안녕하세요! 메이플랜드 유저들의 자리거래를 조금이나마 편하게 만들어보고자 시작했던 프로젝트가 어느덧 런칭 2주차를 맞이했습니다.
과분한 사랑, 그리고 새로운 과제
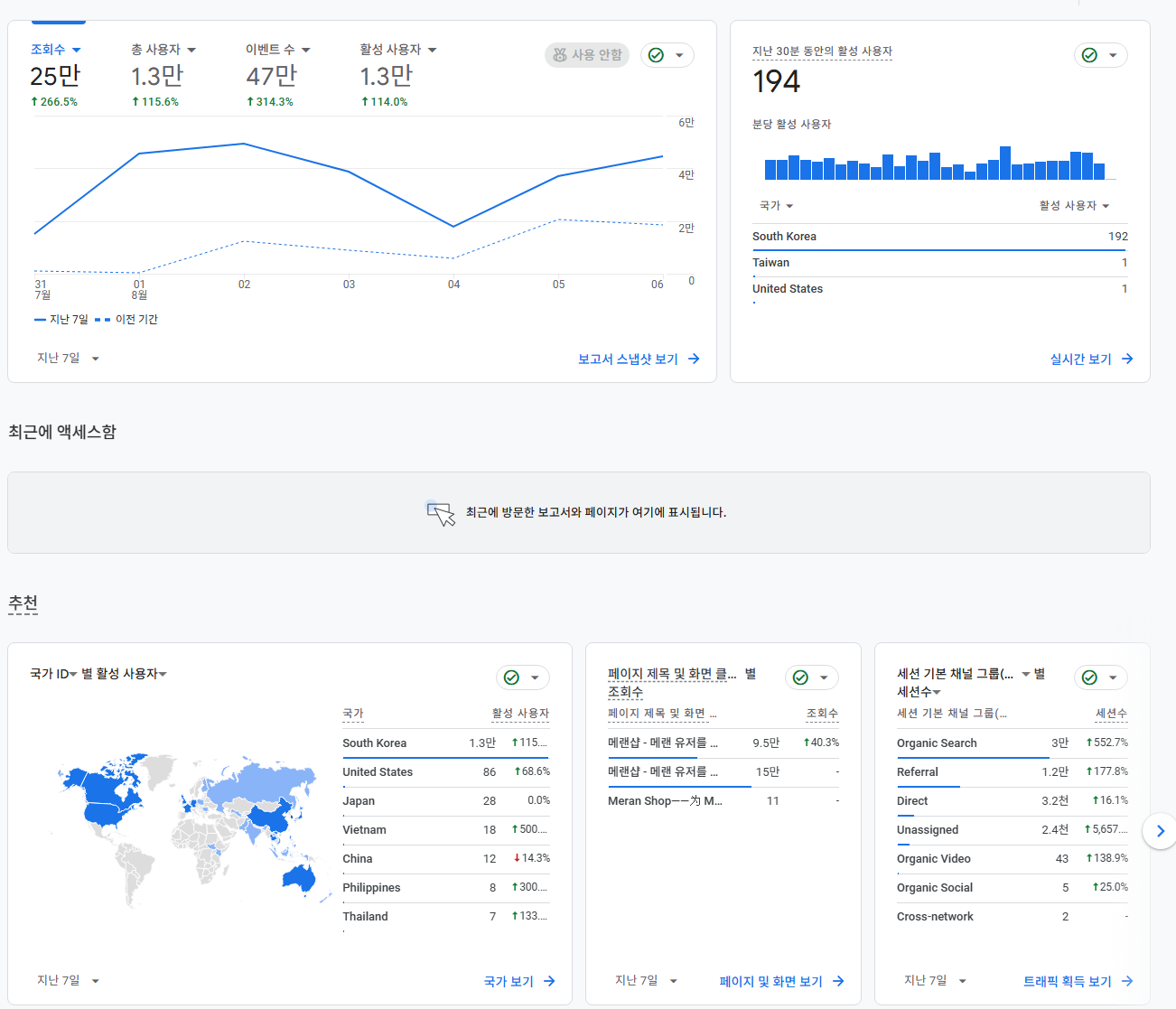
안녕하세요! 메이플랜드 유저들의 편의를 위해 시작한 작은 프로젝트 '메랜샵' 개발자입니다. 출시 2주 만에 3,600명의 사용자와 13,000명의 활성 사용자를 기록하며 정말 과분한 사랑을 받게 되었습니다.
하지만 예상보다 훨씬 많은 분들이 서비스를 이용해주시면서 새로운 과제가 눈앞에 나타났습니다. 바로 성능 최적화의 필요성이었습니다. 사용자가 늘어날수록 서비스가 조금씩 느려지는 현상을 외면할 수 없었고, 특히 많은 분들이 호평해주셨던 평균 거래 가격 계산(IQR) 기능이 데이터 증가에 따라 속도 저하의 원인이 되고 있었습니다.
더 쾌적하고 안정적인 서비스를 제공하기 위해, 성능 최적화 작업을 진행하기로 결정했습니다.
이 글의 모든 서비스명, 코드, 쿼리, 데이터, 수치, 경로는 가상의 예시이며 실제 서비스와 무관합니다.
데이터 누락 및 계산 정확성 확보
가장 먼저 해결해야 했던 문제는 데이터의 신뢰성이었습니다. 사용자들의 제보를 통해 특정 시간대의 시세 데이터가 누락되는 치명적인 이슈를 발견했습니다.
문제 상황
"3시 10분인데, 3시 데이터가 보이지 않아요."
서비스의 핵심 기능인 시세 정보가 특정 조건에서 누락되는 치명적인 이슈였습니다. 원인 분석 결과, 문제는 스케줄링과 시간 범위 계산 방식에 있었습니다.
-
스케줄링 시간: 매시 정각(0 0 * * * *)에 스케줄러가 동작했습니다. 하지만 서버 시간에 미세한 오차가 발생하거나 작업이 약간만 지연되어도 정각을 넘겨버려, 의도한 시간대의 데이터를 집계하지 못하는 경우가 생겼습니다.
-
시간 범위 계산 오류: 데이터를 조회하는 startTime과 endTime 설정 로직의 미묘한 허점으로 인해 경계값에서 데이터가 누락되었습니다.
해결 방안
1. 스케줄링 시간 조정
안정적인 데이터 집계를 위해 스케줄러 실행 시간에 1분의 여유를 두었습니다. 매시 1분에 스케줄러를 실행하여, '이전 시간대'의 데이터를 확정적으로 계산하도록 변경했습니다.
@Scheduled(cron = "0 1 * * * *") // 매시 1분 실행
public void procZetaMetrics() {
LocalDateTime now = LocalDateTime.now();
LocalDateTime targetHour = now.withMinute(0).minusHours(1);
log.info("{}시 데이터 처리 시작", targetHour.getHour());
}2. 시간 범위 계산 로직 수정
데이터를 조회할 startTime과 endTime을 명확하게 설정하여 누락이 발생하지 않도록 수정했습니다.
@Transactional(readOnly = true)
public List<CalcDto> runOmegaCalc(String key, LocalDateTime t) {
LocalDateTime endT = t.plusHours(1);
LocalDateTime startT = t.minusHours(4);
List<DummyEntity> list = repo.findByNameAndRange(key, startT, endT);
return generateStats(key, startT, endT, list);
}3. IQR 계산 로직 검증 및 개선
데이터 정확성을 높이는 김에, 핵심 로직인 IQR(사분위범위) 기반 평균 계산 로직도 다시 검증했습니다. 기존 Stream을 두 번 사용하던 비효율적인 구조를 개선하고, 분위수 계산법을 더 정확하게 다듬어 성능과 신뢰성을 모두 향상시켰습니다.
private double calcIqrAvg(List<Integer> vals) {
if (vals.size() < 5) {
return vals.stream().mapToInt(Integer::intValue).average().orElse(0);
}
List<Integer> sorted = vals.stream().sorted().toList();
int n = sorted.size();
int q1Idx = (int) Math.round((n - 1) * 0.25);
int q3Idx = (int) Math.round((n - 1) * 0.75);
double q1 = sorted.get(q1Idx);
double q3 = sorted.get(q3Idx);
double iqr = q3 - q1;
double lb = q1 - 1.5 * iqr;
double ub = q3 + 1.5 * iqr;
long sum = 0;
int cnt = 0;
for (int v : sorted) {
if (v >= lb && v <= ub) { sum += v; cnt++; }
return cnt == 0 ? 0 : (double) sum / cnt;
}이러한 개선을 통해 데이터 누락 문제를 해결하고, 가격 데이터의 신뢰도를 높였습니다. 또한, 기존에 고정된 맵 리스트만 처리하던 방식에서 벗어나 거래가 있는 모든 맵을 동적으로 발견하고 처리하는 시스템을 구축했습니다.
대규모 맵 처리로 인한 성능 저하
데이터 누락 문제는 해결했지만, 사용자가 늘면서 또 다른 문제가 발생했습니다. 거래가 있는 모든 맵을 동적으로 처리하는 시스템을 구축하자, 100개가 넘는 맵의 통계를 매시간 계산하는 작업이 서버에 큰 부담을 주기 시작했습니다.
문제 상황
- 처리 맵 개수 증가: 거래량이 많은 맵이 100개 이상으로 늘어나면서 매시간 DB 쿼리가 100회 이상 발생했습니다.
- DB 부하 및 실행 시간 증가: 모든 맵에 대한 쿼리가 동시에 실행되면서 DB에 부하가 걸리고, 스케줄러 실행 시간이 10초 이상으로 늘어났습니다.
해결 방법
모든 맵을 처리하는 대신, 최근 N시간 동안 최소 거래량을 넘긴 '활성 맵'만 선별하여 처리하도록 전략을 변경했습니다.
1. 활성 맵 선별 처리
최근 N 시간 동안 최소 거래량을 넘긴 '활성 맵'만 필터링하여 처리하도록 로직을 추가했습니다.
// 최소 거래량 기준 필터링
public Set<String> getActiveKeys(int hours, int minCount) {
LocalDateTime since = LocalDateTime.now().minusHours(hours);
return repo.findActiveKeys(since, minCount);
}이를 위해 DB 쿼리 또한 거래량을 기준으로 상위 맵만 조회하도록 최적화했습니다.
-- 거래량 기준으로 상위 맵만 조회
SELECT t.colA
FROM TBL_XYZ t
WHERE t.update_at >= :since
AND t.flag_done = true
GROUP BY t.colA
HAVING COUNT(t.colA) >= :minCount
ORDER BY COUNT(t.colA) DESC2. 최대 처리 개수 제한
혹시 모를 상황에 대비해 한 번에 처리할 맵의 최대 개수를 50개로 제한하는 안전장치를 추가했습니다.
int maxMapsToProcess = 50; // 최대 50개 맵만 처리
int processedCount = 0;
for (String mapName : activeMaps) {
if (processedCount >= maxMapsToProcess) {
log.warn("최대 처리 개수({})에 도달하여 나머지 맵 건너뛰기", maxMapsToProcess);
break;
}
// ... 처리 로직
processedCount++;
}이러한 선별적 처리 방식을 통해 전체적인 시스템 부하를 극적으로 줄일 수 있었습니다.
최종 성능 개선 결과
| 구분 | 기존 | 최적화 후 | 개선율 |
|---|---|---|---|
| 처리 맵 개수 | 118개 | 30-40개 | 약 68% 감소 |
| 실행 시간 | 15-23초 | 3-7초 | 약 72% 감소 |
| 서버 응답성 | 지연 발생 | 정상 응답 | 응답성 개선 |
성능 개선을 마치며: 배운 점들
이번 최적화 프로젝트를 통해 기술적인 성장뿐만 아니라 문제 해결에 대한 관점도 많이 배울 수 있었습니다.
-
측정 기반 최적화: '느리다'는 막연한 감이 아닌, 로그와 메트릭을 통해 병목 지점을 정확히 파악하고 해결하는 것이 핵심입니다.
-
단순함의 가치: 복잡한 로직을 걷어내고, 자동화된 단일 프로세스로 단순화하자 코드의 유지보수성과 확장성이 크게 향상되었습니다.
-
점진적 개선: 한 번에 모든 것을 바꾸기보다, 문제를 정의하고 단계적으로 해결하며 안정성을 유지하는 접근 방식이 효과적이었습니다.
이 글이 실제 서비스에서 발생하는 성능 문제로 고민하는 분들께 작은 도움이 되었으면 합니다. 궁금한 점이 있다면 언제든지 댓글로 남겨주세요!
