
글 개요와 소프트웨어 설계의 공통점
개요 짜기
나는 글을 쓸 때 '개요'에 신경을 많이 쓴다. 내 생각을 어떻게 전달할지 뼈대를 잡는 과정이다.
이 문장을 어디에 넣을까. 어떻게 문단을 나눌까. 어떻게 소제목을 지을까. 어떻게 논리를 다음 문단으로 연결시킬까...
개요를 짜다보면 이런 고민을 하게 된다. 되게 어렵다. 개요를 잘 짜려면 결국 읽는 사람을 생각해야하기 때문이다.
어떻게 개요를 짜야 이 글의 내용이 잘 전달되고, 공감을 이끌어낼 수 있을까?
이건 답이 없는 문제이기도 하다. 하지만 같은 내용을 쓰더라도, 어떻게 글을 구성했는지, 개요에 대해 얼마나 고민을 했는지에 따라 그 글의 힘은 천지차이로 달라진다.
나를 가장 괴롭게 하면서도, 동시에 내가 가장 좋아하고 노력하는 부분이기도 하다.

(내가 개요를 짤 때 쓰는 툴, dynalist)
소프트웨어 설계가 재미있는 이유
이런 경험이 있어서인지 나는 프로그래밍을 배우면서 자주 놀란다. '좋은 소프트웨어를 프로그래밍하는 것'과 '좋은 글을 쓰는 것'은 비슷한 부분이 정말 많다.
프로그래밍을 하게 되면 코드 그 자체를 쓰는 기술도 배워야 한다. 하지만 더 수준이 올라갈수록 중요해지는 건, 코드를 어떻게 나누고, 어떻게 배치하고, 나눈 코드들을 어떻게 조합할 것인가. 같은 질문들이다.
이런 질문을 소프트웨어 설계, 아키텍처라고 부른다. 객체지향의 원리, 디자인 패턴도 이 질문에 대한 답이다.
개인적으로 아키텍처가 개발을 하면서 배우는 여러 주제 중에 가장 재미있다. 글의 구조를 잡는 개요 짜기와 소프트웨어의 구조를 잡는 설계가 공통점이 많기 때문이다.
객체 지향도, MVC 구조도 결국에는 코드를 어떤 단위로 나누고 구조화할지에 대한 고민의 결과물이라는 걸 알았을 때, 되게 흥미로웠다.
(개요를 짤 때 흔히 배우는 게 '서론-본론-결론'인데, 이 서본결이 글쓰기의 'MVC'쯤 되지 않을까?)
글쓰기의 구조는 독자의 관점에서 글이 잘 읽히도록 고민하는 것이고, 소프트웨어의 아키텍처는 다른 프로그래머의 관점에서 코드가 잘 읽히도록 고민하는 것이다.
그래서 글쓰기의 구조에도 정답이 없듯이 설계에도 정답이 없다. 설계는 0과 1이 명확한 컴퓨터가 아니라, 인간을 위한 노하우다. 완벽한 답이 없는 아트의 영역이기도 하다.
관심사의 분리가 근본 중의 근본인 이유
설계 관련 글을 읽다보면, 입버릇처럼 계속 등장하는 말이 있다.
수많은 소프트웨어 엔지니어들이 아주 본질적이고 중요한 원칙이라면서 언급하는 단어다.
관심사의 분리 (Separataion of Concerns)
코드를 하나의 커다란 뭉텅이로 만들지 말고, 작게 쪼개서 역할을 나눠주라는 뜻이다.
(뭔가 번역투 같은 어려운 말이지만, '분업'이라고 생각하면 쉽다.)
뜻은 간단하다.
컴퓨터 공학의 대부분의 개념들이 그렇듯이, 단어 자체의 뜻보다는 이게 중요한지 이유를 알아야 한다.
관심사의 분리가 근본적이고 중요한 이유는, 소프트웨어가 복잡하기 때문이다.
요즘 우리가 쓰는 소프트웨어들은 엄청나게 복잡하다.
우리가 그냥 간단한 '쇼핑앱' 간단한 '투두앱'이라고 쉽게 생각하는 것도, 사실 뒷단을 까보면 생각보다 훨씬 많은 코드가 필요하다.
그러나 이 복잡한 소프트웨어를 다루는 프로그래머도 결국은 인간이다.
인간이 한번에 생각할 수 있는 넓이와 깊이에는 한계가 있다. 제아무리 천재 프로그래머라도 마찬가지다.
그래서 인간이 복잡한 것을 다루는 방법은, '잘 나누는 것'이다.
우리는 거대한 시스템을 우리가 다룰 수 있을만큼의 작은 크기로 나눈다. 하나씩 풀어낸 다음, 그걸 다시 잘 결합해서 복잡한 전체를 만들어낸다.
어떻게 해야 소프트웨어를 잘 나눌 수 있을까?
어떻게 하면 관심사/역할의 분리를 잘할 수 있을까?
이 질문이 소프트웨어 엔지니어링에서 근본 중의 근본 질문일 수밖에..!
'잘 나눈다'의 기준, 응집도와 결합도
그렇다면 도대체 잘 나눴다는 것의 기준은 뭘까?
소프트웨어 공학에서 '잘 나눴다'는 기준으로 '응집도'와 '결합도'가 있다.
응집도: 끼리끼리 노는 코드
응집도(Cohesion)도 영어 번역 단어라 그런지 필요 이상으로 말이 어렵다.
쉽게 풀어보면
얼마나 비슷한 코드끼리 끼리끼리 잘 모아져 있나?
라는 뜻이다.
서로 비슷비슷한 일을 하는 코드끼리, 관련이 있는 코드끼리 모아놓을수록 더 '잘 나눠진 코드'다.
'분업'에 비유해보면 비슷한 일은 최대한 한 사람이 몰아서 하는 게 효율적이다.
그래서 응집도는 높을수록 좋다.
결국 나눈다는 건, 뭉쳐있는 코드 사이에 선을 긋는 일이다. 응집도는 선을 그은 안쪽에 대한 얘기다.
결합도: 독립적인 코드
반면, 결합도(Coupling)는 선을 그은 안쪽 코드와 바깥쪽 코드가 얼마나 엮여있는지에 대한 얘기다.
코드가 얼마나 독립적인가?
특정 부분이 일을 하기 위해서 외부의 도움이 얼마나 필요한가?
자기 일을 하기 위해서 다른 코드의 도움이 덜 필요할 수록 '잘 나눠진 코드'다.
사람의 '분업'에 비유해보면, 한 사람이 하는 일이 다른 사람이 해야하는 일에 영향을 적게 받을수록 효율적이다.
그래서 결합도는 낮을수록 좋다.
하지만 결합이 없을 수는 없다. 결국 역할을 나눈 코드들이 잘 협력을 해서, 전체 시스템의 역할을 해야한다.
응집도를 높이는 게 비교적 직관적인 반면에, 결합도를 낮추는 구조는 좀 더 미묘하고 어렵다.
이 결합도를 낮춰보려는 여러 고민과 노하우가 대부분의 설계 원리와 디자인 패턴에 녹아있다.
💡 중간 요약
- 관심사의 분리가 중요한 이유는 복잡한 소프트웨어를 프로그래머가 다뤄야 하기 때문이다.
- 비슷한 코드끼리 잘 모아놓은 코드가 '잘 나눈 코드'다. 이걸 어려운 말로 응집도가 높다고 한다.
- 모아놓은 코드가 자기 일을 할 때 외부의 도움이 덜 필요할 수록 '잘 나눈 코드'다. 이걸 어려운 말로 결합도가 낮다고 한다.
관심사의 분리를 상속한 원칙들
결합도와 응집도라는 기준이 생기긴 했지만, 여전히 '관심사의 분리'는 너무 추상적이다.
결국은 잘 나눠서 결합도와 응집도를 낮추라는 건데... 결합도/응집도가 뭐 수치로 딱딱 나오는 지표도 아니고.
실전에서 와닿기에는 너무 보편적이고 추상적이다.
그래서 소프트웨어 설계에는 '관심사의 분리'랑 뜻은 거의 같지만, 좀 더 구체적으로 들어간 원칙들이 있다.
관심사의 분리를 상속받은 좀 더 구체적인 원칙들을 하나씩 살펴보도록 하자.
1. 클린 코드: 함수를 작게 나눠라
개발자들의 고전, 클린 코드에서 가장 강조하는 내용 중 하나다.
함수는 최대한 작게, 한가지 일만 하도록 할 것.
함수가 길고 복잡해지면 함수가 무슨 일을 하는지 이해하기가 어려워진다.
클린 코드에서는 함수 하나가 보통 20줄이 넘어서는 안된다고 한다.
너무 길거나, 추상화의 '단(level)'이 맞지 않는 함수는 따로 코드를 빼내서 별도의 함수로 만든다.
이렇게 하면 코드는 더 읽기 쉽고, 다시 사용하기도 좋아진다.
'함수는 작게, 한 가지 일만 하게 해라'는 가장 기초적인 구현 수준에서, 함수 단위에 '관심사의 분리'를 적용한 원칙이라고 할 수 있다.
클린 코드의 함수 챕터에 어떻게 함수를 잘 나눌지에 대한 더 구체적인 테크닉들이 있으니 참고하자.
💡 함수는 작게(Small Functions)
'20줄 이하의 한 가지 일'을 기준으로 관심사를 분리
2. 캡슐화: 공과 사를 나눠라
함수보다 조금 더 수준을 높여보면 '객체'의 세계로 오게 된다. 객체 단위에도 똑같이 관심사의 분리 원칙이 적용된다.
그 중 대표가 '캡슐화'다.
캡슐화를 내 언어로 표현하자면, 이렇다.
'공과 사'를 구분하자
공과 사를 구분해야 일을 잘한다.
객체의 '공'은 뭐지? '인터페이스'다.
다른 객체가 메시지를 보내서, 어떤 일을 해달라고 요청할 수 있는 약속이다. 다른 객체와 협력할 때 서로 잘 맞춰야 하는 부분이다. 다른 객체가 의존하고 있는 부분이기 때문에 가급적 바꿔서는 안 된다.
객체의 '사'는? '구현'이다.
내가 해주기로 한 일(공)을 하기만 한다면, 나머지는 굳이 다른 사람이 알 필요가 없다.
내가 상태를 어떻게 저장하고 있는지, 어떤 식으로 일을 해서 결과물을 주는지 같은 디테일한 구현 부분은 숨긴다.
이렇게 객체의 공과 사를 '분리'하는 걸 캡슐화라고 한다.
대부분의 객체 지향 언어는 프로퍼티나 메서드 앞에 '공(Public)'과 '사(Private)'를 구분할 수 있는 접근 제어(Access control) 기능을 제공한다.
캡슐화를 잘 해놓으면, 객체는 다른 객체에게 영향을 주지 않고 독립적으로 구현을 바꿀 수 있게 된다.
반대로 이 캡슐화가 잘 안 되면, 사적인 부분 하나가 안 맞거나 변하면 다른 객체들이 모두 삐걱거리는 참사가 일어난다.
'공적인 인터페이스'와 '사적인 구현의 분리'는, 객체 단위에서 관심사를 분리하는 황금 룰이라고 할 수 있다.

(직장에선 캡슐화가 안 되는 대한민국.jpg)
💡 캡슐화(Encapsulation)
인터페이스와 구현을 기준으로 관심사를 분리
3. 단일 책임 원칙: 변경 이유를 기준으로 나눠라.
단일 책임 원칙(Single Reponsibility Pricinple). 그 유명한 'SOLID' 5형제에서 S를 담당하고 있다.
단일 책임이라는 말 자체는 그닥 인사이트가 없다. 내 생각에 더 중요한 말은 이거다.
_1548158817.png)
A class should have one, and only one, reason to change.
-Robert C. Martin
우리 엉클 밥 형님이 말씀하시기를, 객체는 하나의 변경 이유를 가져야 한다고 한다.
다음 질문에 대한 답으로 조금 바꿔서 말해보자.
밥 형님.. 우리가 객체의 관심사를 분리하려고 하는데요. 객체의 관심사라는 걸 도대체 무슨 기준으로 나눠야 하나요?
객체를 잘 나누고 싶으냐?
그러면 '변경 이유'를 기준으로 나눠라.
-엉클 밥
이 원칙에서 엉클 밥이 주는 인사이트는, '변경 이유'다.
만약 이 소프트웨어가 잘 작동을 하다가 우리가 뭔가 기능을 변경해야한다고 가정해보라는 거다.
저장해야하는 데이터 필드가 추가되었다든가, 아니면 정렬하는 방식이 바뀐다든가. 흔히 생각할 수 있는 여러 변경의 이유들이 있다.
근데 변경하는 상황 A에도 이 객체를 바꿔야 하고, 변경하는 상황 B에도 이 객체를 바꿔야 한다?
그럼 관심사의 분리가 잘 나눠진 게 아니다. 객체가 한번에 너무 많은 일을 하고 있고, 응집도가 낮다고 볼 수 있다.
변경할 이유를 기준으로 객체를 분리해라.
(그래서 개인적으로는 '단일 책임 원칙' Single Responsiblity Principle이 아니라, '단일 변경 이유 원칙' Single Reason to change Principle이 훨씬 더 좋은 이름이라고 생각한다.)
(사실 SOLID 5형제 이름 다 마음에 안 든다. 밥 형보다 뛰어난 엔지니어가 되어서 다 바꿔버리고 싶다.)
💡 단일 책임 원칙(SRP)
'변경할 이유'를 기준으로 관심사를 분리
4. 인터페이스 분리 원칙: 사용하는 객체 기준으로 나눠라
위에서 '인터페이스'를 언급했다.
인터페이스란 다른 객체들이 해당 객체에게 메시지를 보내서 요청할 수 있는 작업들을 뜻한다.
메시지를 보내는 객체(클라이언트)는 이 인터페이스에 의존을 하게 된다.
여기서 하나 설명해야할 부분이 있다. 객체 지향에서 중요한 또 하나의 테크닉이 다.
인터페이스를 별도의 추상 클래스나, 혹은 프로토콜로 정의하는 것이다. (= 의존성 역전 원칙)
메시지를 보내는 객체(클라이언트)도 인터페이스를 나타내는 추상 클래스/프로토콜에 의존하고,
메시지를 처리하는 객체도 인터페이스를 나타내는 추상 클래스/프로토콜에 의존하게 만든다.
이렇게 하면 인터페이스를 사용하는 객체 입장에서 구체적인 객체를 알 필요가 없다. 코드의 결합도가 낮아진다.
비유하자면 충전기가 USB-C라는 규격만 따르면, 자기가 충전하는 기기가 스마트폰이든 태블릿이든 알바 아니게 되는 상황을 만들 수 있다.
자, 그럼 인터페이스는 여러가지 메서드들로 이뤄져있을 텐데, 이 메서드를 '어디까지 하나로 인터페이스로 묶고, 어디까지 다른 인터페이스로 나눌 것이냐?' 하는 문제도 생기게 된다.
서로 다른 관심사를 가진 인터페이스라면, (하나는 충전을 위한 인터페이스고 하나는 오디오를 위한 인터페이스 같이) 어느 수준에서는 분리해줘야 한다.
그래서 나온 원칙이 인터페이스 분리 원칙이다.
밥 형님.. 우리가 인터페이스를 나누려고 하는데요. 인터페이스의 관심사를 도대체 무슨 기준으로 나눠야 하나요?

인터페이스를 잘 나누고 싶으냐?
그러면 '클라이언트' 기준으로 나눠라.
-엉클 밥
예를 들어, 스마트폰 객체가 있다고 하자.
이 스마트폰을 사용하는 클라이언트는 '유선 이어폰' '무선 이어폰' '충전기' 등이 있다.
인터페이스를 '스마트폰'으로 추상화하고, 스마트폰을 따르는 갤럭시, 아이폰 등의 구체 클래스가 있다.
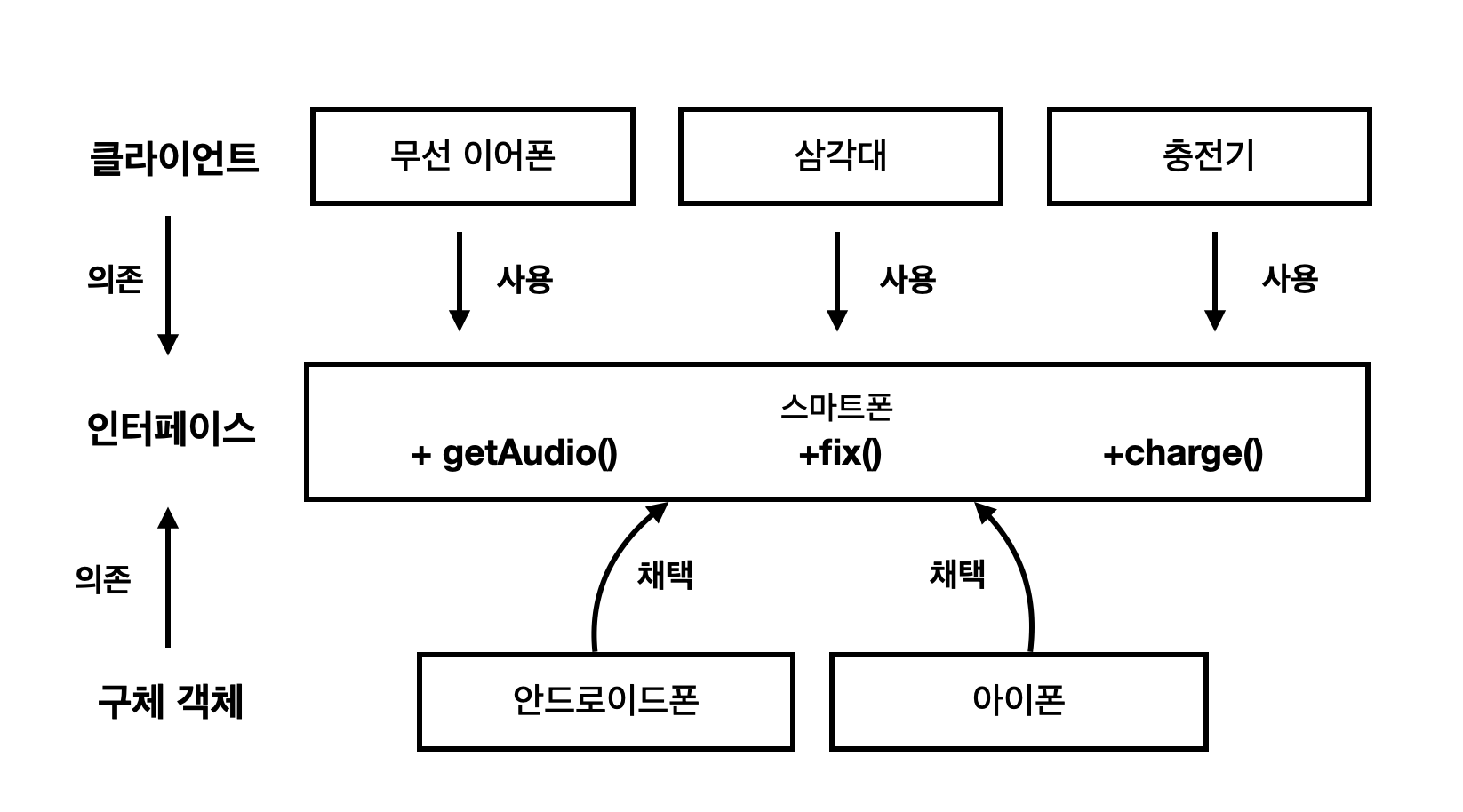
그런데, 이어폰은 충전 인터페이스(charge)를 사용하지 않고, 충전기는 오디오 인터페이스(getAudio)를 사용하지 않는다.
클라이언트 기준으로 나눠라. 라는 말은, 클라이언트 사용하는 메시지 외에 다른 메시지가 인터페이스에 들어있지 않도록 나눠주라는 말이다.
이어폰, 삼각대, 충전기라는 클라이언트 기준으로 인터페이스를 분리해준다.
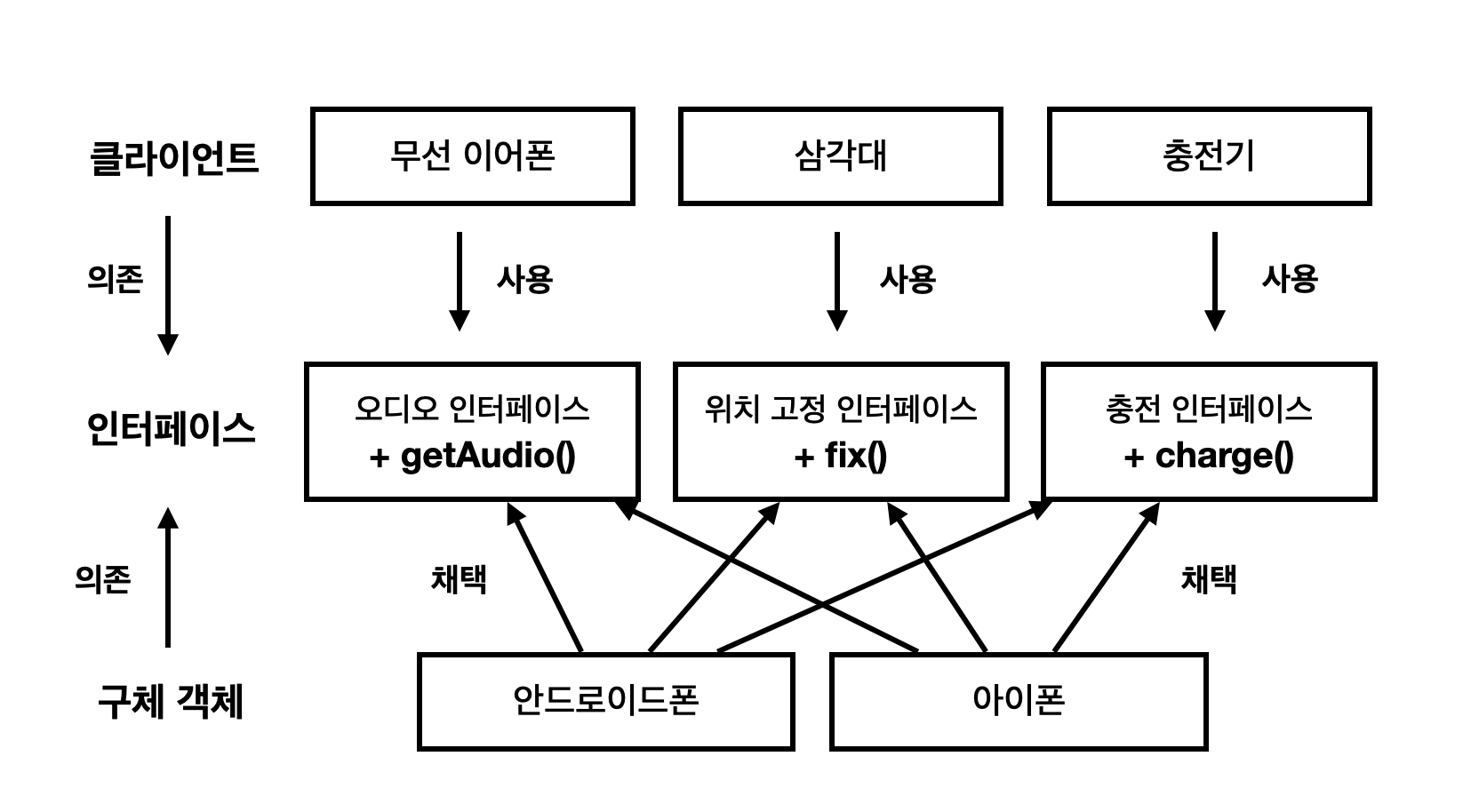
인터페이스의 관심사는 메시지를 보내는 쪽, '클라이언트'다.
그러니 인터페이스에서 관심사를 분리할 때는 클라이언트가 필요한 인터페이스만 쓸 수 있도록 분리하자.
💡 인터페이스 분리 원칙(ISP)
'클라이언트가 사용하는 범위'를 기준으로 관심사를 분리
5. MV?? 패턴 (MVC, MVP, MVVM): UI와 비즈니스 로직은 나눠라
이제 객체 단위가 아니라, 조금 더 큰 서브시스템/레이어 단위로 올라와보자.
오래 전 GUI가 등장하면서 개발자들은, GUI와 데이터/로직이 굉장히 다른 특성과 변경 주기를 갖고 있다는 사실을 자연스럽게 알게 됐다.
그래서 UI(View)와 비즈니스 로직(Model)을 분리하는 구조가 등장하게 되는데, 이게 바로 MVC의 시작이다.
(이 내용에 대해서는 이전 글에서 설명했으므로 간단하게 넘어가도록 하자.)
소프트웨어의 관심사를 'UI'와 '비즈니스 로직'으로 나누자는 것은 너무 효과적이어서 거의 소프트웨어 개발에서는 국룰이 되었다.
특히 현업에서 UI는 굉장히 자주 바뀌는 부분이기 때문에, 다른 부분과 잘 분리해두는 게 정말 중요하다.
그리하여 후대의 개발자들은 UI와 비즈니스 로직을 분리하는 방법론을 거의 묻지도 따지지도 않고 배우게 된다.
이런 방법론들이 바로 MVC, MVP, MVVM 등.. 패턴/아키텍처라고 불리는 녀석들이다. 다들 한번쯤은 들어봤을 것이다.

각각의 패턴은 각각 UI와 비즈니스 로직을 어떻게 하면 더 잘 나눌까에 대한 서로 다른 견해와 해석을 반영한 결과물이다.
다만 주의해야할 점은 'MVC'라고 해서 개발자들이 모두 같은 걸 떠올리지는 않는다는 점이다. 플랫폼이나 개발자마다 각자 생각하는 MVC는 미묘하게 다를 수 있다.
하지만 이 패턴들은 결국 'UI와 비즈니스 로직으로 관심사를 나누고 싶은데, 어떻게 하면 잘 나눴다고 소문이 날까?'라는 질문에서 시작되었다는 공통점이 있다.
💡 MV?? 패턴
'UI'와'비즈니스 로직'을 기준으로 관심사를 분리
6. 레포지토리 패턴: 비즈니스 로직과 데이터 접근을 나눠라
UI와 비즈니스 로직의 분리 외에, 또 한가지 레이어 단 분리를 알아보자.
흔히 모델 안에 같이 들어있는, '비즈니스 로직'과 '데이터 접근'을 분리하는 것이다.
여기서 데이터 접근이란, 외부 서버에 HTTP 요청을 보내거나 로컬 데이터베이스에 쿼리를 보내는 걸 의미한다.
각각을 네트워킹 레이어(Networking Layer), 퍼시스턴스 레이어(Persistence Layer)라고 부르기도 한다.
프로세스 외부에서 데이터를 가져오는 코드와 내부 로직을 처리하는 코드는 특성도 다르고 변경의 주기도 굉장히 다르다.
특히 응답이나 요청해야하는 포맷이 바뀌었을 때, 매번 로직 코드를 바꿔야 한다면 무척 괴로울 것이다.
그래서 UI와 비즈니스 로직을 분리하듯이, 비즈니스 로직과 데이터 접근도 분리하자! 라는 아이디어가 나왔고.
대표적인 방법이 '레포지토리 패턴(Repository Pattern)'이다.
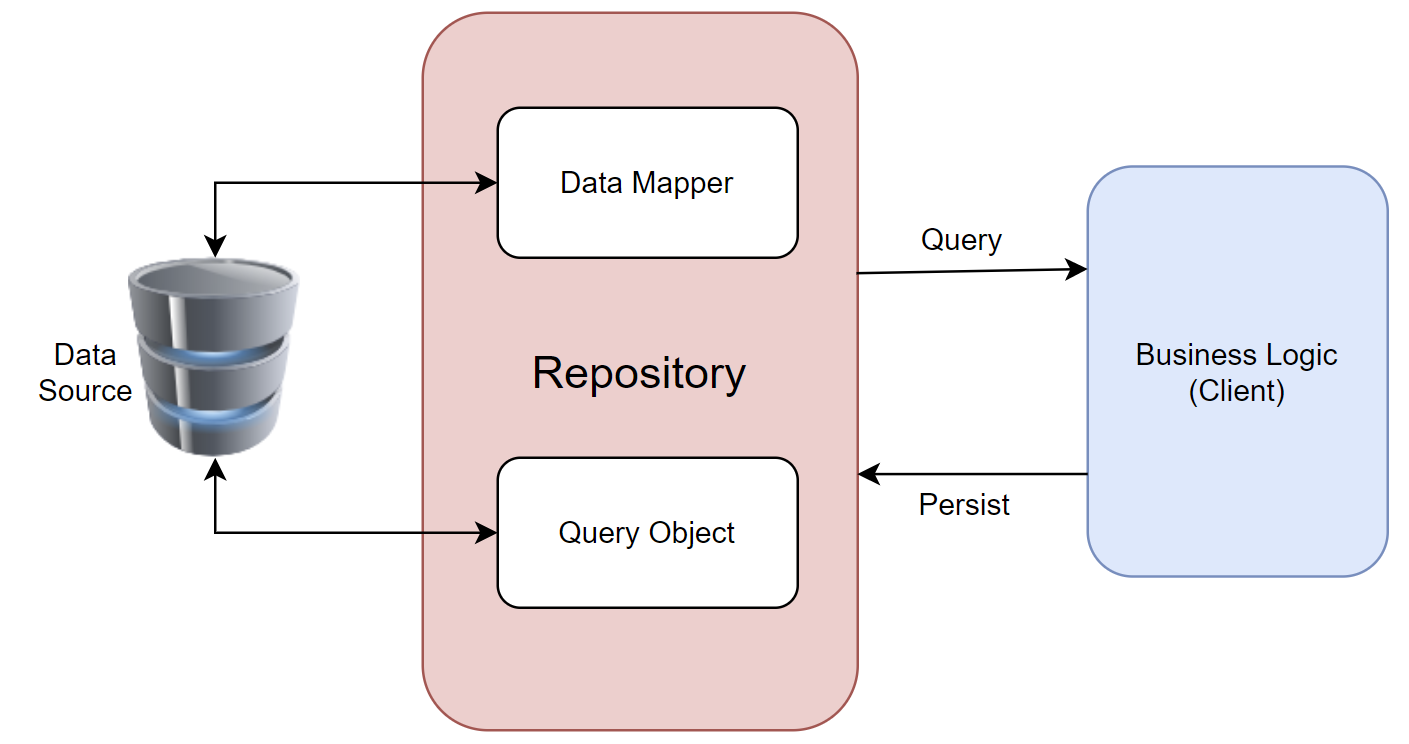
데이터 출처와 비즈니스 로직 사이에 레포지토리라는 새로운 레이어를 하나 만들고, 이 레이어에서 데이터 접근을 모두 처리하도록 한다.
비즈니스 로직이 필요한 데이터를 가져와야할 때, 데이터가 어디서 오는지는 전혀 모른 채 레포지토리에 요청을 보낸다.
레포지토리가 데이터 출처(Source)에 쿼리나 요청을 날려서 데이터를 받아서 전달해준다.
흔히 '모델'로 퉁쳐서 묶여있던 비즈니스 로직과 데이터 출처 간의 결합도가 낮아지면서 서로의 관심사를 더 명확하게 분리할 수 있다.
💡 레포지토리 패턴(Repository Pattern)
'비즈니스 로직'과 데이터 접근'으로 관심사를 분리
7. 레이어 간 의존성 규칙: 의존성은 한쪽으로만 생기도록 나눠라
전체 시스템을 여러 레이어로 나눌 때 자주 보게 되는 원칙이 있다. 바로 의존성 규칙(Dependency Rule)이다.
이것 역시 레이어 수준에서 관심사의 분리를 통해 코드의 결합도를 낮추는 방법이다.
The overriding rule that makes this architecture work is The Dependency Rule. This rule says that source code dependencies can only point inwards. Nothing in an inner circle can know anything at all about something in an outer circle.
-Robert C. Martin
나눠놓은 레이어를 바깥쪽(상위) 레이어부터, 안쪽(하위) 레이어까지 계층 구조로 만든다.
예를 들어, 총 4개의 레이어로 시스템을 나눴다고 해보자.
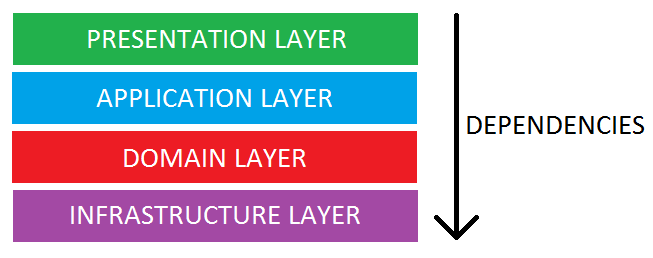
이 때 중요한 점은, 안쪽 레이어는 바깥쪽 레이어에 대해서 전혀 몰라야 한다.
가장 밑에 있는 인프라 레이어는, 누군가 시키면 오직 백엔드 서버와 커뮤니케이션만 할뿐, 나머지 시스템에 대해서는 전혀 모른다.
도메인 레이어는 이 네트워크를 알고 요청을 보내서 업데이트하지만, 애플리케이션 레이어가 자신을 어떻게 사용하는지 전혀 모른다.
애플리케이션 레이어는 비즈니스 로직을 알고 도메인 모델을 관리하지만, 이걸 사용자한테 어떻게 보여주는지는 전혀 모른다.
프레젠테이션 레이어는, 사용자 인터랙션을 인지하고 애플리케이션 레이어의 API를 사용하지만, 하위에 있는 인프라나 도메인에서는 전혀 모른다.
이렇게 층층이 떡으로 분리를 해놓은 다음, 자기 바로 아래 레이어에만 의존하도록 만드는 걸 '의존성 규칙'이라고 한다.
의존성의 방향을 한쪽으로 통일해서, 역할을 명확하게 분리하고, 코드의 결합도를 낮춘다.
💡 의존성 규칙(Dependency Rule)
'더 안쪽 레이어에만 의존하도록' 관심사를 분리한다.
변하지 않는 원칙
내 부족한 지식으로 알고 있는 범위 내에서, 관심사를 분리하는 구체적인 원칙을 알아보았다.
사실 모든 방법론과 개념을 알려면 평생 공부해도 모자랄 것이다. 게다가 계속해서 새로운 키워드와 프레임워크들이 등장하고 있으니까.
어쩌면 우리도 관심사를 좀 분리할 필요가 있는 거 같다. 변화하는 키워드와 개념, 그리고 변하지 않는 근본 원칙으로.
나는 관심사를 나눠서, 밑에 깔려있는 변하지 않는 근본 원칙을 먼저 배우고 싶다.
아마 '관심사의 분리'는 앞으로도 계속 근본 원칙으로 남아있을 것이다. 관심사의 분리는 컴퓨터가 아닌, 프로그래머(인간)를 위한 원칙이기 때문이다.
기술은 빠르게 바뀌지만, 인간 자체는 그렇게 빠르게 바뀌지 않는다.
개발자 친화적 프로그래밍
관심사의 분리가 왜 중요한가?
왜 끼리끼리 모여있는 (응집도가 높은) 코드가 좋고,
왜 서로 독립적인 (결합도가 낮은) 코드가 좋은가?
이 질문에 대해서 다시 한번 대답해보자면, 그게 '개발자 친화적인 코드'를 만들기 때문이다.
인간의 뇌는 한번에 하나씩밖에 처리하지 못한다.
우리는 여러가지를 한꺼번에 생각하고 다루지 못한다. 한번에 하나씩 생각하고 일을 해야 한다.
즉, 한 번에 벽돌 하나씩만 올릴 수 있다.
그러니 우리가 수월하게 일을 하려면, 우리가 신경써야하는 범위가 작아야 한다. 그 외를 신경쓰지 못해도 다른 부분이 무너질 위험이 없어야 한다.
지금 내가 신경쓰는 벽돌만 올리고, 그 벽돌이 다른 벽돌에는 영향을 주지 않아야 맘 놓고 작업을 할 수 있다.
관심사의 분리는 개발자가 한번에 벽돌 하나씩만 올릴 수 있게 해준다.
인간은 잘 묶여있는 덩어리(Chunk)를 더 잘 기억한다.
조지 밀러의 아주 유명한 연구에 따르면 뇌의 기억 용량은 최대 5-7개의 덩어리밖에 기억하지 못한다.
하지만 어떤 정보를 의미있는 정보로 묶는다면, 하나의 덩어리가 되어 기억 공간은 하나만 차지하게 된다. 그래서 청킹을 잘하면 인간의 정보 처리 능력이 높아진다.
'abkq mrip basr'라는 단어는 덩어리를 만들 수 없기 때문에 기억하기가 힘들다.
하지만 'apple loves iphone' 같은 단어는 훨씬 더 쉽게 기억할 수 있다. 우리가 여러 문자를 한 단위로 묶을 수 있기 때문이다.
유사한 의미를 지닌 코드들을, 끼리끼리 잘 묶어서 추상화한다면, 코드를 이해하기가 훨씬 더 쉬워진다.
협업과 의사소통은 비싸다
소프트웨어는 협업의 결과물이다. 근데 이 협업이라는 게 쉽지가 않다.
우리는 다른 사람들이 내가 보는 것과 같은 것을 보고, 내가 떠올리는 것과 같은 것을 떠올린다고 생각하지만 실제로는 그렇지 않다.
우리는 각자의 뇌가 해석한 세상을 보기 때문이다. 같은 사진을 보고도 어떤 사람은 파랑/검정으로 볼 수도 있고, 흰색/금색으로 볼수도 있다.
의사소통이 이렇게나 어려운데, 하나의 작업에 관여하는 사람이 많아질 수록 의사소통의 건수는 기하급수적으로 늘어난다.
자연스럽게 일의 효율은 줄어든다. 제프 베조스는 이것 때문에 '커뮤니케이션은 끔찍하다'면서 피자 두판 법칙이라는 걸 내놓기도 했다.
효율적인 협업은, 가급적이면 소통이 필요없는 구조를 만드는 것이다.
'잘 나눠진 코드'는 커뮤니케이션 비용을 아껴준다.
최근 큰 IT회사들이 '마이크로서비스' 구조를 도입하는 것도 이것과 맞닿아있다. 팀과 서비스를 작게 나눠서 의사소통과 변경의 비용을 줄이는 것이다.
개선하기 쉬운 소프트웨어
개발자도 한 명의 인간이다. 인간이 가진 고유한 한계를 극복하기 위해서, '관심사의 분리'가 필요하다. 한번에 하나씩만 걱정할 수 있도록.
확실한 것 하나는, 소프트웨어는 한 번 만들고 끝이 날 수 없다.
소프트웨어는 결국 고객 가치를 전달하기 위한 도구고, 끊임없이 새로운 요구사항에 대응을 해줘야 한다.
좋은 소프트웨어를 만들려면 끊임없이 개선해야 한다.
개발자가 고치기 쉬운 코드가 곧 좋은 코드다.
잘 나눠서, 프로그래머가 개선하기 쉽도록 만드는 것. 그게 '관심사의 분리'가 중요한 이유다.
요약 정리
소프트웨어 설계와 관심사의 분리
- 관심사의 분리가 중요한 이유는 복잡한 소프트웨어를 프로그래머가 다뤄야 하기 때문이다.
- 비슷한 코드끼리 잘 모아놓은 코드가 '잘 나눈 코드'다. 이걸 어려운 말로 응집도가 높다고 한다.
- 모아놓은 코드가 자기 일을 할 때 외부의 도움이 덜 필요할 수록 '잘 나눈 코드'다. 이걸 어려운 말로 결합도가 높다고 한다.
관심사의 분리를 상속한 원칙들
-
작은 함수(Small Functions)
'20줄 이하의 한 가지 일'을 기준으로 관심사를 분리 -
캡슐화(Encapsulation)
인터페이스와 구현을 기준으로 관심사를 분리 -
단일 책임 원칙(SRP)
'변경할 이유'를 기준으로 관심사를 분리 -
MVC/MVP/MVVM 패턴
'UI'와'비즈니스 로직'을 기준으로 관심사를 분리 -
인터페이스 분리 원칙(ISP)
'클라이언트가 사용하는 범위'를 기준으로 관심사를 분리 -
레포지토리 패턴(Repository Pattern)
'비즈니스 로직'과 데이터 접근'으로 관심사를 분리 -
의존성 규칙(Dependency Rule)
'더 안쪽 레이어에만 의존하도록' 관심사를 분리한다.
관심사의 분리가 개발자 친화적인 이유
- 인간의 뇌는 한번에 하나씩밖에 처리하지 못한다.
- 인간은 잘 묶여있는 덩어리(Chunk)를 더 잘 기억한다.
- 협업과 의사소통은 비싸다
참조 링크
🔗 Wikipedia, Separation of Concerns
🔗 How do you explain Separation of Concerns to others?
🔗 Alexey Naumov, Separation of Concerns in Software Design
🔗 Hayim Makabee, Separation of Concerns
🔗 Separation of Concerns
🔗 관심사의 분리(Separation of Concerns)
🔗 Programming Fundamentals Part 5: Separation of Concerns(Software Architecture)

13개의 댓글

... 대표적인 방법이 '레포지토리 패턴(Repository Pattern)'이다.
알고는 있었던 건데 이걸 이렇게 부르는 군요! 좋은 키워드 하나 알아갑니다. 감사합니다. :)



이 문제를 해결하려면 소프트웨어 설계에서의 '관심사의 분리' 원칙을 고려해야 합니다. 마치 https://boitinhyeu.net.vn/ 이 사랑 계산기를 제공하듯, 각 코드의 책임을 명확히 분리하고, 역할에 따라 응집도와 결합도를 잘 관리하는 것이 중요합니다. 예를 들어, UI와 비즈니스 로직을 분리하는 MVC 패턴처럼, 각 부분을 독립적으로 처리하면 유지보수와 확장성 측면에서 효율적인 결과를 얻을 수 있습니다. 각 기능에 대한 변경 이유를 기준으로 책임을 분리하는 것이 잘 나눠진 설계의 핵심입니다.
관심사의 분리로 다양한 예시들 재밌게 보고 갑니다.
따로따로 공부하면 복잡했을 개념들인데, 좋은 글 감사합니다. 🙏