
들어가며
캡스톤 주제인 “서울특별시 폐수거함 위치 정보 제공 서비스”는 폐수거함을 유형별로 조회하는 것이 메인 기능이다. 프로젝트에서 사용하는 폐수거함(일반 쓰레기통, 재활용 쓰레기통, 의류수거함, 폐건전지 수거함, 폐형광등 수거함, 폐의약품 수거함) 데이터들은 모두 공공데이터포털에서 가져오고 있다. 수집한 6개의 폐수거함 데이터의 갯수는 총 15671개이고, 아래와 같이 전처리 후에 14200개 데이터가 데이터베이스에 적재하였다.
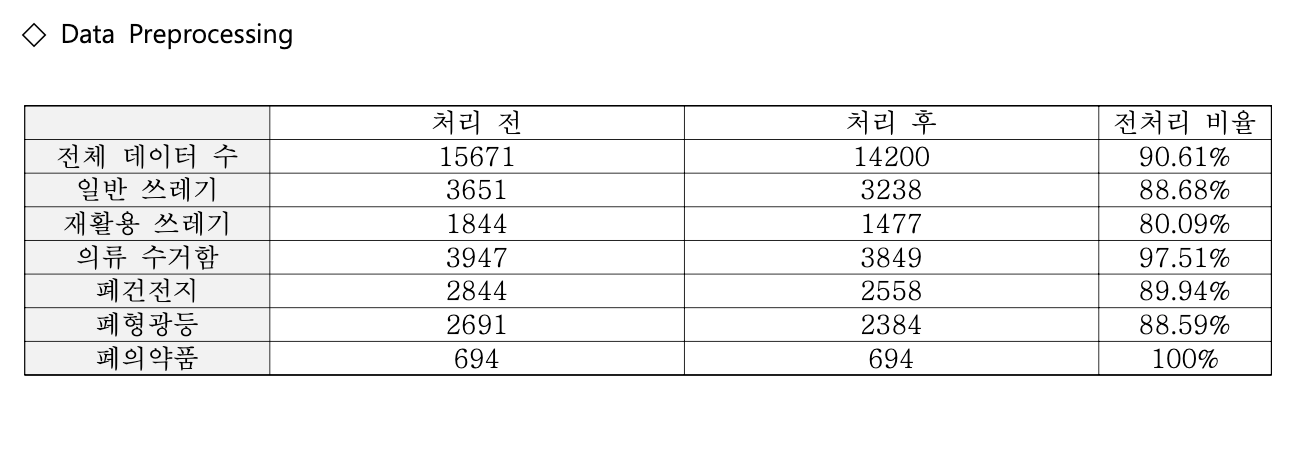
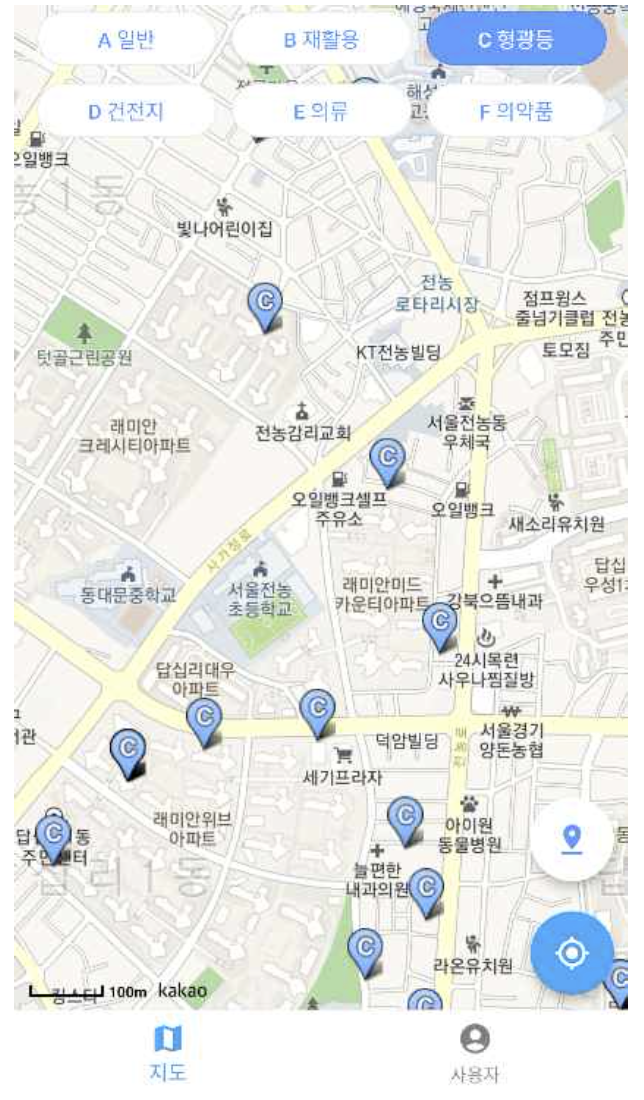
위 화면은 폐수거함을 유형별로 조회하는 화면이다. 의류수거함을 선택하고 조회했을 때 전체 3849개의 의류수거함 데이터를 한꺼번에 가져오게 된다.
이 데이터들은 업데이트가 자주 이루어지지도 않고 자주 호출되는 데이터이기 때문에 계속 DB에 가서 데이터를 가져올 필요가 없다고 생각하였고 데이터양이 많기 때문에 사용자가 불편함을 느낄 수도 있기 때문에 캐시를 활용해서 조회 속도를 개선해보았다.
캐시란?
캐시란 복잡한 연산이나 오래 걸리는 연산을 미리 수행하여 결과 값을 저장해놓고 빠르게 사용하는 것이다. 캐시의 접근 시간에 비해 원래 데이터를 접근하는 시간이 오래 걸리는 경우나 값을 다시 계산하는 시간을 절약하고 싶은 경우(반복적으로 동일한 결과를 돌려주는 경우)에 사용한다.
캐시를 사용하기에 적합한 데이터
- 동일한 데이터를 반복적으로 제공해야하는 경우
- 데이터의 변경주기가 빈번하지 않고, 처리 시간이 오래걸리는 경우
폐수거함 데이터들은 공공데이터포털에서 가져온 인증된 데이터들이다. 이를 삭제하거나 추가하는 경우는 서비스 내에서 사용자들의 제보에 의해서만 이루어지는데, 이는 빈번하게 이루어지는 작업이 아니다. 그 이유는 사용자 제보가 쌓였을 때 매일 자정에 스케쥴러에 의해서 삭제나 추가가 수행되기 때문에 캐시를 사용하기 적합하다고 생각한다. 또한 이 데이터들은 조회를 원하는 사용자들에게 반복적으로 제공되기 때문에 폐수거함을 읽어온 조회 결과를 캐시 메모리에 저장해둔다면 매번 DB로부터 호출하지 않고 데이터를 가져올 수 있기 때문에 효율적인 READ가 가능하다고 생각하였다.
캐시 전략 선택
어떤 캐시 전략이 우리 프로젝트에 적합한지 살펴보았다.
Local Cache vs Global Cache
캐시의 종류에는 크게 두 가지가 존재한다.
- Local Cache
- 서버 내부 저장소에 캐시 데이터를 저장하는 것
- 속도는 빠르지만 특정 서버에 종속되기 때문에 멀티 서버 환경에서는 서버 간의 데이터 공유가 안된다는 단점이 있다. 예를 들어, 사용자가 같은 리소스에 대한 요청을 반복해서 보내더라도, A 서버에서는 이전 데이터를, B 서버에서는 최신 데이터를 반환하여 각 캐시가 서로 다른 상태를 가질 수도 있다는 것이다. 즉, 데이터의 일관성 문제가 발생할 수 있고 동기화가 속도에 영향을 줄 수 있다. 또한 서버별로 중복된 캐시 데이터를 가지고 있기 때문에 서버 자원 낭비의 단점도 가지고 있다.
- Global Cache
- 독립적인 캐시 서버로 구축되어 네트워크 통신으로 서버들이 데이터에 접근하는 것
- 캐시 데이터를 얻기 위해서는 네트워크 트래픽을 발생시켜야하기 때문에 Local Cache보다 속도가 느리지만, 서버간 데이터를 쉽게 공유할 수 있다.따라서 Local Cache의 데이터 정합성 문제와 중복된 캐시 데이터로 인한 서버 자원 낭비 등의 문제점을 해결할 수 있다.
Local Cache 선택
Global Cache를 사용하는 것은 오버스펙이라고 판단했고, 현재 하나의 서버만을 사용하고 있고 더 빠른 응답 속도 원하기 때문에 SpringBoot에서 제공해주는 여러 캐시를 비교하여 Local Cache를 사용하기로 하였다.
SpringBoot에서는 고맙게도 기본 캐시 기능을 제공해준다. 스프링부트 애플리케이션을 실행하면 해당 애플리케이션과 함께 살아있는 캐시 공간을 사용한다. 이 캐시 공간은 메모리를 차지하므로 많은 캐시를 저장하는 것에는 적합하지 않다. 또한 이 캐시 데이터는 애플리케이션이 죽으면 없어지는 캐시 데이터이기 때문에 애플리케이션이 죽어도 캐시 데이터가 사라지지 않고 기존 캐시 데이터를 사용하고 싶으면 캐싱 서버를 두는 분산 캐싱을 해야 한다.
Caffeine cache 선택
Spring에서는 고맙게도 기본 캐시 기능을 제공해준다. 지원해주는 캐시 종류는 9가지가 있다. 스프링부트 애플리케이션을 실행하면 해당 애플리케이션과 함께 살아있는 캐시 공간을 사용한다.
Local Cache에는 Caffeine Cache 또는 Ehache가 많이 쓰이는 것 같다. 물론 ConcurrentMap으로 직접 캐시를 구현할 수 있지만, 캐시에 넣어주고 조회하고 제거하는 코드로 인해 지저분해질 수 있기 때문에 Caffeine Cache와 Ehache의 성능 비교를 통하여 선택하기로 하였다.
Caffeine cache란?

Caffeine Github wiki에서는 위와 같이 소개하고 있다. Caffeine cache는 High performance Java caching Library이다. 문서를 일겅보면 캐시와 ConcurrentMap과의 차이점에 대한 설명도 덧붙이고 있다. ConcurrentMap에 저장된 데이터는 해당 Map이 제거될 때까지 영구적으로 보관하지만, 캐시는 evict 로직이 자동으로 동작하게끔 구성된다고 한다.
Ehcache란?
Ehcache도 마찬가지로 Java 진영에서 유명한 Local Cache 라이브러리 종류 중 하나이다. 알아본 바에 따르면, Caffeine cache보다 더 많은 기능을 제공해준다. 분산 처리, Cache Listener 그리고 Off Heap에 캐싱된 데이터를 저장할 수 있다.
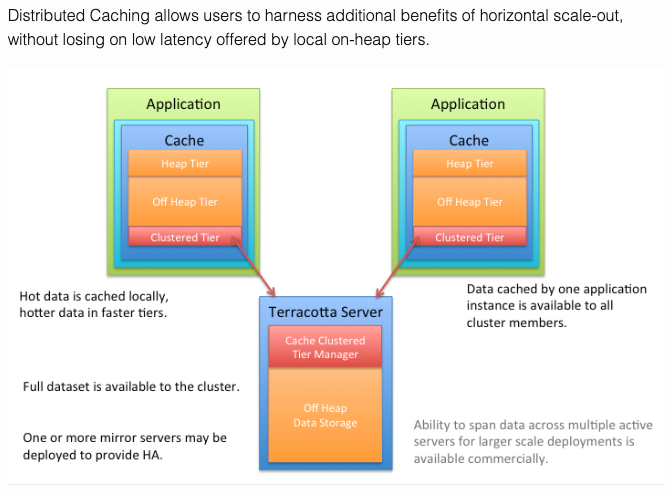
위 그림은 Ehcache 공식 문서에 있는 Distributed Caching 관련 내용이다. 각 애플리케이션에 저장되어 있는 캐시 데이터를 Terracotta Server라는 Hub 역할을 하는 분산 캐시 서버에 동기화하는 과정을 볼 수 있다.
벤치마크 자료를 통한 성능 비교
아래 자료들은 Caffeine cache GitHub wiki에서 제공하는 자료들이다.
측정 값과 단위 값들은 아래와 같다.
-
Throughput: 단위 시간당 디지털 데이터 전송으로 처리되는 양
-
ops/s: operations per second (초당 작업)
-
Read 100% 성능 측정
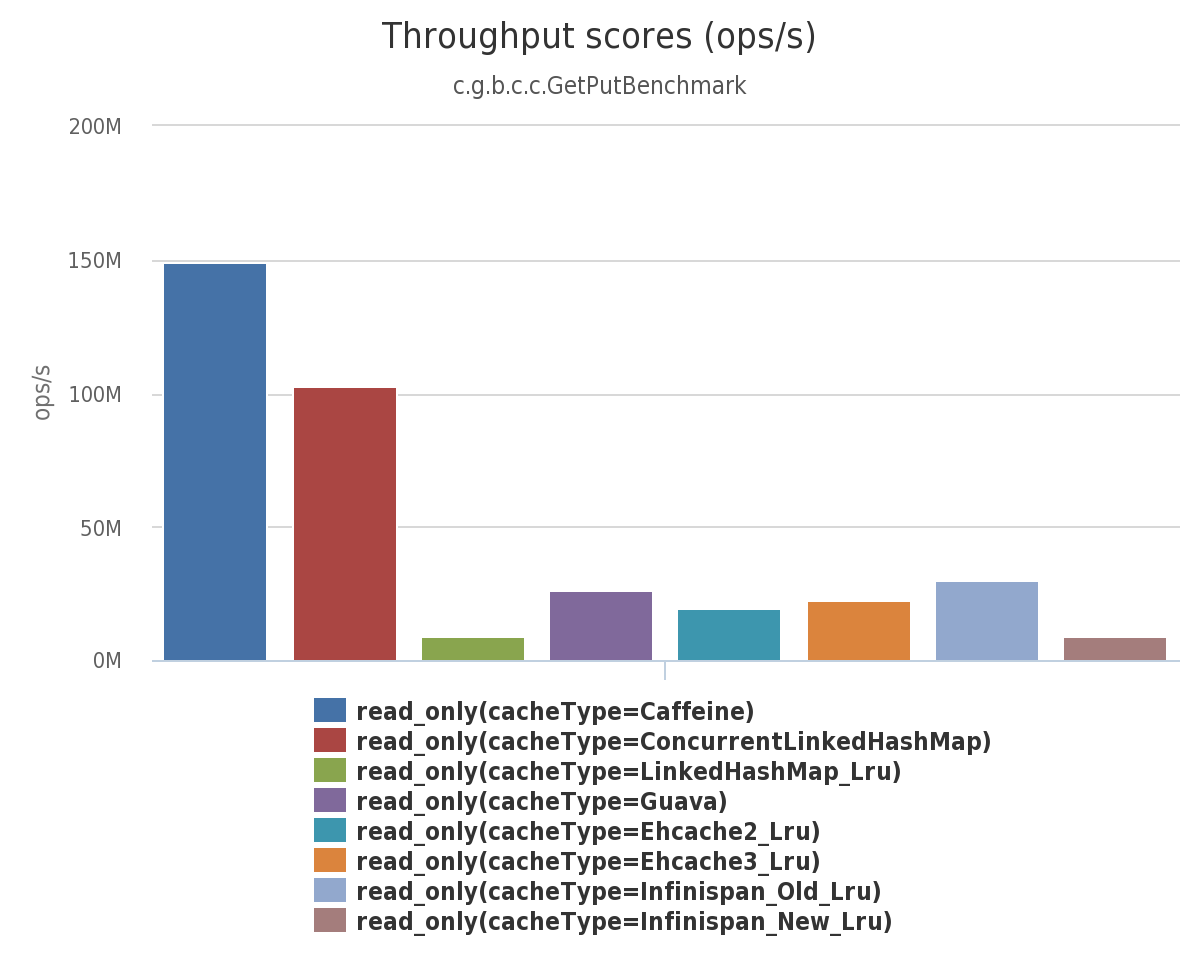
- Read 100% 성능 측정 테스트에서는 Caffeine cache가 가장 우수한 성능을 보이는 것을 알 수 있고 그 다음으로는 ConcurrentLinkedHashMap이 좋은 성능을 보여주었다.
- 위에서 알아본 Ehcache는 다소 아쉬운 성능을 보였다.
-
Read 75% & Write 25% 성능 측정
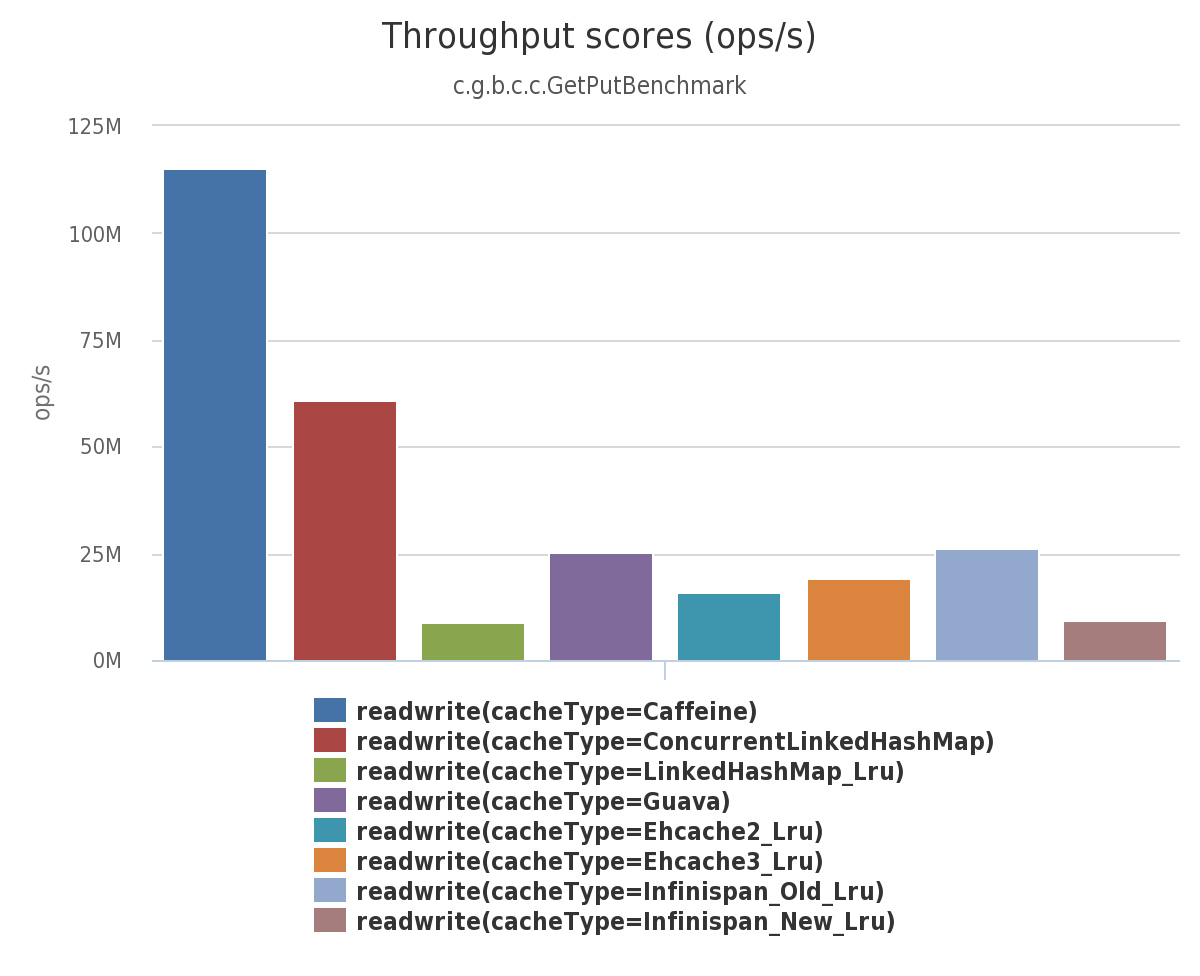
- Read 75% & Write 25% 성능 측정 테스트에서도 역시 Caffeine cache가 가장 우수한 성능을 보였고 그 다음으로도 ConcurrentLinkedHashMap이 좋은 성능을 보여주었다.
- 그러나 Read 100% 성능 측정 테스트와는 다르게 Caffeine cache와 ConcurrentLinkedHashMap의 성능 차이가 약 2배 정도 차이 나는 것을 알 수 있다.
- 위에서 알아본 Ehcache는 마찬가지로 다소 아쉬운 성능을 보였다.
-
Write 100% 성능 측정
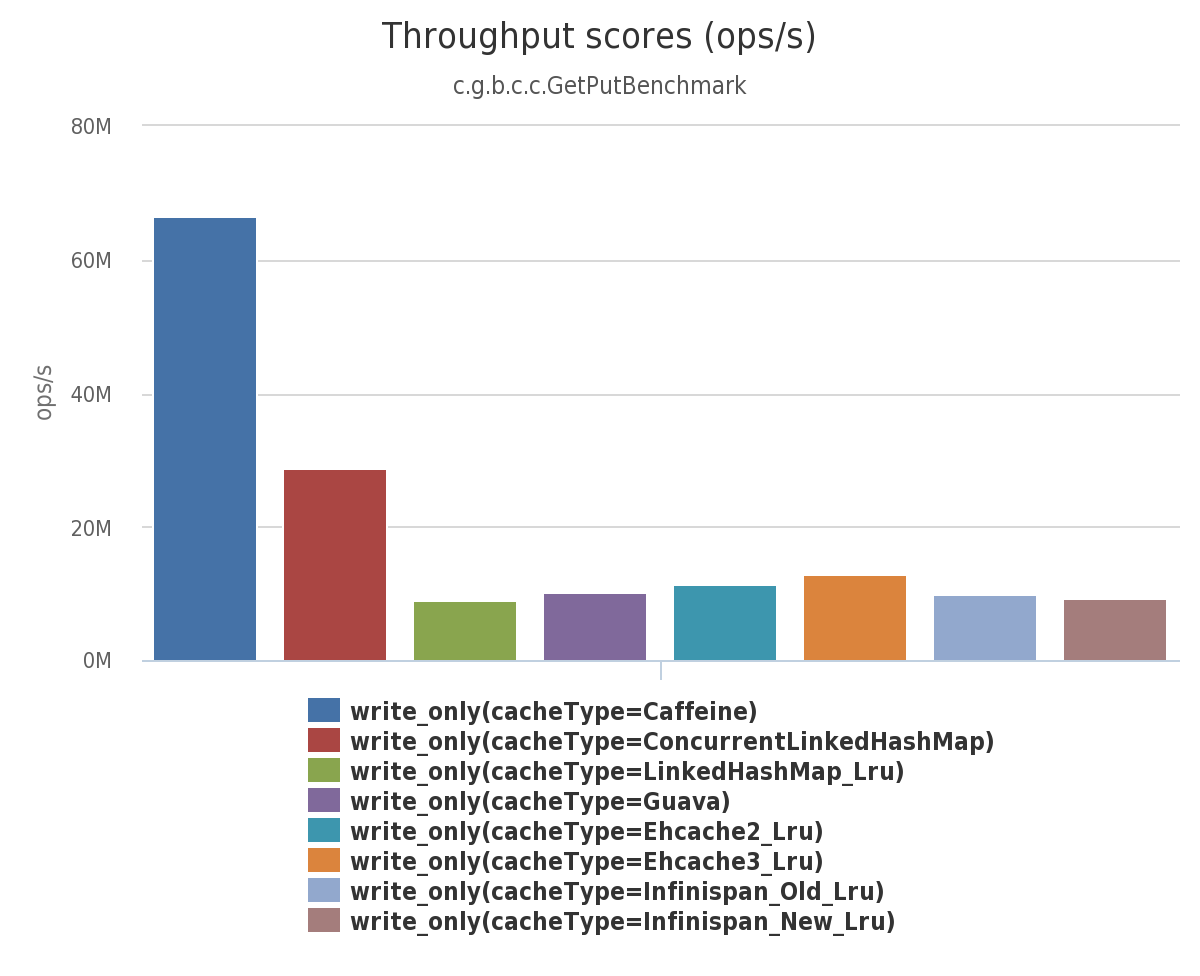
- Write 25% 성능 측정 테스트에서도 Caffeine cache가 가장 좋은 성능을 보였고 그 다음으로도 ConcurrentLinkedHashMap이 좋은 성능을 보여주었다.
- 이 테스트도 마찬가지로 Caffeine cache와 ConcurrentLinkedHashMap의 성능 차이가 약 2배 정도 차이 나는 것을 알 수 있다.
Caffeine cache는 EhCache처럼 다양한 기능을 제공하지는 않는다. 하지만 벤치마크 자료를 통해 성능 비교를 하였을 때 심플하게 메모리에 데이터를 캐싱하고 불러오는 작업만 한다면 훨씬 좋은 성능을 보인다는 것을 알 수 있다. 그러므로 우리 서비스에 적합한 Local Cache는 Caffeine cache라고 생각하여 이를 선택하였다.
Caffeine cache 적용하기
- 의존성 추가

-
캐시에 대한 Enum 정의
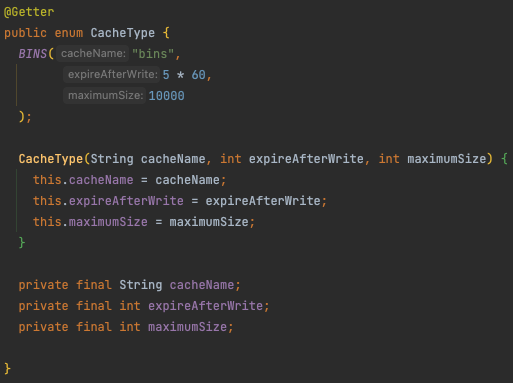
- 생성자로 각각 캐시 이름(
@Cacheable에서 정의한 이름)과 만료 시간, 저장 가능한 최대 갯수를 정의하였다. - 스택오버플로우나 여러 블로그들을 보니 enum을 사용해서 캐시를 구분하는 것을 추천하길래 이렇게 사용하였다. 추후에 다른 캐시를 적용할 때 enum을 통해 편하게 확장할 수 있을 것 같다.
- 생성자로 각각 캐시 이름(
-
cacheManager를 Bean으로 등록
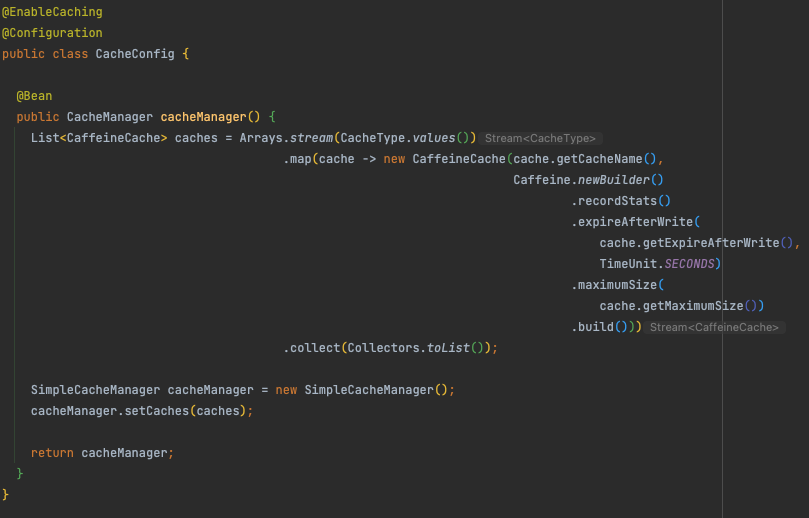
- CacheType에서 등록한 캐시들을 Caffeine 캐시 객체로 생성한 후에 SimpeCacheManager 객체에 등록하였다.
-
@Cacheable애노테이션으로 폐수거함 전체 조회 method 캐싱
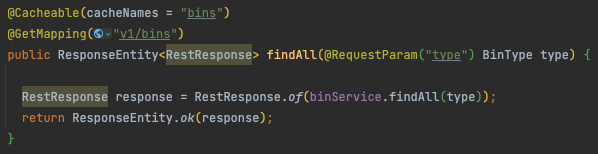
결과
데이터 갯수가 가장 많은 의류수거함 폐수거함 조회를 대상으로 테스트를 진행해보았다.
폐수거함 조회 캐시 적용 전
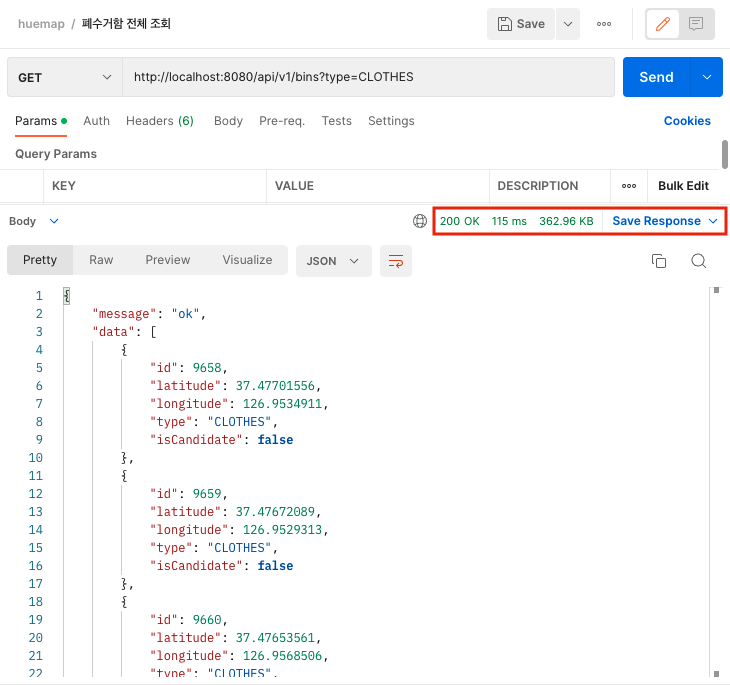
- 캐시를 적용하기 전에는 두 번째 호출부터 약 115ms 정도 걸리는 것을 알 수 있다.
폐수거함 조회 캐시 적용 후
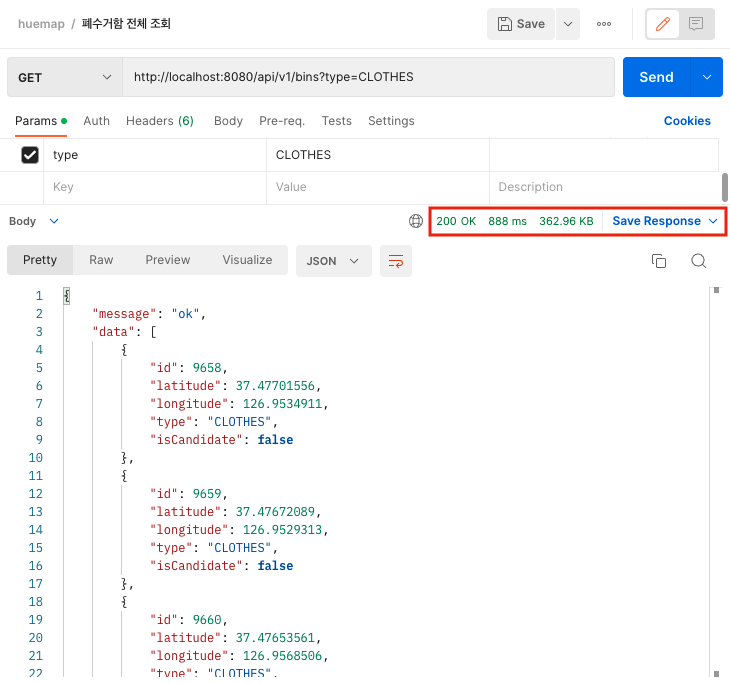
- 캐시 적용 후에 첫 번째 호출할 때는 DB에 쿼리를 날려서 캐시에 데이터를 저장한다. 응답 시간은 약 888ms정도 걸린 것을 알 수 있다.
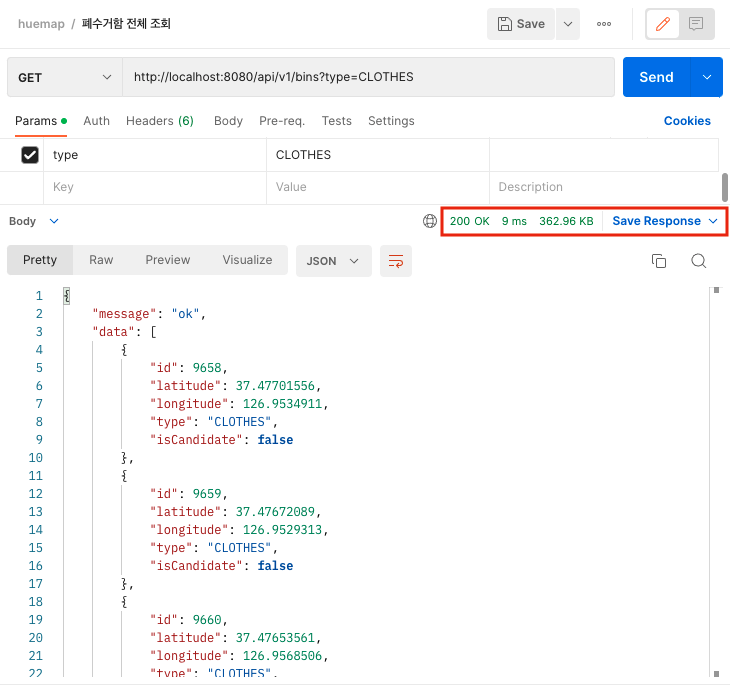
- 다시 한 번 api를 호출해보았을 때의 응답이다. 두 번째 호출부터 응답 시간은 약 9ms 정도 걸리는 것을 알 수 있다.
결론
동일한 데이터를 반복적으로 제공하고 업데이트되는 일이 잘 일어나지 않은 폐수거함 데이터들을 Caffeine cache를 통해 캐싱해보았다. 그 결과 응답속도 115ms → 9ms 로 감소 시키는 효과를 거두었다.
참고
Home · ben-manes/caffeine Wiki
