
개발자라면 누구나 매일같이 웹과 씨름합니다. 프론트엔드든 백엔드든, API 호출 한 번, 웹페이지 로딩 한 번에도 어김없이 등장하는 기술이 바로 DNS와 HTTP죠. 너무 당연하게 사용하다 보니 깊게 들여다볼 기회가 없었을 수도 있지만, 이 둘의 작동 원리를 이해하는 것은 웹 기반 시스템의 성능 개선, 트러블슈팅, 그리고 안정적인 서비스 구축에 생각보다 큰 영향을 미칩니다.
이번 글에서는 웹 통신의 근간을 이루는 DNS와 HTTP의 핵심, 그리고 자주 혼용되는 URI, URL, URN의 차이와 HTTP 버전별 특징까지 다시 한번 짚어보겠습니다. 이미 알고 있는 내용이라도 리마인드하는 느낌으로 가볍게 읽어보시면 좋을 것 같네요.
1. DNS: 이름 뒤에 숨은 주소를 찾아서
우리는 api.example.com 같은 도메인 이름으로 서버에 접속하지만, 실제 네트워크 통신은 IP 주소(172.16.10.5 같은)를 기반으로 이루어집니다. DNS(Domain Name System)는 이 도메인 이름을 IP 주소로 바꿔주는 일종의 분산된 데이터베이스 시스템입니다. 없으면 인터넷 사용 자체가 거의 불가능하죠.
그럼, www.google.com을 입력하면 무슨 일이 벌어질까요?
매번 일어나는 일이지만, 그 과정은 꽤 여러 단계를 거칩니다.
- 로컬 캐시 확인: 가장 먼저 내 PC(브라우저 캐시, OS 캐시)나 내부 네트워크의
hosts파일에 해당 도메인의 IP 정보가 있는지 뒤져봅니다. 있으면 여기서 바로 끝나죠. (캐시 만세!) - Local DNS 서버(리졸버)에게 질문: 캐시에 없다면, 보통 통신사(ISP)에서 제공하는 Local DNS 서버(얘를 리졸버라고 부릅니다)에게 물어봅니다. 리졸버도 자체 캐시를 가지고 있어서, 최근에 누군가 같은 걸 물어봤다면 바로 답을 줄 수 있습니다.
- Root → TLD → Authoritative 서버로 이어지는 여정: 리졸버에도 정보가 없다면, 이제 본격적인 여정이 시작됩니다.
- 리졸버는 전 세계 13개뿐인 Root 네임 서버에게 ".com 도메인은 누가 관리해?"라고 묻습니다.
- Root 서버는 ".com 담당" TLD(최상위 도메인) 네임 서버 주소를 알려줍니다.
- 리졸버는 다시 TLD 네임 서버에게 가서 "google.com은 누가 관리해?"라고 묻습니다.
- TLD 서버는 "google.com"을 실제 관리하는 권한 있는(Authoritative) 네임 서버 주소를 알려줍니다.
- 드디어 리졸버는 권한 있는 네임 서버에게 "www.google.com의 IP 주소 뭐야?"라고 물어보고, 최종 IP 주소를 받아옵니다.
- 결과 전달 및 캐싱: 리졸버는 알아낸 IP 주소를 우리 PC에게 전달해주고, 다음번을 위해 이 정보를 캐시에 저장합니다.
이 과정 덕분에 우리는 복잡한 IP 대신 편리한 도메인 이름을 사용할 수 있는 거죠. 서비스가 느리거나 접속이 안 될 때 nslookup이나 dig 같은 명령어로 DNS 조회가 제대로 되는지 확인해보는 게 트러블슈팅의 기본 중 하나입니다.
DNS 레코드: 단순 IP 매핑 그 이상
DNS는 도메인과 IP 주소(IPv4는 A, IPv6는 AAAA 레코드) 매핑 외에도 다양한 정보를 관리합니다. 개발하다 보면 종종 마주치는 레코드 타입들이 있죠.
A: 도메인 이름에 대한 IPv4 주소AAAA: 도메인 이름에 대한 IPv6 주소CNAME: 특정 도메인을 다른 도메인의 별칭으로 사용하고 싶을 때 (예:blog.example.com을gh-pages.github.io로 연결)MX: 이메일을 어떤 서버로 보내야 하는지 알려줄 때 (메일 서버 설정 시 필수)TXT: 도메인 소유 확인이나 이메일 보안(SPF, DKIM) 설정 등에 임의의 텍스트 값을 넣을 때
서비스 도메인을 세팅하거나, 서드파티 서비스(메일 발송, CDN 등)를 연동할 때 이런 레코드들을 직접 만지게 되는 경우가 많습니다.
자원을 식별하는 이름: URI, URL, URN
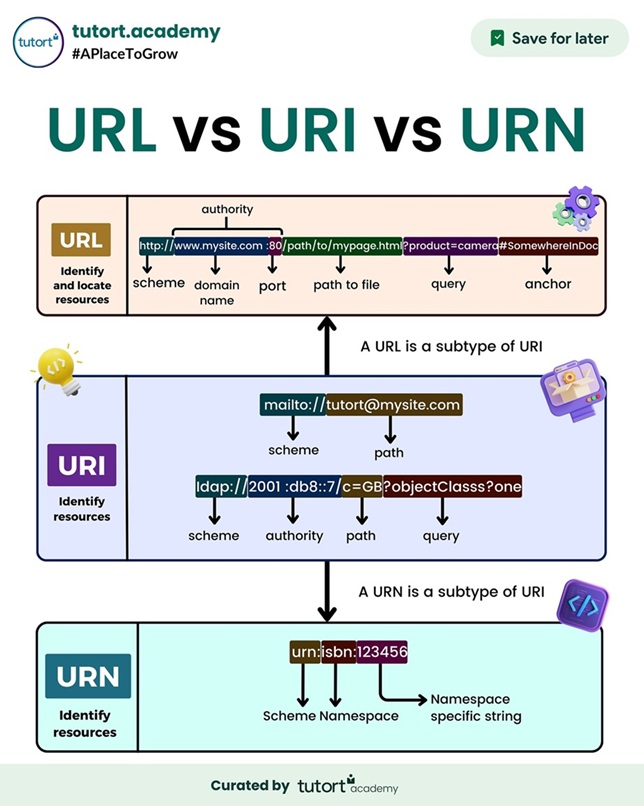
우리는 웹상의 자원(Resource, 예: 웹 페이지, 이미지, API 엔드포인트 등)에 접근하기 위해 주소를 사용합니다. 이때 URI, URL, URN이라는 용어가 등장하는데, 이들의 관계를 명확히 이해해 봅시다.
-
URI (Uniform Resource Identifier: 통합 자원 식별자)
- 인터넷 상의 자원을 고유하게 식별하는 문자열입니다. 가장 포괄적인 개념이죠.
- 자원을 식별하기만 하면 되므로, 그 자원이 어디에 있는지(위치)나 어떻게 접근하는지(방법) 정보는 포함하지 않을 수도 있습니다.
- URL과 URN은 모두 URI의 하위 집합입니다. 즉, 모든 URL과 URN은 URI입니다.
- 예시:
https://example.com/path,mailto:user@example.com,urn:isbn:9780134685991
-
URL (Uniform Resource Locator: 통합 자원 위치 지정자)
- 자원이 어디에 있는지(위치) 를 알려주는 URI입니다. 즉, 자원에 접근하는 방법(프로토콜)과 위치(주소)를 명시합니다.
- 우리가 흔히 '웹 주소'라고 부르는 대부분이 URL에 해당합니다.
- 프로토콜(
http,https,ftp등), 호스트 주소, 경로 등을 포함합니다. - 예시:
https://www.google.com,ftp://example.com/download/file.zip
-
URN (Uniform Resource Name: 통합 자원 이름)
- 자원의 이름을 부여하여 고유하게 식별하는 URI입니다. 위치 정보는 포함하지 않습니다.
- 자원의 위치가 변경되더라도 이름 자체는 변하지 않는 영구적인 식별자를 제공하는 것을 목표로 합니다.
urn:스키마를 사용하며, ISBN(국제 표준 도서 번호)이나 UUID 등이 대표적인 예입니다.- URL에 비해 실생활에서 널리 사용되지는 않습니다.
- 예시:
urn:isbn:9780134685991,urn:uuid:6e8bc430-9c3a-11d9-9669-0800200c9a66
결론적으로, URI는 식별자(Identifier)이고 URL은 위치(Locator), URN은 이름(Name)입니다. 웹 개발에서는 주로 자원의 위치를 나타내는 URL을 다루게 되지만, 이들의 관계를 이해하고 있으면 기술 문서를 읽거나 커뮤니케이션할 때 더 명확하게 소통할 수 있습니다.
URL 구조 상세 보기
이제 우리가 가장 많이 사용하는 URL의 구조를 자세히 살펴보겠습니다.
scheme://host[:port]/path[?query][#fragment]
- scheme: 사용할 프로토콜 (
http,https,ftp등) - host: 자원이 위치한 서버의 도메인 이름 또는 IP 주소
- port: 서버 접속 포트 번호 (http는 80, https는 443이 기본이며 생략 가능)
- path: 서버 내 자원의 경로 (예:
/users/1) - query: 서버에 전달하는 추가적인 파라미터 (
key=value형태,&로 구분. 예:?q=network&page=1) - fragment: 문서 내 특정 위치를 가리킴 (브라우저에서만 사용, 서버로 전달되지 않음. 예:
#section-2)
특히 REST API를 설계할 때 path 변수와 query 파라미터를 어떻게 활용할지 고민하게 되죠.
2. HTTP: 웹에서 클라이언트와 서버가 대화하는 법
DNS를 통해 IP 주소를 알아냈고, URL/URI를 통해 원하는 자원까지 특정했다면, 이제 클라이언트(웹 브라우저 등)와 서버는 서로 데이터를 주고받아야 합니다. 이때 사용하는 통신 규약이 바로 HTTP(HyperText Transfer Protocol)입니다.
기본적으로 요청(Request)과 응답(Response) 쌍으로 이루어집니다.
HTTP 요청 (클라이언트 → 서버)
클라이언트가 서버에게 보내는 메시지입니다. 브라우저 개발자 도구의 'Network' 탭을 열면 흔히 볼 수 있죠.
- 시작 줄 (Start Line):
[메서드] [요청 경로] [HTTP 버전]으로 구성됩니다. (예:GET /users/123 HTTP/1.1) - 헤더 (Headers): 요청에 대한 메타데이터.
Host,User-Agent,Accept,Content-Type,Authorization등이 자주 쓰입니다. API 개발 시 커스텀 헤더를 정의하기도 하죠. - 본문 (Body): 실제 전송할 데이터.
POST,PUT,PATCH요청 시 주로 사용됩니다. (예: JSON 페이로드)
HTTP 메서드 (요청의 의도)
요청의 종류를 나타냅니다. REST API 설계 시 어떤 메서드를 사용할지 결정하는 것이 중요합니다.
GET: 리소스 조회 (멱등)POST: 리소스 생성 (멱등 아님)PUT: 리소스 전체 교체 또는 생성 (멱등)PATCH: 리소스 부분 수정 (멱등성 논란 있음)DELETE: 리소스 삭제 (멱등)HEAD,OPTIONS등 기타 메서드도 특정 용도로 사용됩니다.
HTTP 응답 (서버 → 클라이언트)
서버가 요청을 처리하고 클라이언트에게 보내는 메시지입니다.
- 상태 줄 (Status Line):
[HTTP 버전] [상태 코드] [상태 메시지]로 구성됩니다. (예:HTTP/1.1 200 OK,HTTP/1.1 404 Not Found) - 헤더 (Headers): 응답 관련 메타데이터.
Content-Type,Content-Length,Set-Cookie,Location등이 대표적입니다. - 본문 (Body): 요청한 데이터(HTML, JSON, 이미지 등) 또는 오류 메시지.
HTTP 상태 코드 (요청 결과 요약)
요청 처리 결과를 알려주는 세 자리 숫자. 디버깅할 때 가장 먼저 확인하게 되는 정보 중 하나입니다.
2xx(성공):200 OK,201 Created,204 No Content등. 서버가 요청을 잘 처리했다는 의미.3xx(리다이렉션):301 Moved Permanently,302 Found,304 Not Modified등. 다른 주소로 가라고 알려주거나 캐시를 사용하라고 지시.4xx(클라이언트 오류):400 Bad Request,401 Unauthorized,403 Forbidden,404 Not Found등. 요청 자체가 잘못되었을 가능성이 높음. 클라이언트 측에서 해결해야 할 문제.5xx(서버 오류):500 Internal Server Error,502 Bad Gateway,503 Service Unavailable등. 서버 쪽에서 문제가 발생했음을 의미. 백엔드 개발자가 해결해야 할 문제.
적절한 상태 코드를 반환하는 것은 잘 설계된 API의 기본 소양과도 같습니다.
HTTP의 주요 특징: Stateless & Connectionless
- Stateless (무상태성): 각 HTTP 요청은 이전 요청과 독립적입니다. 서버는 클라이언트의 상태를 저장하지 않죠. 이 덕분에 서버를 수평적으로 확장하기 쉽지만, 로그인 상태 유지 등을 위해서는 쿠키, 세션, 토큰(JWT 등) 같은 추가적인 매커니즘이 필요합니다.
- Connectionless (비연결성): 기본적으로 요청/응답 한 번 주고받으면 연결을 끊습니다. (HTTP/1.1의 Keep-Alive나 HTTP/2에서는 개선되었지만 기본적인 특성) 서버 자원을 아낄 수 있지만, 연결 설정 오버헤드가 발생할 수 있습니다.
HTTP/1.1, HTTP/2, HTTP/3: 무엇이 달라졌을까?
우리가 사용하는 HTTP도 계속 발전해왔습니다. 각 버전의 주요 특징과 개선점을 알아두면 웹 성능 최적화 관점에서 도움이 됩니다.
HTTP/1.1 (1997년)
- 텍스트 기반 프로토콜: 사람이 읽기 쉬운 텍스트 형식으로 메시지를 주고받습니다.
- 연결 유지 (Keep-Alive): 한 번 맺은 TCP 연결을 재사용하여 매번 연결하는 비용을 줄였습니다.
- 파이프라이닝 (Pipelining): 이론적으로는 하나의 연결에서 여러 요청을 보내고 순서대로 응답을 받을 수 있었지만, 구현 문제와 HOL Blocking 문제로 실제로는 거의 사용되지 못했습니다.
- 단점: HOL (Head-of-Line) Blocking: 하나의 TCP 연결에서는 요청을 보낸 순서대로 응답을 받아야 합니다. 그래서 앞선 요청 처리가 늦어지면 뒤따르는 모든 요청이 대기해야 하는 문제가 발생합니다. 이를 해결하기 위해 브라우저는 보통 도메인당 여러 개의 TCP 연결(보통 6개)을 생성하는데, 이는 리소스 낭비입니다.
- 단점: 비효율적인 헤더: 매 요청/응답마다 헤더가 텍스트 형태로 중복 전송되어 불필요한 오버헤드가 큽니다. (특히 쿠키 등이 포함되면 더 커짐)
HTTP/2 (2015년)
HTTP/1.1의 성능 한계를 극복하기 위해 등장했습니다.
- 바이너리 프로토콜: 메시지를 텍스트가 아닌 바이너리 프레임(Frame) 단위로 나누어 처리합니다. 파싱이 빠르고 오류 발생 가능성이 낮아집니다.
- 멀티플렉싱 (Multiplexing): 핵심 개선점! 하나의 TCP 연결 위에서 여러 개의 요청과 응답(Stream)을 동시에, 순서에 상관없이 주고받을 수 있습니다. 덕분에 HTTP/1.1의 HOL Blocking 문제가 해결되고 TCP 연결 수를 줄일 수 있습니다.
- 스트림 우선순위 (Stream Prioritization): 리소스(Stream) 간의 우선순위를 정해 중요한 리소스를 먼저 받을 수 있습니다.
- 서버 푸시 (Server Push): 클라이언트가 요청하지 않았지만 곧 필요할 것 같은 리소스(예: CSS, JS)를 서버가 미리 보내줄 수 있습니다. (하지만 실제 효용성 문제로 현재는 사용이 줄어드는 추세)
- 헤더 압축 (HPACK): 헤더 정보를 효율적으로 압축하여 전송 오버헤드를 크게 줄입니다.
참고: HTTP/2는 HTTP 계층에서의 HOL Blocking은 해결했지만, 여전히 TCP 계층의 HOL Blocking 문제(패킷 손실 시 해당 TCP 연결 전체가 지연)는 가지고 있습니다.
HTTP/3 (2022년)
TCP의 한계를 넘어서기 위해 아예 전송 계층 프로토콜을 QUIC(Quick UDP Internet Connections)으로 바꾼 버전입니다. QUIC은 UDP 기반이지만 TCP의 신뢰성(패킷 재전송 등)과 TLS 1.3의 보안 기능을 내장하고 있습니다.
- QUIC 프로토콜 사용: TCP 대신 UDP 기반의 QUIC 위에서 동작합니다.
- TCP HOL Blocking 해결: QUIC은 TCP와 달리 각 스트림을 독립적으로 처리합니다. 한 스트림에서 패킷 손실이 발생해도 다른 스트림에 영향을 주지 않아 HOL Blocking 문제를 해결합니다.
- 연결 설정 속도 향상: TCP와 TLS 핸드셰이크 과정을 통합하여 연결 설정 지연(latency)을 줄입니다. (0-RTT 또는 1-RTT 연결)
- 연결 마이그레이션 (Connection Migration): 클라이언트의 IP 주소나 포트가 변경되어도(예: Wi-Fi에서 LTE로 전환) 연결이 유지됩니다.
- 강화된 보안: QUIC은 TLS 1.3 기반 암호화를 기본으로 제공합니다.
요약 비교
| 특징 | HTTP/1.1 | HTTP/2 | HTTP/3 |
|---|---|---|---|
| 기반 프로토콜 | TCP | TCP | QUIC (UDP 기반) |
| 메시지 형식 | 텍스트 | 바이너리 | 바이너리 |
| HOL Blocking | HTTP/TCP 모두 존재 | TCP 계층에 존재 | 해결 |
| 동시 전송 | 파이프라이닝 (제한적) | 멀티플렉싱 | 멀티플렉싱 (QUIC) |
| 헤더 처리 | 비압축, 중복 | HPACK 압축 | QPACK 압축 |
| 연결 설정 | TCP + TLS 핸드셰이크 (느림) | TCP + TLS 핸드셰이크 (느림) | QUIC 핸드셰이크 (빠름) |
| 암호화 | 선택 (HTTPS) | 필수 (사실상) | 필수 |
| 연결 유지 | Keep-Alive | 단일 연결 | 연결 마이그레이션 지원 |
현재 많은 웹사이트들이 HTTP/2를 사용하고 있으며, Google, Facebook 등 대규모 서비스들을 중심으로 HTTP/3 도입이 점차 확산되고 있습니다.
마무리
DNS와 HTTP는 웹 기술의 가장 바탕을 이루는 약속입니다. 여기에 URI/URL/URN 같은 자원 식별 체계, 그리고 계속 발전해 온 HTTP 버전들의 특징까지 이해하고 있다면 웹 애플리케이션을 개발하고 운영하는 데 있어 훨씬 넓은 시야를 가질 수 있습니다.
API 엔드포인트 하나를 설계하더라도 URL 구조, HTTP 메서드, 상태 코드의 의미를 고민하고, 서비스 접속이 느릴 때 DNS 문제나 네트워크 지연, 혹은 사용 중인 HTTP 버전의 한계 등을 의심해보는 등, 기본 원리에 대한 이해는 문제 해결 능력과 직결됩니다.
혹시 잘못된 내용이나 추가하고 싶은 의견이 있다면 댓글로 편하게 남겨주세요!
