중간 발표할 생각에 아득해져서 대본 쓰기 전 프로세스 정리
- 프로젝트 개요 :
- 채용 공고 데이터를 활용한 분석을 통해 전반적인 채용 트렌드를 확인한다.
- 공고 내 상세 페이지의 텍스트를 분석해 취업에 필요한 스킬을 정량화한다.
- 개인에게 적합한 채용공고를 추천하는 개인 맞춤형 추천 알고리즘을 개발한다.
- 목표 설정 :
- LLM을 활용하여 채용 공고와 현업 커뮤니티의 텍스트 데이터를 분석하여 직무별 역량을 정량화.
- 머신러닝과 딥러닝 기법을 활용한 개인 맞춤형 채용공고 추천 시스템 구축.
- 문제 정의 :
- “데이터 분야의 취업을 위한 개인 맞춤형 채용공고 추천 알고리즘 개발”
- 데이터 직군의 수요가 늘어남에 비해 구직자들은 자신에게 맞는 채용공고를 찾기 어려워 함
- 데이터 수집 :
1. 캐글 ‘Data Analyst’ 채용 공고 데이터
2. ‘Glassdoor’ 내 데이터 직군 채용 공고 데이터
3. 국내 채용공고 사이트(잡코리아, 사람인, 워크넷, 원티드 등) 내 데이터 직군 채용 공고 - 데이터 전처리 :
- 'Job Description’ : NLTK, Pandas 활용하여 스킬 키워드 추출
- ‘Salary Estimate’ : 범주형 데이터를 Min,Max,Average 값으로 나누어 컬럼 생성
- ‘Industry’ : 연관성 높은 산업군끼리 분류하여 카테고리화
- 'Job Description’ : NLTK, Pandas 활용하여 스킬 키워드 추출
- EDA
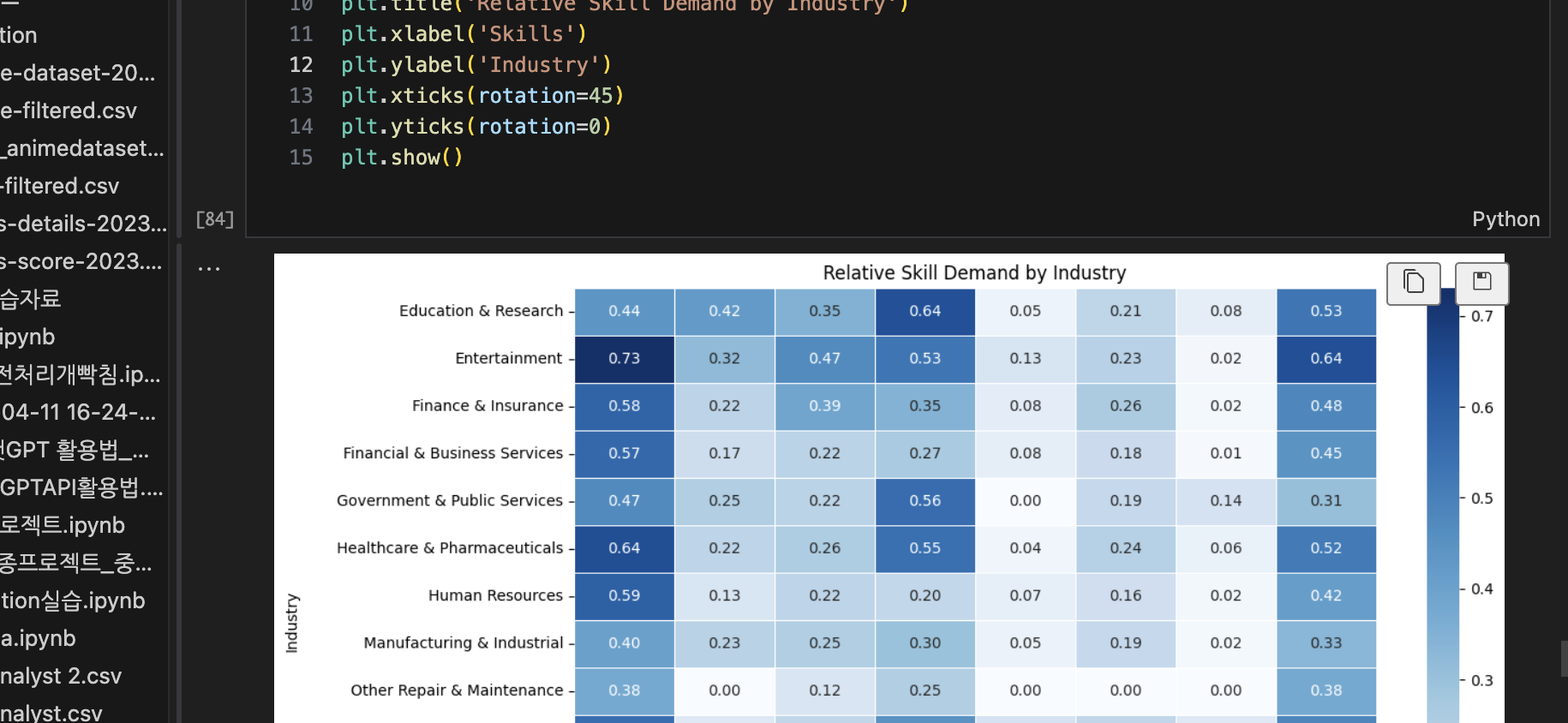
- 도메인 별 채용공고 수, 평균 연봉, 요구 스킬 분석
- 기업 규모 별 채용공고 수, 평균 연봉, 요구 스킬 분석
- 주니어와 시니어 직군 별 연봉 차이
- DA, DS, DE 직군별 채용공고 수, 평균 연봉
- 직군별 요구 스킬 분석
- 가설과 검증(분석) 방법
- 연봉에 영향을 미치는 요인 분석
- 가설: 산업군(Industry_New), 규모(Size), 경력 요구사항(Skill List), 회사 평점(Rating)이 연봉에 영향을 미칠 것이다.
- 검증(분석) 방법: 선형 회귀 분석 또는 머신 러닝 모델을 사용하여 연봉을 예측하고, 각 요인의 중요도를 파악
- 채용 포지션에 따른 연봉 차이 분석
- 가설: 데이터 과학자와 데이터 엔지니어 등의 포지션에는 연봉 차이가 있을 것이다.
- 검증(분석) 방법: 각 포지션의 연봉 분포를 시각화하고, 포지션 간 연봉 차이를 통계적으로 검증
- 스킬 간 연관성 분석
- 가설 : 'Python을 요구하는 회사는 모델링 능력도 요구할 것이다.'
- 검증(분석) 방법 :
- 텍스트 기반 유사도 분석 : TF-IDF(Term Frequency-Inverse Document Frequency) 기법을 사용하여 각 단어의 상대적인 중요도를 계산, Python과 Modeling의 TF-IDF 점수를 비교하여 양 또는 음의 상관 관계를 파악.
- LLM을 활용한 채용 공고 데이터 정량화
- 키워드 추출 : LLM을 사용하여 채용 공고에서 특정 기술 스킬이나 역량과 관련된 키워드를 추출. (Python, SQL, 머신러닝, 딥러닝 등과 같은 기술 스킬을 식별)
- 스킬 요구 수준 분석 : LLM을 통해 스킬 요구 사항의 수준 분석. 고급, 중급, 초급과 같은 수준을 나타내는 표현을 인식하여 스킬 요구 수준에 대한 정보를 척도로 정량화.
- 산업 및 업무 분류 : 채용 공고에서 언급되는 업종이나 업무 분야를 파악하여 공고가 속한 산업이나 업무 분야를 분류.
- 요구 스킬의 상호 관계 분석 : 채용 공고에서 요구되는 다양한 스킬 간의 상호 관계 분석. 예를 들어, Python과 머신러닝이 함께 요구되는 경우가 많다면 이를 인식하여 상관 관계 분석.
- 모델링
- 코사인 유사도를 활용한 추천 알고리즘 개발
- 스킬 데이터를 이용해 코사인 유사도를 계산하여 특정 공고와 유사한 공고를 추천하는 로직을 완성.
- 1,0으로 라벨링한 스킬 데이터로 유사도를 측정, A 공고와 가장 유사한 공고 5개를 출력.
= 6개의 공고 모두 요구하는 스킬 또한 같은 것을 확인 가능.
- 추후 프로젝트 진행 상황
- 국내외 추가 데이터 수집
- LLM 활용 확대
- 필터링 활용한 추천 시스템

Data Analysis / 맨 땅에 헤딩