목차
검색 알고리즘 개요
선형검색(Linear Search)
이진검색(Binary Search)
해시 (Hash)
1) 검색 알고리즘 개요
특정 조건을 만족하는 데이터를 찾아내는 과정
검색이 빠르게 될수록 좋은 성능(낮은 시간 복잡도)
다만, 검색만을 위한 자료구조가 아닌 이상 데이터의 추가, 삭제 등의 비용까지 종합적으로 고려하여 자료구조, 알고리즘을 선택해야 함
2) 선형검색(Linear Search)
키워드 : 무작위로 늘어놓은 데이터 집합에서 검색을 수행
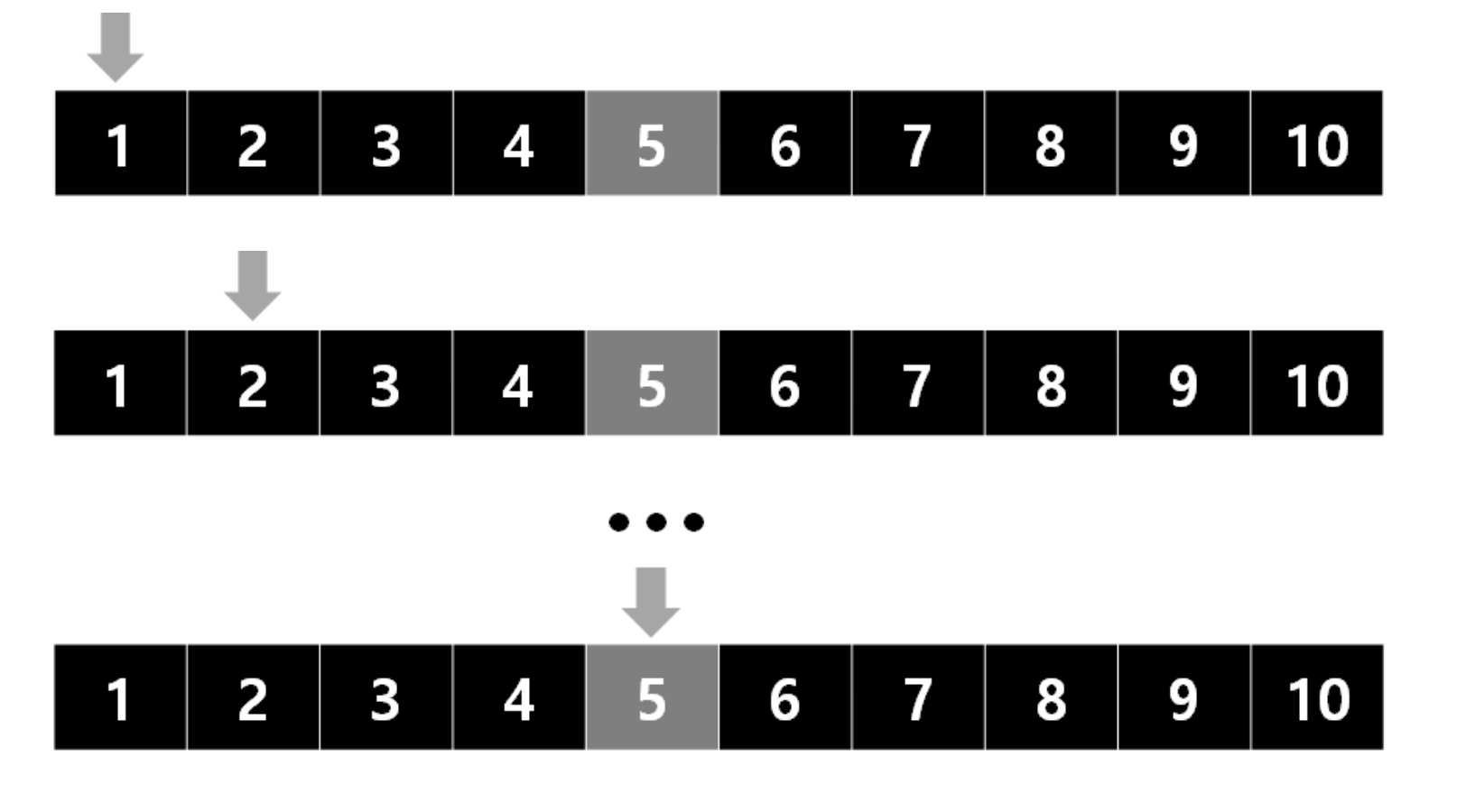
찾고자하는 원소를 찾을때까지 배열의 맨 앞에서부터 순서대로 스캔하며 검색
검색할 값을 찾지 못하고 배열의 끝에 도달한 경우에는 검색 실패
from typing import Any, Sequence
def seq_search(a: Sequence, key: Any) -> int:
"""시퀀스 a에서 key값이 같은 원소를 선형 검색(while 문)"""
i = 0
while True:
if i == len(a):
return -1 # 검색에 실패하여 -1을 반환
if a[i] == key:
return i # 검색에 성공하여 현재 조사한 배열의 인덱스를 반환
i += 1
if __name__ == '__main__':
num = int(input('원소 수를 입력하세요.: ')) # num 값을 입력
x = [None] * num # 원소 수가 num인 배열을 생성
for i in range(num):
x[i] = int(input(f'x[{i}]: '))
ky = int(input('검색할 값을 입력하세요.: ')) # 검색할 키 ky를 입력받기
idx = seq_search(x, ky) # ky와 같은 원소를 x에서 검색
if idx == -1:
print('검색값을 갖는 원소가 존재하지 않습니다.')
else:
print(f'검색값은 x[{idx}]에 있습니다.')보초법
검색할 값을 배열의 맨 끝에 추가하여, 반복을 종료하는 판단 횟수를 줄이는 역할 가능
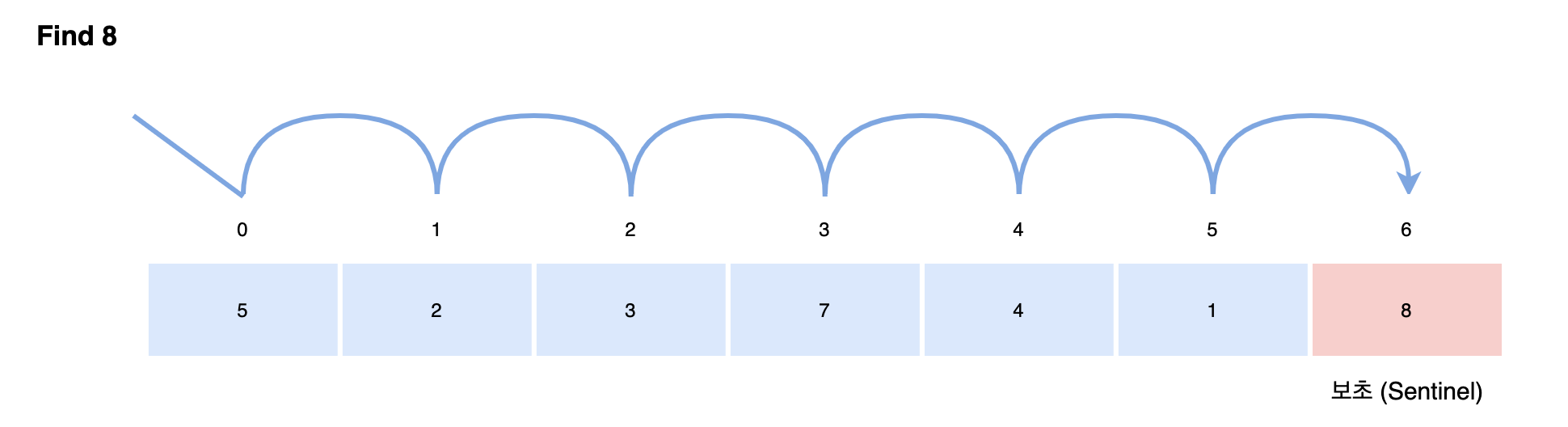
from typing import Any, Sequence
import copy
def seq_search(seq: Sequence, key: Any) -> int:
"""시퀀스 seq에서 key와 일치하는 원소를 선형 검색(보초법)"""
a = copy.deepcopy(seq) # seq를 복사
a.append(key) # 보초 key를 추가
i = 0
while True:
if a[i] == key:
break # 검색에 성공하면 while 문을 종료
i += 1
return -1 if i == len(seq) else i
if __name__ == '__main__':
num = int(input('원소 수를 입력하세요.: ')) # num 값을 입력
x = [None] * num # 원소 수가 num인 배열을 생성
for i in range(num):
x[i] = int(input(f'x[{i}]: '))
ky = int(input('검색할 값을 입력하세요.: ')) # 검색할 키 ky를 입력받기
idx = seq_search(x, ky) # ky값과 같은 원소를 x에서 검색
if idx == -1:
print('검색값을 갖는 원소가 존재하지 않습니다.')
else:
print(f'검색값은 x[{idx}]에 있습니다.')시간복잡도
O(N)
일반적으로, 연속적인 동작의 시간복잡도
O(f(n)) + O(g(n)) = O(max(f(n), g(n))
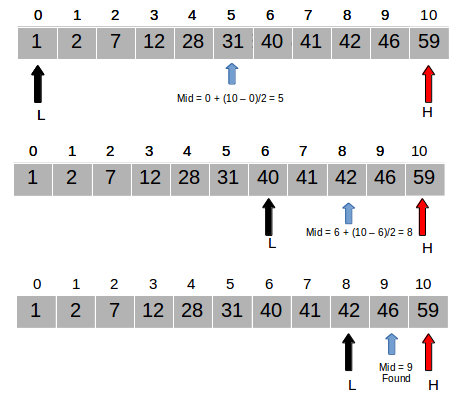
3) 이진검색(Binary Search)
키워드 : 일정한 규칙으로 늘어놓은 데이터 집합에서 빠른 검색 수행
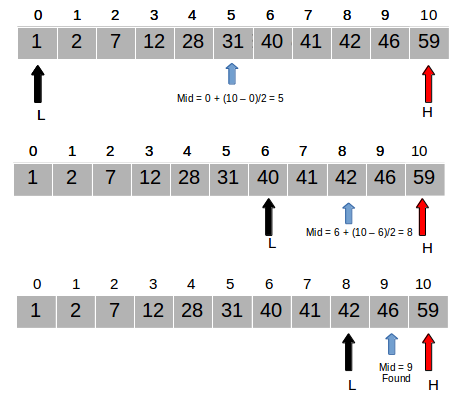
from typing import Any, Sequence
def bin_search(a: Sequence, key: Any) -> int:
"""시퀀스 a에서 key와 일치하는 원소를 이진 검색"""
pl = 0 # 검색 범위 맨 앞 원소의 인덱스
pr = len(a) - 1 # 검색 범위 맨 끝 원소의 인덱스
while True:
pc = (pl + pr) // 2 # 중앙 원소의 인덱스
if a[pc] == key:
return pc # 검색 성공
elif a[pc] < key:
pl = pc + 1 # 검색 범위를 뒤쪽의 절반으로 좁힘
else:
pr = pc - 1 # 검색 범위를 앞쪽의 절반으로 좁힘
if pl > pr:
break
return -1 # 검색 실패
if __name__ == '__main__':
num = int(input('원소 수를 입력하세요.: '))
x = [None] * num # 원소 수가 num인 배열을 생성
print('배열 데이터를 오름차순으로 입력하세요.')
x[0] = int(input('x[0]: '))
for i in range(1, num):
while True:
x[i] = int(input(f'x[{i}]: '))
if x[i] >= x[i - 1]:
break
ky = int(input('검색할 값을 입력하세요.: ')) # 검색할 ky를 입력
idx = bin_search(x, ky) # ky와 같은 값의 원소를 x에서 검색
if idx < 0:
print('검색값을 갖는 원소가 존재하지 않습니다.')
else:
print(f'검색값은 x[{idx}]에 있습니다.')시간복잡도
O(log N)
4) 해시 (Hash)
키워드 : 추가, 삭제가 일어나는 데이터 집합에서 빠른 검색을 수행함
정렬된 배열에서 원소 추가 삭제의 경우 시간복잡도 : O(N)
의 문제점을 보완한 자료구조!
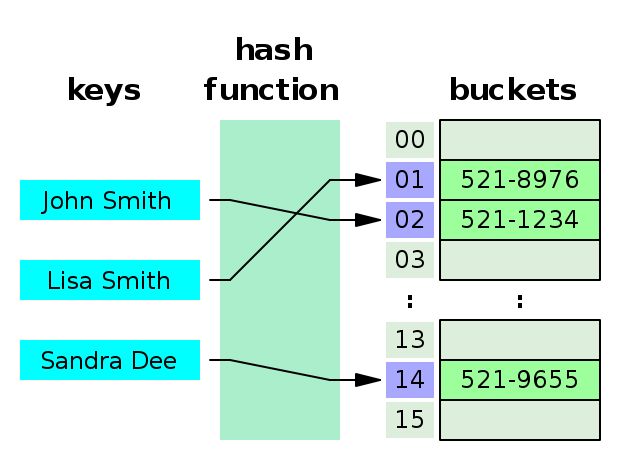
Hash, Hash Table이란 (Key, Value)로 데이터를 저장하는 자료구조
각각의 key값에 해시함수를 적용해 배열의 고유한 index를 생성하고, 이를 활용해 값을 저장/검색
내부적인 배열(버킷)을 이용해 데이터를 저장하기 때문에 빠른 검색속도를 보장하면서도, 데이터의 추가, 삭제 역시 안정적
시간복잡도
O(1)
해시값이 충돌하는 경우 (= key에 대해 hash function을 적용했을때, 이미 해당 인덱스의 bucket에 value가 존재하는 경우)를 충돌(collision)이 발생했다고 표현함
Collision 해결방법
1) Chaining
해시값이 같은 원소를 linked list로 관리
2) Open Addressing
해시테이블의 공간을 활용하는 방법
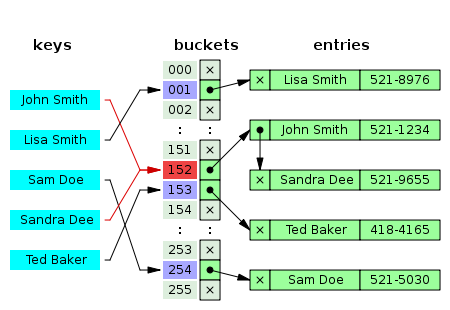
배열의 각 버킷에는 해시값이 같은 노드를 연결한 리스트의 앞쪽 노드를 참조하는 버킷을 저장
# 체인법으로 해시 함수 구현하기
# Do it! 실습 3-5 [A]
from __future__ import annotations
from typing import Any, Type
import hashlib
class Node:
"""해시를 구성하는 노드"""
def __init__(self, key: Any, value: Any, next: Node) -> None:
"""초기화"""
self.key = key # 키
self.value = value # 값
self.next = next # 뒤쪽 노드를 참조
# Do it! 실습 3-5 [B]
class ChainedHash:
"""체인법을 해시 클래스 구현"""
def __init__(self, capacity: int) -> None:
"""초기화"""
self.capacity = capacity # 해시 테이블의 크기를 지정
self.table = [None] * self.capacity # 해시 테이블(리스트)을 선언
def hash_value(self, key: Any) -> int:
"""해시값을 구함"""
if isinstance(key, int):
return key % self.capacity
return(int(hashlib.sha256(str(key).encode()).hexdigest(), 16) % self.capacity)
# Do it! 실습 3-5[C]
def search(self, key: Any) -> Any:
"""키가 key인 원소를 검색하여 값을 반환"""
hash = self.hash_value(key) # 검색하는 키의 해시값
p = self.table[hash] # 노드를 노드
while p is not None:
if p.key == key:
return p.value # 검색 성공
p = p.next # 뒤쪽 노드를 주목
return None # 검색 실패
def add(self, key: Any, value: Any) -> bool:
"""키가 key이고 값이 value인 원소를 삽입"""
hash = self.hash_value(key) # 삽입하는 키의 해시값
p = self.table[hash] # 주목하는 노드
while p is not None:
if p.key == key:
return False # 삽입 실패
p = p.next # 뒤쪽 노드에 주목
temp = Node(key, value, self.table[hash])
self.table[hash] = temp # 노드를 삽입
return True # 삽입 성공
# Do it! 실습 3-5[D]
def remove(self, key: Any) -> bool:
"""키가 key인 원소를 삭제"""
hash = self.hash_value(key) # 삭제할 키의 해시값
p = self.table[hash] # 주목하고 있는 노드
pp = None # 바로 앞 주목 노드
while p is not None:
if p.key == key: # key를 발견하면 아래를 실행
if pp is None:
self.table[hash] = p.next
else:
pp.next = p.next
return True # key 삭제 성공
pp = p
p = p.next # 뒤쪽 노드에 주목
return False # 삭제 실패(key가 존재하지 않음)
def dump(self) -> None:
"""해시 테이블을 덤프"""
for i in range(self.capacity):
p = self.table[i]
print(i, end='')
while p is not None:
print(f' → {p.key} ({p.value})', end='') # 해시 테이블에 있는 키와 값을 출력
p = p.next
print()2-1) Linear Probing
: 현재의 버킷 index로부터 고정폭 만큼씩 이동하여 차례대로 검색해 비어 있는 버킷에 데이터를 저장한다.
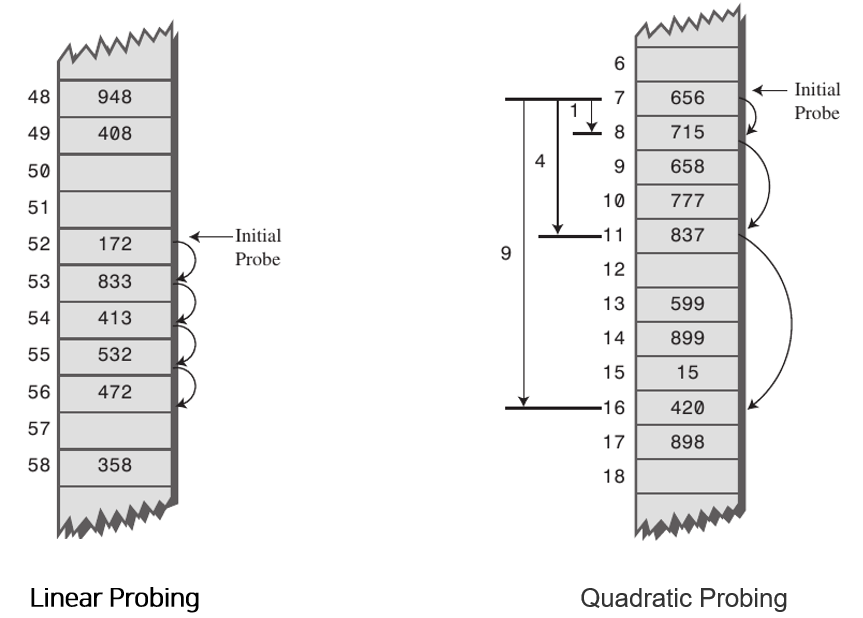
2-2) Quadratic Probing
: 해시의 저장순서 폭을 제곱으로 저장하는 방식이다. 예를 들어 처음 충돌이 발생한 경우에는 1만큼 이동하고 그 다음 계속 충돌이 발생하면 2^2, 3^2 칸씩 옮기는 방식이다.
2-3) Double Hashing Probing
: 해시된 값을 한번 더 해싱하여 해시의 규칙성을 없애버리는 방식이다. 해시된 값을 한번 더 해싱하여 새로운 주소를 할당하기 때문에 다른 방법들보다 많은 연산을 하게 된다.

# Do it! 실습 3-7 오픈 주소법으로 해시함수 구현하기
from __future__ import annotations
from typing import Any, Type
from enum import Enum
import hashlib
# 버킷의 속성
class Status(Enum):
OCCUPIED = 0 # 데이터를 저장
EMPTY = 1 # 비어 있음
DELETED = 2 # 삭제 완료
class Bucket:
"""해시를 구성하는 버킷"""
def __init__(self, key: Any = None, value: Any = None,
stat: Status = Status.EMPTY) -> None:
"""초기화"""
self.key = key # 키
self.value = value # 값
self.stat = stat # 속성
def set(self, key: Any, value: Any, stat: Status) -> None:
"""모든 필드에 값을 설정"""
self.key = key # 키
self.value = value # 값
self.stat = stat # 속성
def set_status(self, stat: Status) -> None:
"""속성을 설정"""
self.stat = stat
class OpenHash:
"""오픈 주소법을 구현하는 해시 클래스"""
def __init__(self, capacity: int) -> None:
"""초기화"""
self.capacity = capacity # 해시 테이블의 크기를 지정
self.table = [Bucket()] * self.capacity # 해시 테이블
def hash_value(self, key: Any) -> int:
"""해시값을 구함"""
if isinstance(key, int):
return key % self.capacity
return(int(hashlib.md5(str(key).encode()).hexdigest(), 16)
% self.capacity)
def rehash_value(self, key: Any) -> int:
"""재해시값을 구함"""
return(self.hash_value(key) + 1) % self.capacity
def search_node(self, key: Any) -> Any:
"""키가 key인 버킷을 검색"""
hash = self.hash_value(key) # 검색하는 키의 해시값
p = self.table[hash] # 버킷을 주목
for i in range(self.capacity):
if p.stat == Status.EMPTY:
break
elif p.stat == Status.OCCUPIED and p.key == key:
return p
hash = self.rehash_value(hash) # 재해시
p = self.table[hash]
return None
def search(self, key: Any) -> Any:
"""키가 key인 갖는 원소를 검색하여 값을 반환"""
p = self.search_node(key)
if p is not None:
return p.value # 검색 성공
else:
return None # 검색 실패
def add(self, key: Any, value: Any) -> bool:
"""키가 key이고 값이 value인 요소를 추가"""
if self.search(key) is not None:
return False # 이미 등록된 키
hash = self.hash_value(key) # 추가하는 키의 해시값
p = self.table[hash] # 버킷을 주목
for i in range(self.capacity):
if p.stat == Status.EMPTY or p.stat == Status.DELETED:
self.table[hash] = Bucket(key, value, Status.OCCUPIED)
return True
hash = self.rehash_value(hash) # 재해시
p = self.table[hash]
return False # 해시 테이블이 가득 참
def remove(self, key: Any) -> int:
"""키가 key인 갖는 요소를 삭제"""
p = self.search_node(key) # 버킷을 주목
if p is None:
return False # 이 키는 등록되어 있지 않음
p.set_status(Status.DELETED)
return True
def dump(self) -> None:
"""해시 테이블을 덤프"""
for i in range(self.capacity):
print(f'{i:2} ', end='')
if self.table[i].stat == Status.OCCUPIED:
print(f'{self.table[i].key} ({self.table[i].value})')
elif self.table[i].stat == Status.EMPTY:
print('-- 미등록 --')
elif self.table[i] .stat == Status.DELETED:
print('-- 삭제 완료 --')