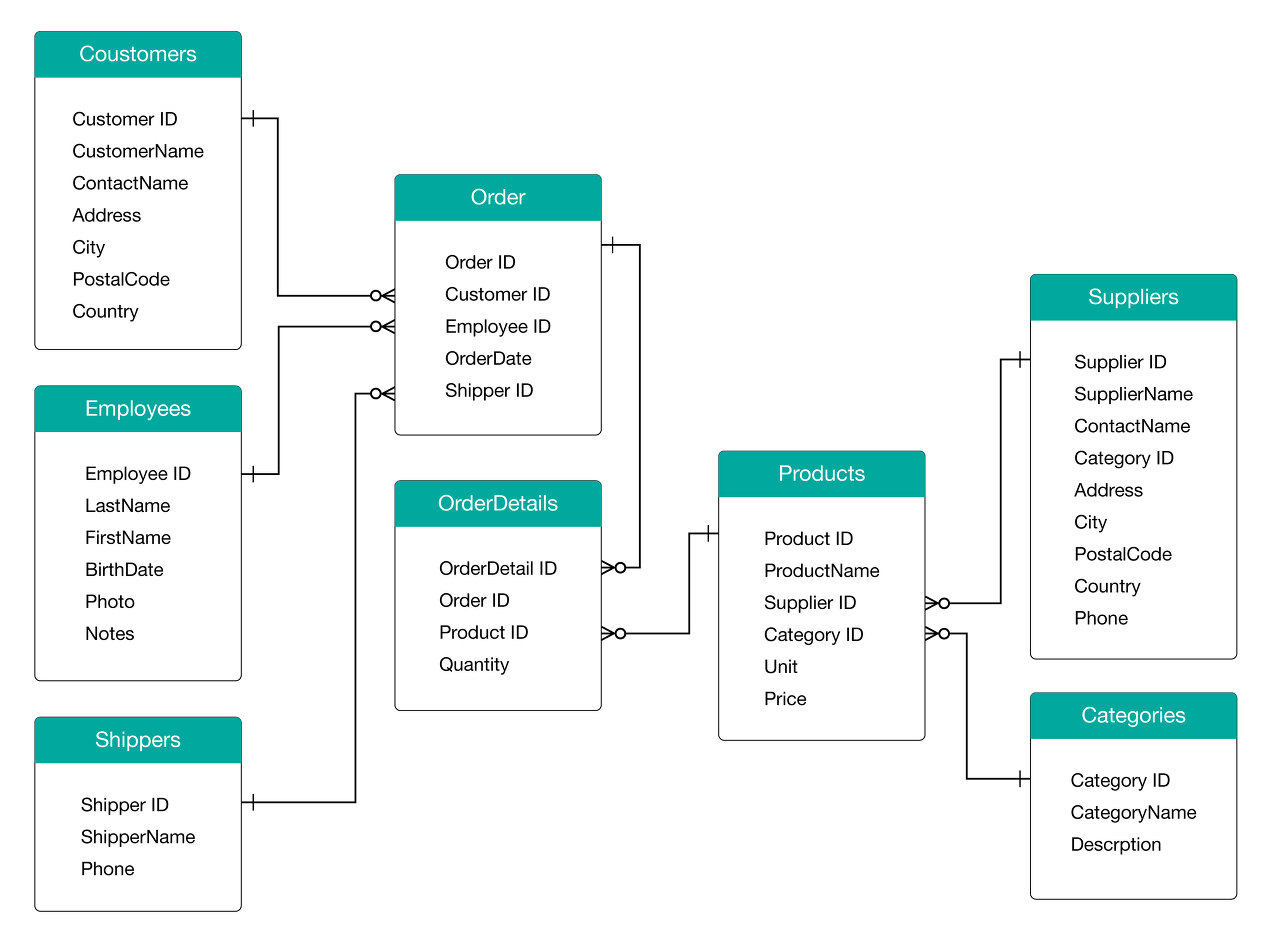 관계형 데이터란 데이터들이 서로 상호 관련성을 가진 형태로 표현한 데이터이며, 대표적으로 MYSQL과 PostgreSQL 등이 있으며,ID 칼럼이 각 테이블의 고유 키가 된다.
관계형 데이터란 데이터들이 서로 상호 관련성을 가진 형태로 표현한 데이터이며, 대표적으로 MYSQL과 PostgreSQL 등이 있으며,ID 칼럼이 각 테이블의 고유 키가 된다.
모든 데이터들은 2차원 테이블 (table)들로 표현됨
- 각각의 table은 칼럼 (column)과 로우 (row)로 구성
- 각 row는 고유 키 (primary key)를 가짐, 이 primary key를 통해서 해당 row를 찾고자 인용 (reference)함.
- 외부 키 (foreign key)를 통해 서로 다른 table을 연결함.
관계형 데이터 베이스에서 테이블간의 연결은 크게 다음의 3가지가 있다.
- one to one
- one to many
- many to many
one to one
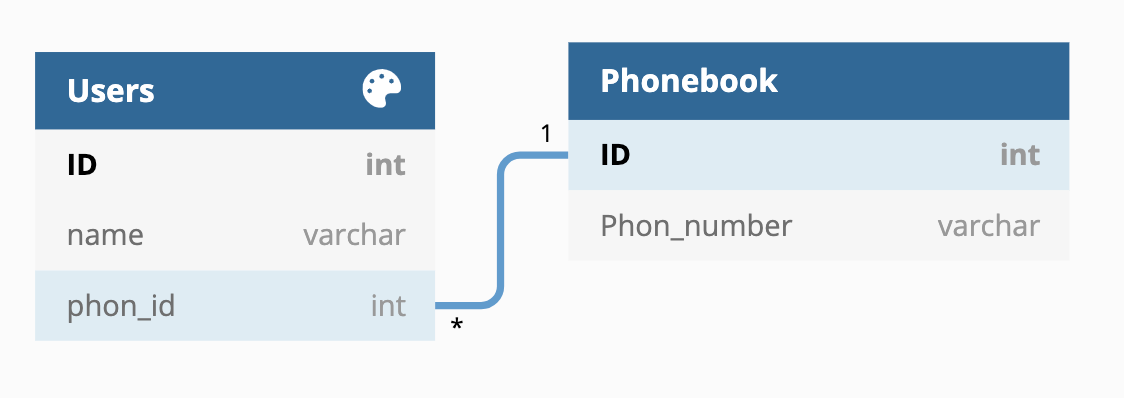 하나의 레코드가 다른 테이블의 레코드 한 개와 연결
하나의 레코드가 다른 테이블의 레코드 한 개와 연결
자주 사용되지 않음
one to many
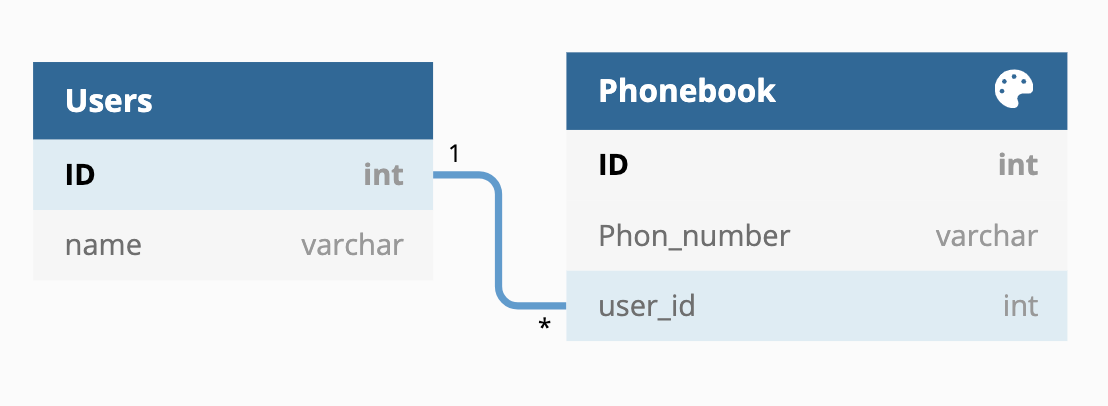 하나의 레코드가 서로 다른 여러 개의 레코드와 연결
하나의 레코드가 서로 다른 여러 개의 레코드와 연결
가장 많이 사용됨
many to many

여러 개의 레코드가 다른 테이블의 여러 개의 레코드와 관계
정규화
왜 정보를 굳이 여러 테이블에 나눠서 저장하는가?
- 하나의 테이블에 모든 정보를 다 넣게 되어, 동일한 정보들이 불필요하게 중복되어 저장되는 경우를 방지
- 참조 과정, 설계에서 데이터의 오류 최소화
트랜잭션
- 일련의 작업들이 마치 하나의 작업처럼 취급되어 모두 다 성공하거나, 모두 다 실패하게 하는 것
- ex) 은행 예/출금 서비스
- 트랜잭션을 보장하기 위해 ACID(원자성, 일관성, 고립성, 지속성)의 성질을 지니고 있음
비관계형 데이터베이스
테이블들의 스키마와 테이블간의 관계를 미리 구현할 필요 없이, 데이터가 들어오는 그대로 저장됨.
데이터베이스 핵심 개념
관계형 데이터베이스 (RDB)는 주로 정형화된 데이터들 그리고 데이터의 완전성이 중요한 데이터들을 저장하는 데 유리함. (e.g. 전자상거래 정보, 은행 계좌정보, 거래 정보 등)
장점
- 데이터를 효율적이고 체계적으로 저장하고 관리 할 수 있음.
- 사전에 저장하는 테이블 (table)의 스키마 (schema)를 정의함으로써 데이터의 완전성을 보장할 수 있음.
- 트랜잭션 (transaction) 기능을 사용할 수 있음.
단점
- table의 구조변화에 유연하지않음.
- 확장이 쉽지않음.
- 서버를 늘려서 분산 저장하는 것이 쉽지않음.
- 스케일 아웃 (scale out, 서버 수를 늘려서 확장하는 것)보다는 스케일 업 (scale up, 서버의 성능을 높이는 것)으로 확장해야함.
비관계형 데이터베이스 (NoSQL)는 비정형화 데이터, 완전성이 상대적으로 덜 필요한 데이터를 저장하는 데 유리함. (e.g. 로그 데이터)
장점
- schema를 미리 정의하지않으므로 저장하는 데이터의 구조 변화에 유연
- scale out의 방식으로 시스템 확장이 가능함.
- 확장하기가 쉽고, 데이터의 구조도 유연하다보니 방대한 양의 데이터를 저장하는 데에 유리
단점
- 데이터의 완전성을 보장할 수 없음.
- transaction이 안 되거나 되더라도 비교적 불안정함.
SQL
SQL (Structured Query Language)는 MySQL 같은 관계형 데이터베이스 관리 시스템 (RDBMS)에서 데이터를 읽거나 생성 및 수정하기위해 사용하는 언어, 기본적으로 CRUD (Create, Read, Update, Delete)를 제공하는 RDBMS 전용 언어
SELECT
RDBMS에서 데이터를 읽어 들일 때 사용하는 SQL 구문
SELECT
column1,
column2,
column3,
column4
FROM table_name예시
SELECT
id,
name,
age,
gender
FROM users
SELECT
id,
name,
age,
gender
FROM users WHERE name = "김보섭"INSERT
RDBMS에서 데이터를 생성할 때 사용하는 SQL 구문
기본 문법
INSERT INTO table_name (
column1,
column2,
column3
) VALUES (
column1_value,
column2_value,
column3_value
)예시
INSERT INTO users (
id,
name,
age,
gender
) VALUES (
1,
"김보섭",
32,
"남자"
)
INSERT INTO users (
id,
name,
age,
gender
) VALUES (
1,
"김보섭",
32,
"남자"
), (
2,
"Robert Kelly",
28,
"남자"
)UPDATE
RDBMS에서 기존의 데이터를 수정할 때 사용하는 SQL 구문
기본 문법
-- WHERE와 같이 사용하지않으면 모든 row가 수정됨.
UPDATE table_name SET column1 = value1 WHERE column2 = value2예시
UPDATE users SET age = 25 WHERE name = "Robert Kelly"DELETE
RDBMS에서 데이터를 삭제할 때 사용하는 SQL 구문
-- WHERE와 같이 사용하지 않으면 모든 row를 삭제함
DELETE FROM table_name WHERE column = value예시
DELETE FROM users WHERE age < 20JOIN
RDBMS에서 여러 table을 연결할 때 사용하는 SQL 구문 (RDBMS에서 원하는 정보를 전부 얻기위해서는 하나 이상의 table에서 값을 읽어들여야할 필요가 자주 있고, 이 때 JOIN 구문을 활용함.)
SELECT
table1.coumn1,
table2.coumn2
FROM table1
JOIN table2 ON table1.id = table2.table1_id --table2의 table1에 대응되는 column을 의미함예시
SELECT
users.name,
user_address.address
FROM users
JOIN user_address ON users.id == user_address.user_id