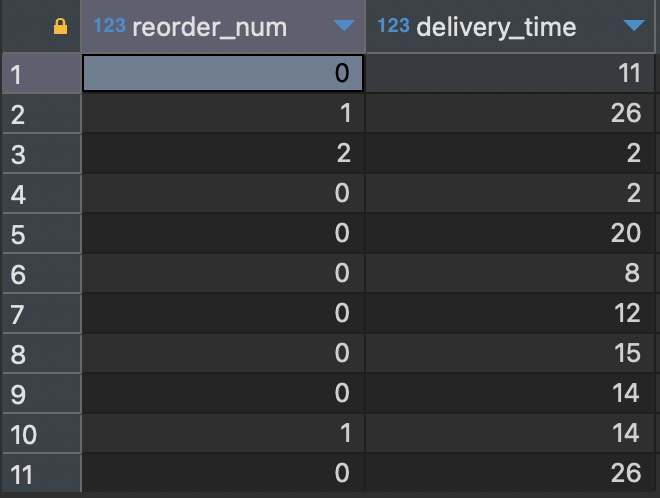
상관분석을 위한 파일 제작 코드(SQL)
#order3
SELECT
o.order_id,
c.customer_id,
c.age,
CASE
WHEN c.gender = 'Female' THEN 0
WHEN c.gender = 'Male' THEN 1
WHEN c.gender = 'Bigender' THEN 2
WHEN c.gender = 'Polygender' THEN 3
WHEN c.gender = 'Agender' THEN 4
WHEN c.gender = 'Genderfluid' THEN 5
WHEN c.gender = 'Genderqueer' THEN 6
ELSE 7
END as num_gender,
DATEDIFF(o.delivery_date, o.order_date) as delivery_time,
o.payment,
CASE
WHEN COUNT(o.order_id) OVER (PARTITION BY c.customer_id) = 1 THEN 0
ELSE 1
END as reorder
FROM
orders o
INNER JOIN
customers c ON o.customer_id = c.customer_id
ORDER BY
o.customer_id;
재주문과 연관된 요인 상관분석(Python)
!pip install pandas matplotlib seaborn
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
order3 = pd.read_table('/content/_order3.csv',sep=',')
order3.head()
print(order3.isnull().sum())
order3 = order3.dropna()
corr=order3.corr(method='pearson')
corr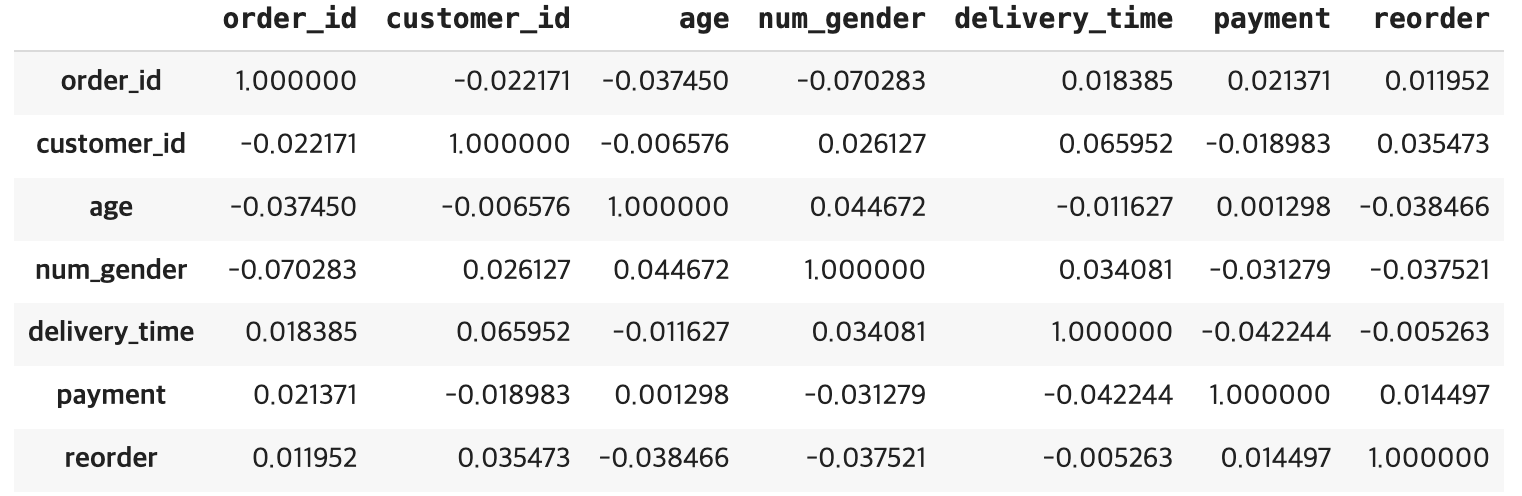
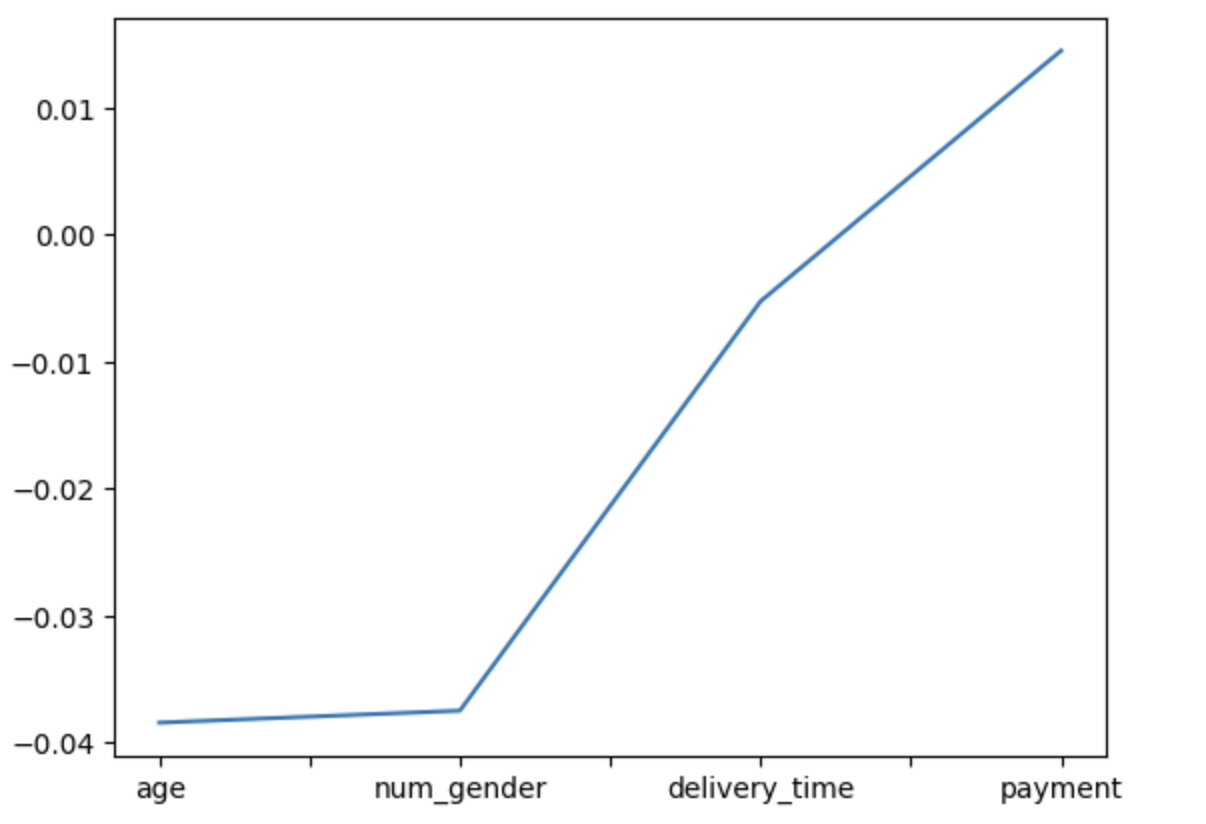
order_id, customer_id 제외 그래프
선형회귀를 위한 파일 코드(SQL)
#주문횟수에 따른 고유번호와 배달기간
SELECT *
FROM orders o
order by customer_id
WITH RankedOrders AS (
SELECT
order_id,
customer_id,
payment,
order_date,
delivery_date,
ROW_NUMBER() OVER (PARTITION BY customer_id ORDER BY order_date) - 1 as reorder_num,
DATEDIFF(delivery_date, order_date) as delivery_time
FROM
orders
)
SELECT
reorder_num,
delivery_time
FROM
RankedOrders
ORDER BY
customer_id, order_date;
선형회귀분석(Python)
from sklearn.linear_model import LinearRegression
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv("/content/ordernum_deliverytine.csv")
df.head()
X = df["delivery_time"]
y = df["reorder_num"]
plt.plot(X, y, 'o')
plt.show()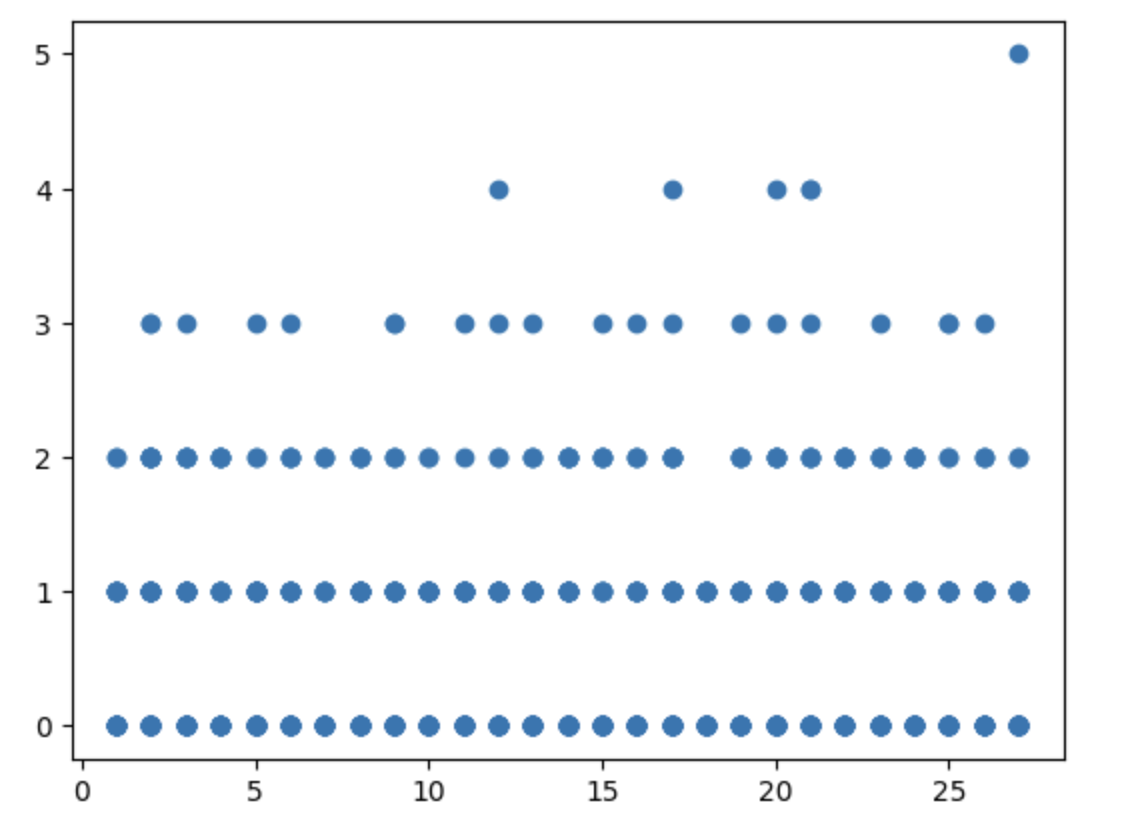
데이터 전처리를 비롯한 분석 진행은 나쁘지 않은데, 가설이 기각된 후 막혔다.
EDA를 통한 마케팅 방안을 찾아보려고 했으나 기준(지표)이 명확하지 않아 우리가 작성한 후반 내용과 기준에 해당되는 새로운 분석을 어떻게 찾을지도, 어떻게 연결할지도 잘 모르겠다.

Data Analysis / 맨 땅에 헤딩